
Python Asyncio 之网络编程方法详解
前记
Python Asyncio不仅提供了简单的Socket接口,还基于Asyncio.Socket提供了Protocol&Transport接口以及更高级的Stream接口,这些接口大大的减轻了开发者进行网络编程的心理负担。
本文主要介绍了Asyncio这些接口的简单使用以及对应的原理分析。
1.简单介绍
Python Asyncio提供了一套完整的高性能网络编程接口,它包括了兼容位于网络编程最底层的Socket–Asyncio.Socket,以及在Asyncio.Socket上层封装的Protocol&Transport接口,还有在Protocol&Transport上层封装的Stream接口。
这三套接口各有特色,开发者可以根据自己的需求选择其中一套接口来使用,进而减少网络编程的一些心理负担。
Python Asyncio三套接口的关系就跟套娃一样,Stream 套在Protocol&Transport上面 ,而Protocol&Transport套在Socket上面,由于Stream是最上层的封装,所以它的易用性最高,不过适用范围最少,其次是Protocol&Transport,最后是Socket,它的易用性最差,但是适用范围最广,不过它们的性能却跟套娃顺序无关。
根据uvloop的性能比较得出他们的性能关系为Protocol&Transport > Stream > Socket,具体结果如图:
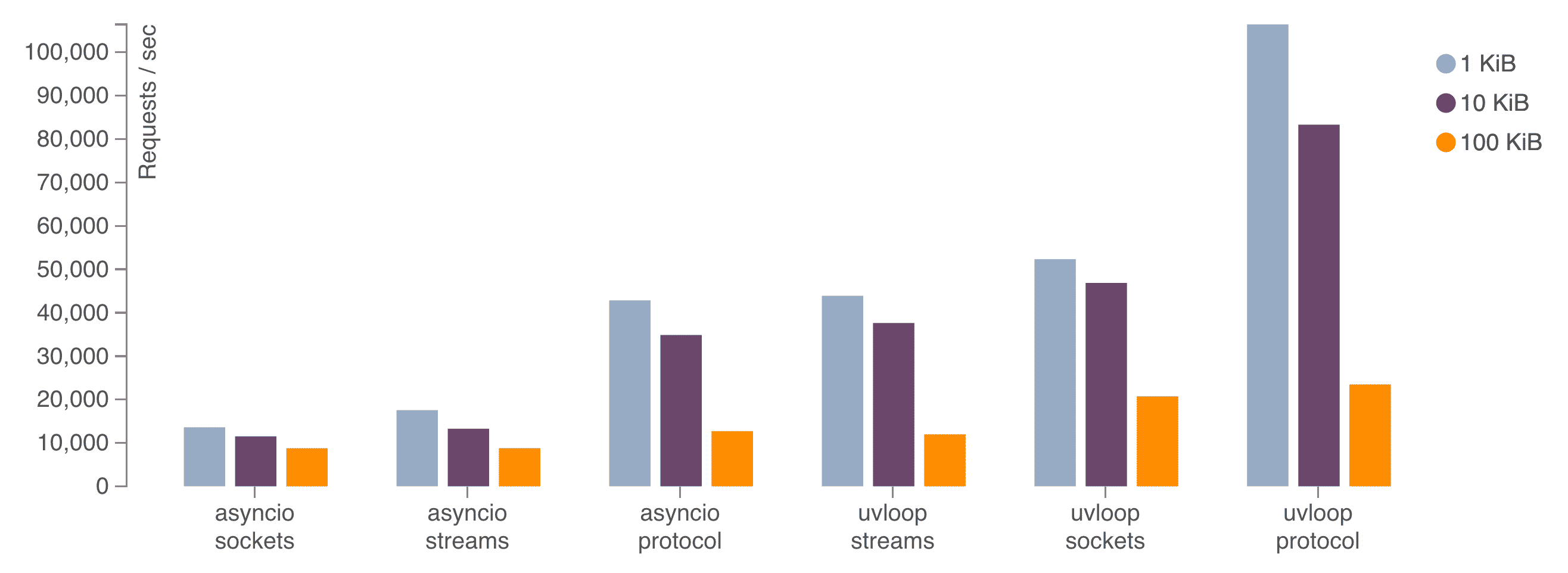
在第一次见到这个性能的比较结果时我觉得是非常神奇的,因为对于一些分层架构来说,越上层的封装越多,易用性越好,而性能反而越低,但在性能比较结果中性能最好的却是处于中间的Protocol&Transport,然后是Stream,最后才是Asycnio Socket。为了了解这个原因,需要通过网络编程接口的使用方法和源码一起分析。
1.1.Socket的简单介绍
无论Asyncio的网络编程接口是怎么封装,如果要了解它是怎么实现的,那么需要对Socket有一定的了解。
不过本文只对Socket进行简单的介绍,并不会对Socket的原理进行详细的描述,同时Python Asyncio的Stream接口只支持流传输,所以本文只采用Socket进行TCP传输的编程实例进行讲述,其他的编程方式和Socket介绍见下文:
Socket是计算机之间进行通信的一种协议,通过Socket开发者可以在无需关心底层是如何实现的情况下在不同的计算机进行端到端之间的通信,Socket常见的交互流程如下图: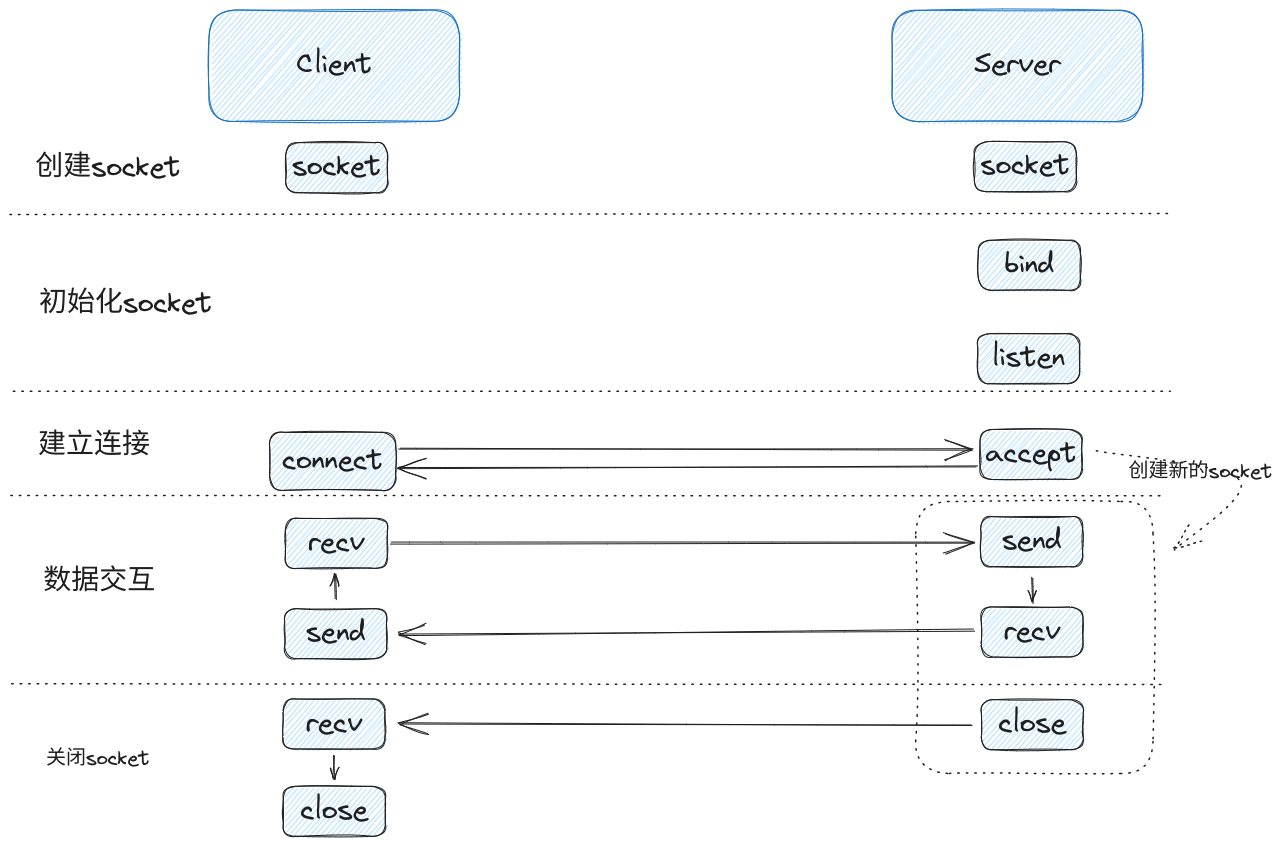 1692807503149asyncio网络编程-socket.png
1692807503149asyncio网络编程-socket.png
在交互的流程的示例图中,Socket分为五个交互阶段,每个阶段的作用如下:
- 创建
Socket: 初始化一个Socket对象。 - 初始化
Socket: 客户端无需任何操作,而服务端的Socket在初始化时比客户端的Socket多了两个方法–bind和listen,它们的作用分别是绑定一个端口,以及监听这个端口建立的新连接。 - 建立连接: 客户端
Socket的专属方法为connect,这个方法会直接与服务端建立连接。而服务端的专属方法为accept,accept这个方法比较特殊,因为其他socket的方法都是针对于socket进行操作,而accept方法除了针对socket进行操作外还会额外返回一个新的socket。
同时服务端原先的socket只携带服务端的IP和地址信息,而新的socket携带的是客户端与服务端两个端点的四元组信息(客户端IP,客户端端口,服务端IP,服务端端口)。
这一点是非常重要的,因为这两个socket对应的文件描述符是不一样的,它们的责任也是不一样的,
原来的socket只用于跟客户端建立新的连接,而新的socket用于客户端与服务端进行数据交互,这意味着服务端的事件循环在处理的时候,对两个socket的读事件的触发时机也是不一样的。其中服务端原先socket的读事件被触发时意味着有新的连接可以被accept,而新socket的读事件被触发则是代表当前连接有新的数据可以被接收,这与客户端的Socket读事件的一样的,这意味着在Socket建立成功后,客户端和服务端的连接的读写逻辑都可以统一,不用进行区分了。 - 数据交互阶段:由于服务端
accept方法返回的Socket与客户端的类似,所以这个阶段的客户端与服务端的逻辑是类似的,不过双端程序的数据只是与各自的Socket进行交互,而不是直接进行交互的。因为每个Socket都维护着读和写两个缓冲区,缓冲区的底层数据结构与队列类似,创建Socket的程序只能把数据投递到缓冲区或者从缓冲区获取数据,而无法触碰到网卡发送/接收数据的领域。
这也意味着在把Socket设置为非阻塞的情况下,当Socket的写缓冲区不满时,Socket的写操作是不会阻塞的,同样当Socket的读缓冲区拥有的量大于Socket读方法需要的量时,读操作也是不会阻塞的。 - 关闭阶段:由于
Socket有两个缓冲区,所以关闭阶段分为close和shutdowm两个方法,其中close为关闭两个缓冲区,而shuwdown可以关闭指定的缓冲区(详细的流程见后文)。示例中的例子是服务端先调用了close方法,然后服务端会发送一个EOF事件给客户端,客户端从读缓冲区读到EOF事件后发现读通道已经关闭了,才调用close方法把整个socket一起关闭。
2.Asyncio Socket
在文章《初识Python协程的实现》中介绍了如何把同步请求通过selector库和yield语法改造成一个简单的基于协程的异步请求,但是改造后的代码增加了很多监听和移除文件描述符的回调代码,编写起来比较麻烦,很不易懂。
不过在采用了Asyncio的思想并引入了Task和Future后,异步回调的代码都被消除了,但是大量的监听和移除文件描述符的代码还是存在,而Asyncio.Socket则封装了大量的读写事件的监听和移除的操作,只暴露了与Socket类似的方法,开发者通过这些方法可以简单快速的把同步请求改为基于协程的异步请求,比如《初识Python协程的实现》中的同步请求,它的源码如下:
1 | |
这份代码只对Socket进行简单的调用,其中涉及到Socket的调用方法有:
| 名称 | 作用 | 是否涉及到IO |
|---|---|---|
| socket.socket | 初始化socket | 否 |
| socket.connect | 建立连接 | 是 |
| socket.send | 发送数据 | 是 |
| socket.recv | 接收数据 | 是 |
在把它改为Asyncio.Socket时,只需要把涉及到IO的Socket方法以loop.sock_xxx(sock, *param)的形式进行修改,其中xxx是原来的方法名,sock则是通过socket.socket实例化的一个sock对象,而param则保持跟之前的一样的参数,更改后的代码如下:
1 | |
Asyncio Socket没有提供send方法,这里需要改为sendall。
可以看到,代码的改动并没有很大,除了传染性的async和await语法外,其它逻辑并没有什么明显的变化,在运行代码之后可以看到程序运行成功,并输出如下响应结果:
1 | |
可以看到程序是正常运行的,为了了解Asyncio.Socket做了什么工作,接下来会翻阅源码,探究它的处理方法,首先是loop.sock_connect,它的源码如下
1 | |
这个方法分为三部分,首先是检查Socket的ssl并进行一些参数校验,然后通过self._ensure_resolved方法进行dns解析,最后才通过self._sock_connect方法进行真正建立连接。其中,dns解析方法self._ensure_resolved是sock_connect方法与其他Socket方法的不同点,它的源码如下:
1 | |
通过源码发现,dns解析的逻辑中涉及到了run_in_executor方法,这个方法是把任务交给线程池进行处理。
在这里使用run_in_executor方法的原因是POSIX的DNS解析API是阻塞的,且没有提供异步选项,如果直接执行这个方法会卡住整个Asyncio Event Loop的运行,所以只能通过线程去调用这个API完成DNS解析,
不过Asyncio的默认线程池数量很小,如果是做爬虫类等需要频繁的进行DNS解析的项目,需要把默认的线程池改大一些。
uvloop使用的libuv也选择了POSIX API,它的工作原理也是通过线程去执行DNS解析,详情见why libuv do DNS request by multiple thread
在通过DNS进行地址解析后就拿到了真正的地址,这时可以开始进行真正的连接了,此时会调用_sock_connect方法去建立连接,它的源码如下:
1 | |
这个方法的执行逻辑与其他的Socket方法的执行逻辑是类似,它们都会先尝试去执行Socket原先的方法,这时候如果操作系统准备就绪,那么意味着可以无阻塞的执行了Socket方法,否则是操作系统尚未准备好,需要捕获异常并对异常进行处理。
在捕获到异常后,会通过_add_writer添加了一个写事件的回调_sock_connect_cb,再通过fut添加一个fut完成时的_sock_write_done回调,然后就会把控制权交给了事件循环。
当事件循环发现文件描述符有事件被触发时,会调用_sock_connect_cb获取建立连接的结果,如果结果有异常,则把异常添加到fut中,否则就把结果放置到fut中,这样fut都会从peding状态变为done,fut也就会触发_sock_write_done移除掉事件循环对文件描述符的监听。
_add_reader,_remove_reader,_add_writer与_remove_writer是Asyncio为socket与selector直接交互封装的方法,可以通过文章《Python Asyncio调度原理》进行了解。
除了Socket.connect方法外,与Asyncio.Socket相关的方法还有很多,不过原理是一样的,它们的流程都可以简化为下图: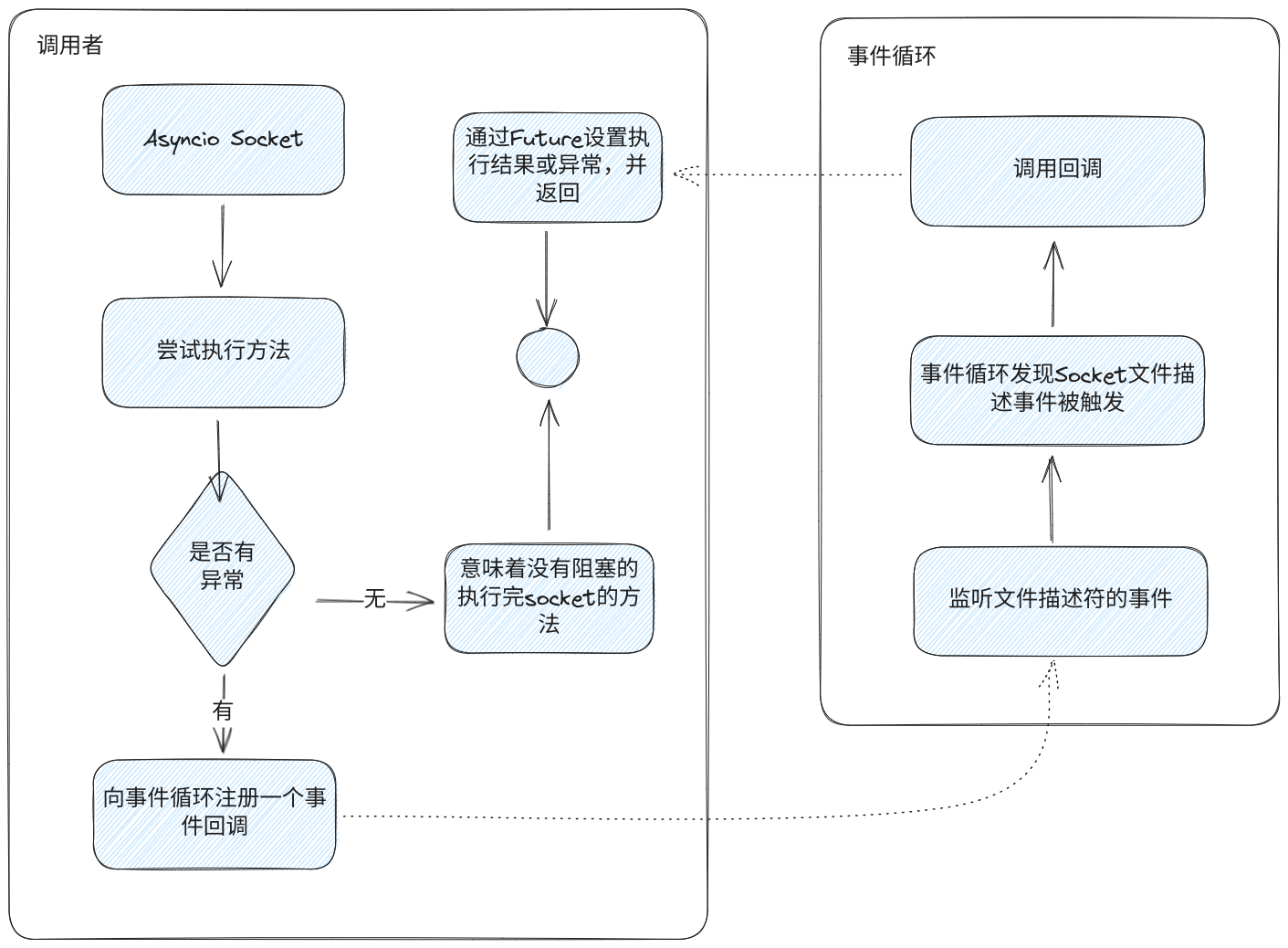 asyncio网络编程-asycnio-socket的执行逻辑.png
asyncio网络编程-asycnio-socket的执行逻辑.png
该图展示的是每个Asyncio.Socket方法的核心逻辑,各个方法具体的执行逻辑可以通过源码进行详细的了解,常见的socket方法与Asyncio Socket方法对照表如下:
| sock方法 | Asyncio Sock方法 | 归属 |
|---|---|---|
| bind | 无 | 服务端 |
| listen | 无 | 服务端 |
| accept | sock_accept | 服务端 |
| connect | sock_connect | 客户端 |
| connect_ex | 无 | 客户端 |
| recv | sock_recv | 共用 |
| recv_info | sock_recv_into | 共用 |
| recvfrom | sock_recvfrom | 共用 |
| sendto | sock_sendto | 共用 |
3.Protocol&Transport
Asyncio.Socket提供了Socket的调用方法的封装,但是如果直接基于Socket进行网络编程仍然会比较复杂,特别是TCP网络编程还需要处理很多东西。
为此Asyncio提供了一套Protocol&Transport接口,它们面向开发者提供的方法都会屏蔽底层的Socket细节,并基于TCP或UDP协议封装了一些方法调用,开发者只要根据Protocol&Transport协定的几个方法就可以快速开发出一个能够稳定使用的TCP服务。
在Asyncio的定义中,Protocol&Transport是无法分开的一个整体,它们一起定义了网络I/O和进程间I/O的抽象接口,对于开发者来说可以简单的把Protocol理解为专门负责处理被动调用的,也就是连接什么时候建立,连接什么时候接收了数据;而Transport则是提供了许多开发者可以主动调用的接口,包括了向连接发送数据,关闭连接等等。
3.1使用示例
官方的Protocol&Transport的示例是TCP Echo,在这个示例中,服务端会接收客户端的消息并返回给客户端一样的消息,然后再关闭连接。而客户端会发送消息,并在接收消息后等待被关闭,其中服务端的示例代码如下:
1 | |
这份示例代码分为两大部分,一部分是main函数,它主要的工作是通过create_server创建一个TCP服务并通过server.serve_forever()运行服务。另一部分是EchoServerProtocol,它主要是在TCP服务accept了请求后被创建的,除此之外,EchoServerProtocol在收到请求数据后会把对应的数据通过Protocol的不同方法传递给使用者,而客户端的行为则不一样,它对应的源码如下:
1 | |
通过源码可以看到客户端也分为两部分,首先是EchoClientProtocol,它与服务端的Protocol类似,主要的区别是在初始化时的多了on_con_lost和received_queue参数,通过它们可以把异步回调转为同步调用。其中on_con_lost是用于监听连接什么时候丢失,received_queue则是接收了来自Socket的数据以供调用者获取。
另一部分的main函数的不同点是先通过create_connection建立了连接并返回了Protocol&Transport,在建立连接成功后使用者可以通过Transport发送数据,或者通过received_queue获取数据以及通过on_con_lost等待连接被断开。
在把客户端与服务端的代码编写完毕后,先运行服务端的代码,然后再运行客户端的代码,会发现服务端打印了如下数据:
1 | |
而客户端打印了如下数据:
1 | |
通过输出结果可以看到示例代码是正常运行的,它们基于Protocol&Transport完成了数据的传输,
同时在运行的过程中涵盖了Protocol&Transport的主要方法,对应的执行过程如下图:![]() 1692808529149asyncio网络编程-ProtocolTransport.png
1692808529149asyncio网络编程-ProtocolTransport.png
图中loop代表事件循环的方法,t代表Transport的方法,p则代表Protoccol的方法,通过图的执行过程可以看到除了loop的方法是在进行初始化外,不管对于客户端还是服务端,Protocol负责做回调的事情,Transport则是做主动调用的事情。此外客户端和服务端的Protocol&Transport在建立连接和数据交互阶段的作用是一致的,可以看出Protocol&Transport的逻辑是客户端和服务端共享的。
不过再回过头看示例代码则可以发现示例代码基于它们进行拓展开发的方式有所不同,对于服务端,由于它得等到客户端调用才能开始处理请求,它属于被动的一方,所以对服务端进行拓展开发时需要在它们的回调事件中编写对应的业务代码,并对Transport进行调用。
而客户端则处于主动的一方,需要初始化一些容器把异步回调变为同步调用,比如asyncio.Future,asyncio.Queue等交给Protocol接收数据,然后与loop.create_connection返回的transport一起进行主动调用。
3.2.源码分析
在了解了Protocol&Transport的使用方法后,可以发现在Protocol&Transport中已经看不到Socket的影子了,需要通过对Protocol&Transport的源码进行分析,才能了解它性能更强的秘密。
在示例代码中可以看到客户端与服务端使用的Protocol&Transport是一致的,所以先从它们各自的初始化方法create_connection和create_server开始下手。
其中create_connection方法非常简单,它先是对Socket和其他参数进行校验,接着再进行DNS解析以及通过Happy Eyeballs快速的选择IP地址,然后再调用_create_connection_transport方法。
而_create_connection_transport方法只是创建并返回Transport实例和Protocol实例,其中Protocol实例是通过用户传递的Protocol构造函数创建的,Transport则是由对应的事件循环创建的。
- 快乐眼球算法见:Happy Eyeballs
create_connection的源码比较简单,具体见:https://github.com/python/cpython/blob/677320348728ce058fa3579017e985af74a236d4/Lib/asyncio/base_events.py#L976
对于服务端的create_server方法,它的处理逻辑一开始也是跟create_connection方法类似,也是先对socket和其他参数进行校验,然后再把参数和Socket放到Server实例中,接着再调用Server实例的serve_forever方法启动服务,而serve_forever的主要方法会调用到_start_serving方法(asyncio/base_events.py),如下:
1 | |
该方法会对所有托管的socket进行listen操作,并调用事件循环的_start_serving方法(asyncio/selector_events.py)为Socket向事件循环注册对应的可读事件回调,源码如下:
1 | |
通过源码可以看到这个方法是添加Socket文件描述符的可读事件回调,在添加之后每当Socket与客户端建立连接时,事件循环就会发现并调用_accept_connection方法,_accept_connection方法的源码如下:
1 | |
通过源码可以发现_accept_connection方法的主要作用就是同时处理backlog个socket的accept方法。
这个处理是专门针对事件循环进行优化的,因为Socket在接收到新的请求后会马上通知给事件循环,然后等待事件循环去调用事件对应的回调,虽然epoll的处理速度很快了,但是Socket收到新的请求与回调的执行仍有一定的延迟。
如果是触发一次事件就执行一次accept,那么处理整个程序accept的效率会降低,但是同时处理Socket的多个accept则可能会使系统的瞬间负载提高,所以这个方法会提供一个backlog参数供开发者选择backlog的大小以决定每次收到事件后执行多少次accept方法。
那么backlog的大小要怎么定义呢,其实这里的backlog与_start_serving方法(asyncio/base_events.py)中listen用到的backlog是一样的,而对于listen的backlog大小是需要根据场景来进行选择的,在Linux中,默认的backlog为128,而常见的后端服务的应用Nginx与Redis的默认值为511,这里不对backlog进行详细介绍,有兴趣的可以通过以下文章了解:
当accept成功后,则会调用_accept_connection2方法,_accept_connection2与客户端的_create_connection_transport一样,它创建了Transport实例和Protocol实例。不过在服务端中为了提高性能,通常都是一个协程对应一个Protocol&Transport,所以是通过create_task来执行_accept_connection2方法。
3.2.1.Transport
create_server和create_connection只是负责对参数的校验以及创建和监听Socket,真正负责数据交互的逻辑都藏在Protocol&Transport之中。
在Protocol&Transport的协定中,Transport可以理解为Socket的上层,它负责控制Socket的所有行为,包括数据的读,写,限制流的传输还有最重要的是对Protocol的流进行控制。比如在对Tranposrt进行初始化时,它会在Socket创建完毕后调用Protocol的connection_made方法,Transport初始化的源码如下:
1 | |
源码中,Transport在初始化时会先初始化参数并设置已读事件的回调,然后再对sock进行处理,在这里只设置TCP_NODELAY为True以禁用Nagle算法。
Ngale算法是为了优化网络传输而诞生的,但是优化网络传输跟时代是有关系的,在以前网络带宽都比较小的互联网初期,如果都是传输小流量的请求体会比较容易引起网络堵塞。
比如要传输10个字节长度为1的请求体,它们都会被装载在TCP报文上面,而TCP本身Header的长度在40字节左右,那么此时网络要传输的字节总数为10*(40 + 1) = 410字节。而在应用Ngale算法后,它可以把10个请求体合并在一起,那么传输的字节总数为40 + 1 * 10 = 50字节,可见在使用Ngale算法后可以减少大量的网络传输。
然而到了现在,大部分设备的网络带宽已经变得很大,而且Nagle算法与delay-ACK搭配会带来网络延迟,这对于类似HTTP1.1的请求来说影响可能不大,但对于那些小频快跑的实时数据交互场景却容易受到Nagle影响进而影响网络传输性能,为此Transport在初始化的时候就默认禁用了Nagle算法以减少网络数据交互的延迟。
这里只做简单易懂的举例和介绍,实际上是比较复杂的,可以通过下面的连接进一步的了解。
在Socket创建完毕后,Transport会调用Protocol的connection_made表示transport创建完毕,然后再调用_add_reader方法向socket文件描述符注册了可读事件的回调函数self._read_ready。
__init__方法无法被标记为async函数,所以这里使用了一个waiter用于标识__init__方法何时执行完毕,使其达到类似async函数的实现。
在Transport创建完毕后,每当socket收到一条消息,就会触发一个可读事件,然后事件循环就会执行self._read_ready去处理消息。
这里假设self._read_ready_cb为self._read_ready__data_received,它对应的源码如下:
1 | |
在去掉其中的异常处理后可以发现,实际上它的工作原理就是通过sock.recv接收数据,当收到的数据不为空时就调用Protocol的data_received把数据传递给开发者定义的方法中,为空时就调用self._read_ready__on_eof。
而_read_ready__on_eof的逻辑也是很简单的,它会调用Protocol的eof_received方法获取返回结果,这个结果是开发者定义的,开发者可以定义它返回的是True还是False,如果是返回True则只移除读监听事件,这样方便在关闭连接之前Socket还能继续发送消息,如果返回False则是直接关闭连接Socket,使Socket既不能读也不能写。
此外,还可以从源码看到在执行读事件的回调时如果有异常发生就会调用_fatal_error方法进行处理,这个方法除了报告异常外,还会关闭Socket。
在之前的介绍中Socket是拥有读写两个缓冲区,也介绍了Socket支持只关闭一个缓冲区,另外一个缓冲区还能继续工作的情况,而在Transport中,只关闭写缓冲区称为普通关闭,两个缓冲区都关闭称为强制关闭,它们对应的方法为close和abort,其中abort方法与_fatal_error的功能是类似的,它们对应的源码如下:
1 | |
通过源码可以发现abort与_fatal_error方法的唯一区别是_fatal_error方法会携带异常参数,abort的异常参数为空,而它们的执行逻辑都是调用_force_close方法对Socket进行强制关闭。
在_force_close方法被调用后,它会移除对应的事件监听,并把关闭连接的方法_call_connection_lost安排到Asyncio Event Loop中,交给Asyncio Event Loop调用。
这样做的目的是考虑到了还有一些读事件和写事件正在等待被Asyncio Event Loop执行,这时如果强制关闭Socket会导致这些事件被调用时由于Socket已经关闭而无法发送或获取数据,所以需要把_call_connection_lost的调用安排在读/写事件之后被运行。(asyncio的调度是按照先进先出为原则)
通过源码也可以发现close方法相对_force_close方法的唯一的区别是在buffer缓冲不为空时不会移除写事件监听也不会调用_call_connection_lost方法,从而确保所有在buffer缓冲区的消息都能正常发送。另外Transport还有一个方法–__del__,它是确保Transport被回收时,Socket会被完全关闭,不然可能造成内存溢出。
关于
Python Socket的内存溢出困扰了多个开源项目多年后才被解决,具体可以通过文章《Fixing Memory Leaks In Popular Python Libraries》了解。
最后,只剩下一个写数据的方法尚未窥探,它的相关源码如下:
1 | |
这里比较特别的是写数据的方法write是一个普通的函数,这是因为socket底层有缓冲区,所以写入数据是非常方便的,且在设置不阻塞后,只要调用socket.send就可以把数据投递到缓冲区并马上返回,这个方法不涉及任何IO。
然而缓冲区也有满的情况,于是Transport对缓冲区满的情况做一些处理,正常情况下缓冲区的满有两种情况,如下图: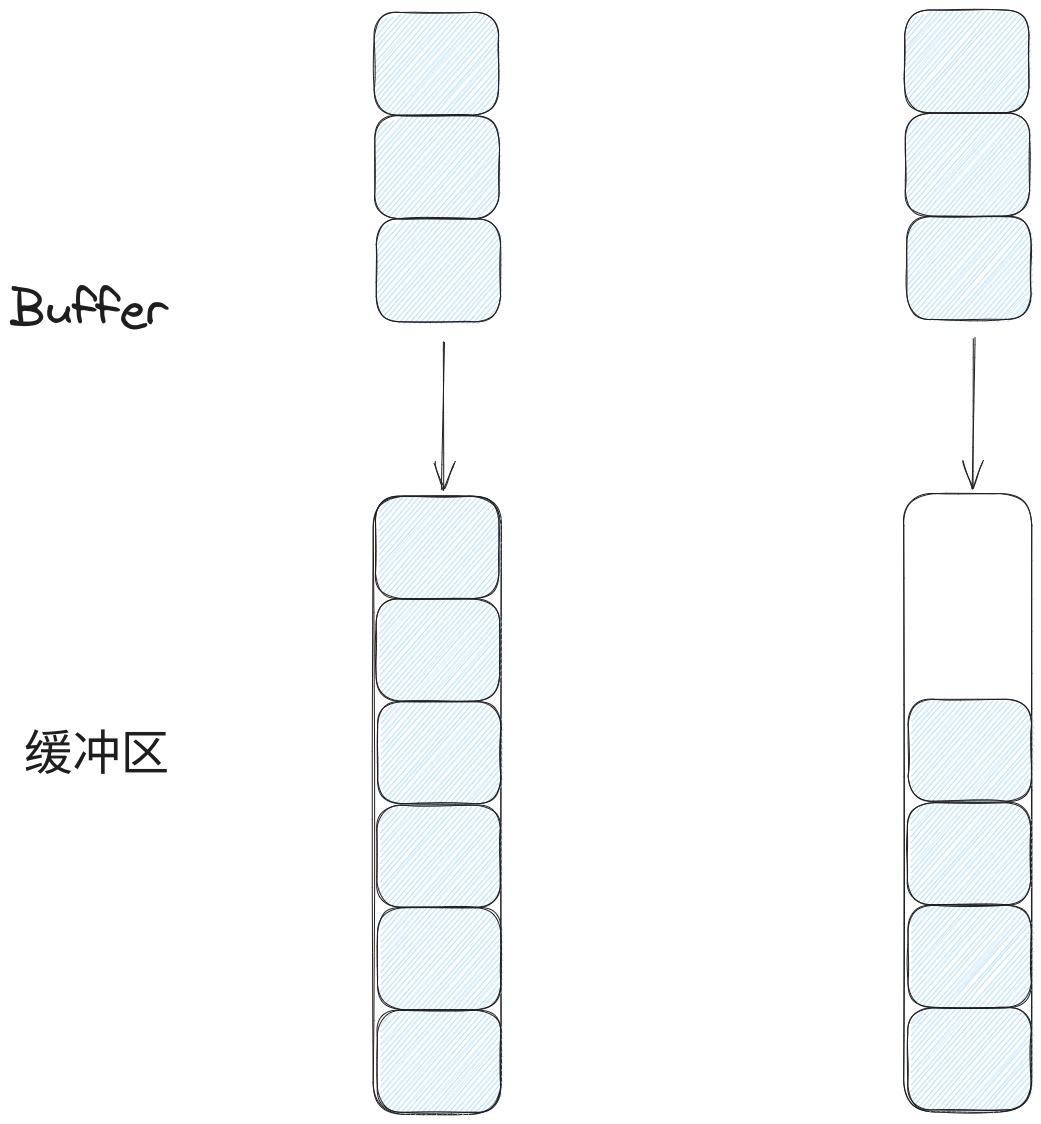 asyncio网络编程-socket写缓冲区满的情况.png
asyncio网络编程-socket写缓冲区满的情况.png
图中假设缓冲区的大小为5,而投递数据的大小为3,对于图的左边,在投递数据的时候会发现缓冲区已经满,这时候操作系统会返回一个错误;而右边是投递时还没满的情况,这种情况下只能投递前面两个消息,此时Transport在执行socket.send方法后会获得到返回值为2,接着就删除buffer中前面的两个消息,只留下一个消息等待缓冲区可投递时再进行投递。
在后续如果缓冲区还不可投递时且仍有数据通过write方法被发送过来,Transport会把数据添加到buffer中,再监听可写事件,当socket可写时,才会调用_write_ready方法把buffer中的数据发送,这一个过程会随着可读事件的监听移除才结束,而只有buffer为空或者发送异常时,才会移除可读事件的监听。
在write源码中还可以看到_maybe_resume_protocol和_maybe_pause_protocol方法的相关调用,这两个方法都是为了控制写入速度的,毕竟buffer的长度是无限的,如果一些恶意客户端与服务端建立请求后,客户端选择拒收消息从而导致buffer会堆积一堆数据,而这些数据也是无意义同时在积累过多后可能导致服务端崩溃,所以需要根据buffer的积累数据的量决定暂停写入还是恢复写入。
除此之外,在_ready_write方法中还涉及到了eof机制,eof是end of file的缩写,它是表示流的结尾的标志。由于TCP是双工的协议,如果其中一端想关闭连接时,另一端可能正在发送数据,虽然程序不需要再写数据了,但不能直接关闭Socket,需要获取对方发送过来的所有数据后才能关闭。
而socket的eof机制就是用于告诉对位的读端在收到这个标记后就不需要再接收数据,且后续的数据发送完后也请尽快的关闭。
在Transport中通过write_eof方法提供了一个主动标记写通道为eof的功能,使用者也通过can_write_eof判断当前Transport是否可以使用eof机制,它们对应的源码如下:
1 | |
可以看到Transport中与eof相关的源码很简单,它主要是先标记_eof为True,然后再判断当前的buffer是否为空,是的话就通过sock.shutdown(socket.SHUT_WR)关闭Socket中的写缓冲区。如果buffer不为空,则不做任何处理,在_write_ready发送完buffer的所有数据后再调用sock.shutdown(socket.SHUT_WR)关闭。
注:
- 当服务端调用
sock.shutdown(socket.SHUT_WR)后,客户端会通过socket.recv收到一条空消息,客户端会通过空消息判定是服务端到发送端已经eof了。shutdown与close的区别:socket对应的是操作系统的一个资源,多个进程可以拥有同一个socket的句柄,当调用close时,会把句柄的计数减为1,当句柄技计数为0的时候,socket才会真正的关闭并释放资源。而shutdown则是会关闭底层的连接,比如它可以关闭读端,写端或者同时关闭读写端,并等待对方发送FIN/EOF,但是它不会释放socket占用的资源,调用者仍然需要调用shutdown。
4.Stream
Stream是Asyncio中的高级API,通过Stream可以方便的为流式服务进行编程,同时通过Stream编写出来的代码既简洁又容易理解,如官方文档的TCP Echo client示例代码:
1 | |
可以看到,这份示例代码十分简单,它在初始化时会返回reader和writer对象,后续调用者可以通过reader读取消息,并通过writer发送消息和关闭连接。
而基于Stream接口编写的服务端的也变得简单了, TCP Echo Server源码如下:
1 | |
通过代码可以发现,基于Stream编写的TCP Echo服务中main函数的用法与Protocol&Transport类似创建一个Server实例,而处理连接的handle_echo方法的代码量比Protocol&Transport还要少,同时它不再像Protocol&Transport一样包含大量的异步回调方法。
下图是Stream客户端与Stream服务端的TCP Echo示例: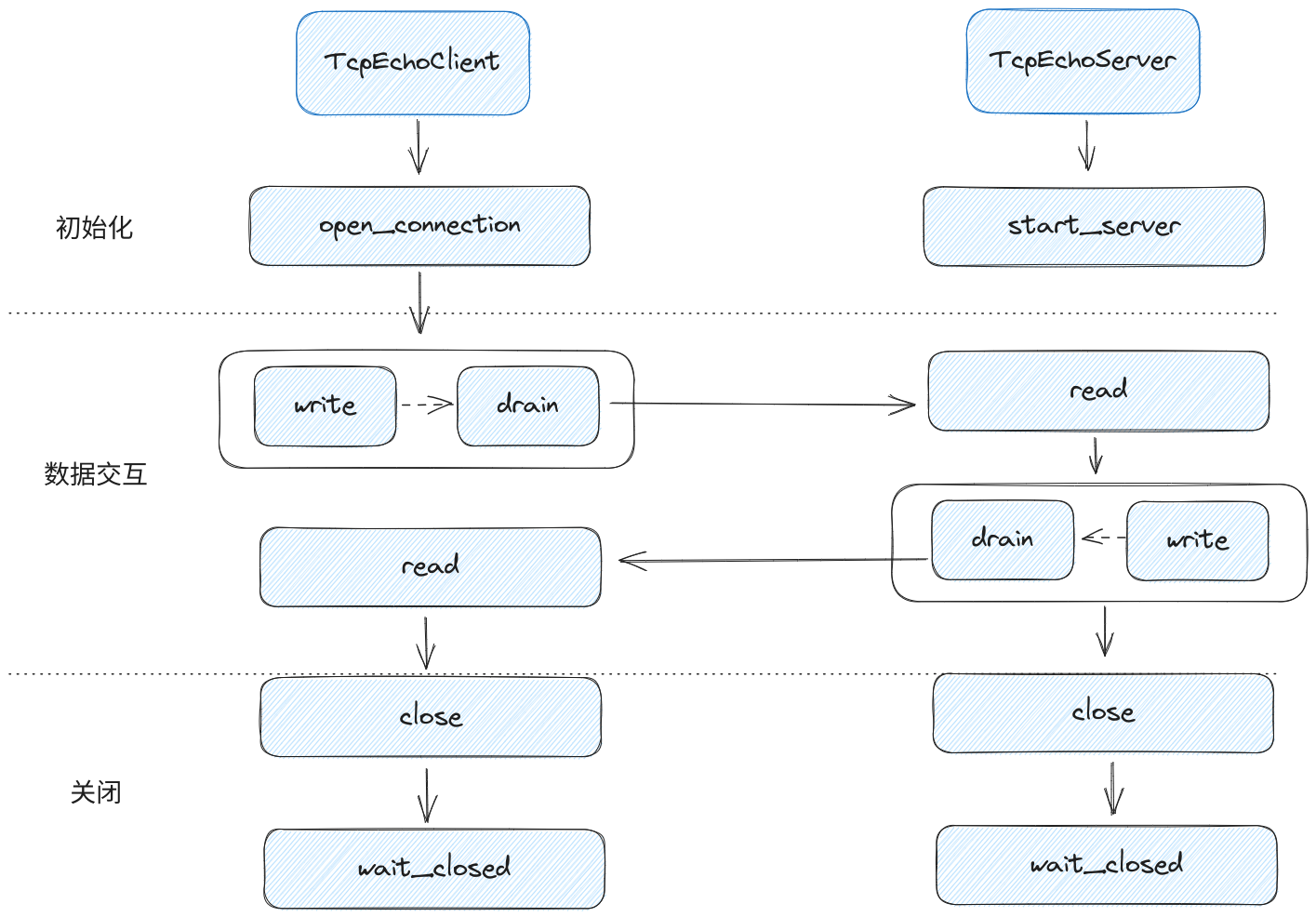 1693300383481asyncio网络编程-Stream.png
1693300383481asyncio网络编程-Stream.png
通过图可以发现它们交互的形式与Protocol&Transport类似,实际上Stream的核心StreamProtocol就是基于Protocol&Transport进行拓展,然后Stream还抽象出StreamReader和StreamWrite两个对象用于连接用户和StreamProtocol的数据交互,使用户可以使用同步的思想进行网络编程。
4.1.源码分析
Stream最大的特点就是把回调事件转为同步给用户使用以及运用了一些限流手段,但是它把细节全都隐藏起来了,需要通过源码去窥探它的运行逻辑。
首先是客户端和服务端建立连接和初始化的方法,它们的源码如下:
1 | |
通过源码可以知道,open_connection与start_server类似,它们都是先创建好StreamReaderProtocol,再交给create_connection或者create_server运行。
而StreamReaderProtocol是继承于Protocol,它相比于Protocol多了一些适配了StreamReader和StreamWriter的调用。
StreamProtocol只是一个中间者,很多逻辑与Protocol&Transport类似,故不会进行分析。
4.1.1.StreamWriter
对于StreamWriter可以认为是Transport的代理对象,所以它负责的也是主动调用的那部分,它的很多方法都是直接调用到Transport的同名方法,它与Transport的唯一区别就是多了wait_closed和drain方法两个方法,对应的源码如下:
1 | |
源码中的wait_closed是等待Protocol的_get_close_waiter的方法,这个方法会一直阻塞直到Protocol的connection_lost被调用,所以在调用await transport.wait_closed()实际上等于Protocol&Transport示例代码中的on_con_lost。
而drain方法则是Stream的流控制功能,它是结合Write一起使用的,它能防止写缓冲区被写满,以及及早的发现写缓冲区的异常,所以在使用Stream进行网络编程时,在执行write.write()后,一定要调用await write.drain()方法。
此外,源码中的drain方法有一句奇特的代码–await sleep(0),这段代码出现在这里的原因是在Protocol&Transport中,write的调用出错后会让事件循环尽快的执行_connection_lost的调用,但是用户在调用
1 | |
的过程中并没有让步在事件循环,如果不添加await sleep(0)显式的让步给事件循环,就会导致Protocol的_drain_helper方法会在_connection_lost之前调用,最终导致写入数据这个操作无法感知到连接已经丢失。
drain_helper方法是与流控制相结合的,它在Protocol&Transport调用了_maybe_pause_protocol时会阻塞,直到_maybe_resume_protocol被调用的时候才会释放,流控制的相关代码可以通过FlowControlMixin的源码了解。
4.1.1.StreamReader
用户在调用StreamReader时,通常都会调用到read*系列方法来获取数据,但是在Protocol&Transport中的数据是通过回调把数据传递给用户的。Stream为了解决这个问题,它把StreamReader设计成一个类似于先进先出的容器,当Protocol&Transport有数据时会把数据通过投喂数据的方法写入到SteamReader中,并提供获取数据,中止投递数据等方法交给用户调用。
其中投喂数据的源码如下:
1 | |
通过源码可以看出,StreamReader中的投喂数据方法和用户调用方法会共享self._waiter和self._buffer对象,其中self._buffer用于接收和读取数据,而self._waiter用于通知read系列等方法,告诉它们有数据来了,可以继续处理,StreamReader的读数据相关源码如下:
1 | |
通过源码可以看到StreamReader获取数据的方法比Protocol&Transport复杂了一点,它在调用read时,如果发现buffer有数据,就直接返回数据,否则就需要通过wait_for_data方法等待waiter对象被投喂数据的方法设置为不阻塞。
在这个流程中,Stream通过waiter对象和buffer完成异步回调到同步调用的转换,但是这样会导致每当有一条消息进来的时候,StreamReader需要通过Asyncio Event Loop的两次调用才能获取到消息,这也正是Stream比Protocol&Protocol性能差点原因。
5.总结
通过Protocol&Transport中的源码可以看到,Protocol&Transport通过一次事件批量accept以及使用了buffer加快了发送速度来获得了比Asyncio Socket高出很多的性能,而Stream通过asyncio.Future和asyncio.Queue把Protocol&Transport的异步回调转换为同步调用,以一定的性能消耗换取了易用性。
在TCP编程的场景中,这两个网络编程接口都有它们对应的使用场景,我们可以通过使用场景来选择对应的接口进行网络编程开发,通常情况下,默认服务端都会使用Protocol&Transport进行网络编程开发,因为它们都会追求极高的性能。
而客户端则默认会使用Stream进行网络编程开发,因为客户端会偏通过同步调用的方式进行开发,如果使用Protocol&Transport进行开发,也需要用到asyncio.Future和asycnio.Queue容器把异步回调转换为同步调用,这样一来使用Protocol&Transport开发和使用Stream进行开发的客户端性能是差不多的。
本文是偏理论的分析
Python Asyncio的网络编程相关的接口原理,在后续将介绍如何通过Protocol&Transport开发一个Web框架。
- 本文作者:So1n
- 本文链接:http://so1n.me/2023/08/29/python_asyncio_lib_network/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

