前记 py-redis库默认提供的是高性能,功能简单的分布式锁,这就导致了它无法兼容某些特殊的场景,在本文中将针对各种不同功能从零到一实现对应的锁。
1.py-redis锁的不足 在上一篇文章《分布式锁(1)–分布式锁的简单实现》 中分析了py-redis自带锁的实现,py-redis只提供了一个简单的分布式锁,这个分布式锁的功能非常简单,性能也是最强的,但是他的特性也比较少,只解决了如下问题:
1.通过token防止释放了别人持有的锁。
2.通过过期时间防止获取锁的程序崩溃后导致锁死锁。
但是它的部分功能是残缺的,比如:
1.通过循环的机制来重复轮询是否可以获取锁,这可能会增加IO次数(在sleep参数设置不好的情况),同时锁与锁的关系只有客户端逻辑在判断,无法在锁过期时由Redis通知到客户端。
2.只有锁续约逻辑,但没有WatchDog逻辑。
3.当前使用的是字符串结构来实现分布式锁,这个数据结构非常简单,但也意味很难对它进行功能拓展。
接下来将通过不同功能锁的实现,一一介绍如何解决这些问题。
2.公平锁 py-redis自带锁在发现锁被别人使用的时候,会休眠固定的时间再去探测锁的情况,当发现锁被释放时会马上去获取锁,否则就继续休眠一段时间再执行相同的操作。而这样就会导致有一个问题–先等待获取锁的任务可能会被别的任务抢先获取到锁,而公平锁就是为了解决这个问题,它能按照谁先等待谁就能获取锁的机制使所有任务都能公平的拿到锁。
为了实现这个机制,需要维护一个先进先出的数据结构,不过在制作公平锁之前,需要解决通过重复轮询是否获取锁的缺陷,而解决这个缺陷也比较简单,目前Redis支持Pub/Sub,BLPOP,Stream三种结构来实现事件监听与推送的需求,它们的优缺点对比如下表:
Pub/Sub
BLPOP
Stream
优点
标准的订阅与推送实现
简单方便,同时拥有超时机制
能确保消息有很大的概率不丢,它的实现与Kafka类似,功能完备
缺点
连接不同db的客户端能够订阅到相同数据,容易照成数据污染
如果在调用BLPOP时,队列中存在数据,那么不会阻塞而是会直接返回数据
只有在新版本中才支持
通过表可以看到这三种结构都不是比较完善的解决方案,它们都有一些小问题,不过这些问题可以通过一些方法来解决。不过BLPOP有一个特点是谁先阻塞,谁会先获得到数据,这意味着可以通过BLPOP同时实现公平锁和事件监听的功能,所以在这里选择了BLPOP方案。
Redission使用了Pub/sub来实现事件监听,同时它的公平锁实现起来比较复杂,不如BLPOP方便。
在使用BLPOP时有两个需要注意的,一个是BLPOP在调用时有数据就会返回,所以要确保订阅之前整个队列是空的,不过BLPOP有一个好处是只有队列有数据或者超时才会返回,其他情况下都会阻塞着,del删除队列时,BLPOP都不会受到影响,这样就可以解决调用BLPOP时可能存在旧数据的问题了,如下图的流程:
Redis高级锁实现之公平锁.png
图中黄色块代表代码业务逻辑,绿色块代表以lua脚本实现的原子任务,其他的代表每次一个Redis命令,通过图可以知道,在这个流程通过获取锁成功以及释放锁成功时使用del命令清空队列使队列不会拥有旧的数据,同时也可以看到在使用BLPOP后,先排队的客户端会优先拿到锁。
除此之外,还需要注意的是无论使用Pub/Sub,BLPOP还是Stream,它们都会占用一个Redis连接,这样会造成每个等待的锁都需要单独占用一个Redis连接,从而浪费客户端和服务端的连接资源。BLPOP xxx命令从一个指定的队列中获取数据,如果获得到数据,就会转发到指定的等待锁中,通知它可以继续执行获取锁的操作,这样就只需要占用一个Redis连接就可以完成对应的任务。
但是这里有两个需要注意的问题,第一个问题是用了代理器后其它等待获取锁的逻辑无法依赖BLPOP而达到公平竞争,所以需要实现一个先进先出的队列,等待获取锁的任务会把标记添加到队列中,然后等待标记被释放,后续代理器再通过队列拿出最先放入队列的标记,并标记它被释放,这样一来就能保证所有等待锁的公平竞争。
另一个问题是BLPOP可能由于网络问题而在一小段时间内无法获得到数据,这样会导致所有等待锁被阻塞,为此需要初始化多个代理器,然后在加锁时随机选择一个代理器,并把代理器的ID存在锁结构中,当锁被释放时就可以通过锁结构获取到代理器的名称,再把数据发送到代理器中。这样可以防止由于单点代理器导致所有锁都被阻塞的问题,最终的代理器到获取锁的具体逻辑图如下:
Redis高级锁实现之代理器接收事件与处理.png
图中方块组成对应锁的队列,队列名为锁名,其中绿色代表为空,红色代表为等待获取锁的标记。而中间蓝色方块代表代理器,白色方块代表锁的数据结构,它们的结构如下:
1 2 lock_name: "lock name 1" "proxy 1"
这个结构存在于Redis中,锁被释放时,释放逻辑会通过锁的数据结构把锁名推送到程序对应的Redis队列中。然后代理器的BLPOP命令就能获取到对应的锁名,并根据锁名释放对应队列中的元素,这样就可以在少占用连接资源的情况下实现了公平锁以及锁释放通知的操作了。
不过在创造代理器的时候会发现锁结构发生了改变,它需要的是一个类似于字典的结构体而不是之前的字符串,假设Redis是一个大的字典,那么之前的锁结构为:
1 2 3 {"{lock name}" : "{token}:{id}"
现在为了使它能处理更多的功能,需要把它变成下面的结构:
1 2 3 4 5 6 {"{lock name}" : {"{token}:{id}" : 0 ,"proxy" : "{proxy}"
其中lock name对应的不再是Redis的字符串结构而是Hash结构,{token}:{id}变为Hash结构中的一个key(现在先不用考虑它的值为啥是0),然后还新增了一个proxy的字段,用于代表当前的锁绑定了哪个代理器。
多代理器的缺点是需要确保所有客户端的监听器数量是一致的
2.1.代理类与监听器的实现 通过上面的示例图可以知道多个代理器都需要通过Redis的BLPOP命令获取数据,而每个锁只依赖于一个代理器,所以需要一个管理类来统筹代理类的创建,销毁以及代理器的获取,它的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Manager (object def __init__ (self, client: Redis, proxy_num: int = 8 , timeout: int = 1 ):str (i), self) for i in range (proxy_num)]str , asyncio.Queue[asyncio.Future]] = {}def listen (self, lock_name: str ) -> asyncio.Future:"""创建一个future加入到队列中,并把future返回给调用者""" if lock_name not in self.listener_dict:return fdef empty (self, lock_name: str ) -> bool:"""判断队列是否为空""" if lock_name not in self.listener_dict:return True return self.listener_dict[lock_name].empty()def start (self ) -> None :for proxy in self._proxies:def stop (self ) -> None :for proxy in self._proxies:def get_random_proxy_name (self ) -> str:return self._proxies[random.randint(0 , len (self._proxies) - 1 )].name
这个管理类比较简单,就是在初始化时创建一批代理类,然后提供了启动和关闭的方法,也向锁类提供了随机获取一个代理类名以及对应锁的监听的方法。
实际上在生产环境中需要做更多的处理逻辑,比如需要通过Manager中发现代理类挂掉就另起一个同名的代理类,这里省略…
接着就是代理器的实现,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Proxy (object def __init__ (self, name: str , manager: "Manager" ) -> None :None async def run (self ) -> None :while True :bytes ]] = await self._manager.client.blpop([self.name], self._manager.timeout)if result is None :continue 1 ].decode()if listen_name not in self._manager.listener_dict:f"{listen_name} not in listener_dict" )continue while True :if self._manager.listener_dict[listen_name].empty():break await self._manager.listener_dict[listen_name].get()if f.done():continue True )break def start (self ) -> None :if self._task:raise RuntimeError(f"{self.name} already started" )def stop (self ) -> None :if not self._task or self._task.done():raise RuntimeError(f"{self.name} not started" )
这个代理类都有一个自己的名称,它会在run方法中使用BLPOP监听与自己名称相关的数据,需要注意的是,这里有一个timeout参数,这个参数的作用是确保每嗝一段时间能重新调用BLPOP获取数据,防止因为网络而导致连接被悬挂从而导致代理类无法获取到Redis推送过来的数据。run方法获取到BLPOP返回的数据后,会根据数据的名称从manager中获取到对应的队列,然后从队列头获取到asyncio.Future,并设置为True代表等待获取锁的逻辑可以继续执行。
2.2.锁类的实现 代理类实现完毕后,就可以着手实现公平锁了,为了使本文更加简洁,实现的锁类结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Lock (object def __init__ (self ):pass async def __aenter__ (self ):pass async def __aexit__ (self ):pass @staticmethod def _new_token () -> str:pass @property def _token (self ) -> Optional[str]:pass @_token.setter def _token (self, token: Optional[str ] ) -> None :pass async def _acquire (self ):pass async def _extend (self ):pass async def _release (self ):pass
它对外只暴露__init__方法以及提供了async with的使用方法,其他方法皆为内部使用,此时锁类可以分为几大部分,分别为初始化、token的处理、获取锁以及释放锁。
2.2.1.初始化 首先是初始化,当前锁类的初始化与py-redis的锁类类似,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class BaseLock (object def __init__ ( self, client: Redis, manager: Manager, name: str , timeout: int = 9 , ) -> None :async def __aenter__ (self ):if await self.acquire():return selfraise LockError("Unable to acquire lock within the time specified" )async def __aexit__ (self, exc_type, exc_value, traceback ):await self._release()
可以看出它初始化分参数少了很多,这是因为改用了监听者模式从而不需要自旋获取所,此外与py-redis锁的最大区别点就是接收了一个名为manager的参数,方便后续通过管理类获取到代理器的名称,同时可以看到WatchDog的启用与关闭已经嵌入到__aenter__和__aexit__中。
2.2.2.获取锁 首先先关注一下获取锁的lua脚本实现,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 if (redis.call('exists' , KEYS[1 ]) == 0 ) then 'hset' , KEYS[1 ], ARGV[1 ], 0 );'pexpire' , KEYS[1 ], ARGV[3 ]);'hset' , KEYS[1 ], 'proxy_name' , ARGV[2 ]);'del' , ARGV[2 ]);return nil ;end ;return redis.call('pttl' , KEYS[1 ]);
这个脚本会接受4个参数,分别为锁名,token,代理器名称以及锁的超时时间,它的执行逻辑也是非常简单。它在判断锁不存在时,就会进行锁结构的初始化并返回一个空对象,代表当前程序获取到锁了。锁存在时,只会返回一个锁的过期时间给当前程序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class BaseLock (object None "" async def acquire (self ) -> bool:if self._token:raise LockError("Lock already acquired" )None int ] = self._timeoutwhile True :if listener or self._manager.empty(self._name):await self._do_acquire(token, proxy_name)if not ttl:if listener and not listener.done():True )return True if not listener or listener.done():3 if (ttl / 3 ) < 1 else 1 await asyncio.wait([listener], timeout=ttl)async def _do_acquire (self, token: str , proxy_name: str ) -> Optional[int]:int (self._timeout * 1000 )return await self.lua_acquire(
通过源码可以看到acquire方法除了获取锁和等待监听器返回外,还有一些其他的代码,比如在尝试获取锁之前会先判断当前是否有监听器或者队列是否为空,如果没有持有监听器且队列不为空,则意味着当前已经有别的任务在等待锁了,自己需要排在后再主动的获取一个监听器,并等到监听器收到通知后才去获取锁。
源代码中最重要的是为了防止监听器失效而使用asyncio.wait去等待监听器,其中asyncio.wait的超时参数不仅仅是ttl,因为这里使用超时机制本质上是为了防止由于网络问题导致监听器无法获得到消息而阻塞所有锁。在这个情况下,它发挥作用的时候会导致公平锁不再公平,所以这是一个兜底方案,在正常情况下不能触发,asyncio.wait的超时参数应该是ttl + 网络传输时间的最低容忍值。
2.2.3.释放锁 完成了获取锁的逻辑后就要开始解决锁的释放逻辑,锁的释放逻辑比较简单,它的lua脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 if (redis.call('hexists' , KEYS[1 ], ARGV[1 ]) == 0 ) then return nil ;end ;local proxy_name = redis.call('hget' , KEYS[1 ], 'proxy_name' )'del' , KEYS[1 ]);'del' , proxy_name);'lpush' , proxy_name, KEYS[1 ])'expire' , proxy_name, 3 )return 1 ;
这个lua脚本只需要两个参数,分别为锁名和Token,并返回释放是否成功。除此之外,它在发现释放锁成功时会推送锁名到锁对应的代理器中,这时候代理器的BLPOP就会获取到数据,并根据锁名告知某一个正在等待的锁逻辑可以继续执行,而程序的代码则与py-redis的锁类似,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class BaseLock (object None "" async def _release (self ) -> None :if token is None :raise LockError("Cannot release an unlocked lock" )int ] = await self._do_release(token)if result != 0 :None if result is None :raise LockNotOwnedError("Cannot release a lock that's no longer owned" )async def _do_release (self, token: str ) -> Optional[int]:return await self.lua_release(
2.2.4.验证实现 在前面的__aenter__和__aexit__方法中已经看到了WatchDog的启动和关闭功能了,剩余的逻辑则与《分布式锁(1)–分布式锁的简单实现》 中的WatchDog类似,这里就不多加描述了,具体的源码可以通过base_lock.py 查看。
锁类实现完毕后,运行如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 async def print_info (cnt: int ) -> None :f"Task:{id (asyncio.current_task())} , run cnt:{cnt} " )async def demo (manager: Manager, client: Redis ) -> None :await print_info(0 )async with BaseLock(client, manager, "demo" , timeout=1 ):await print_info(1 )await asyncio.sleep(1 )async def main ():await asyncio.gather(*[demo(manager, _redis) for _ in range (3 )])if __name__ == '__main__' :
可以通过输出会按获取锁的顺序依次打印:
1 2 3 4 5 6 Task:140557435220200, run cnt:0
可以看到它们成功获取锁的顺序与尝试获取锁的顺序是一致的。
3.可重入锁 可重入锁,也叫做递归锁,从名字上来理解它的作用就是在当前线程/协程已经加锁的情况下支持同个线程/协程多次的获取和释放,比如下面的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import asynciofrom redis.asyncio import Redisasync def main ():"demo" , timeout=3 )async with _lock:"get lock 1" )async with _lock:"get lock 2" )
如果py-redis默认锁支持重入锁,那么这个程序会打印如下输出:
并顺利退出, 然而在真正执行这段代码时会发现在输出get lock 1后,整个程序就卡住了,直到3秒后才会输出get lock 2并抛出锁异常,这是因为当前的锁不支持可重入功能,导致在同一个协程中无法多次获取锁。
如果有了解线程的可重入锁,就会知道可重入锁实际上是在锁的基础上添加了一个计数器,它会统计线程中对同一个锁的获取锁次数,在每次获取锁时计数器+1,而每次释放锁时计数器-1且当计数器为0时就直接释放锁,为此,需要在公平锁的数据结构中进行修改,之前公平锁的数据结构如下:
1 2 3 4 5 6 {"{lock name}" : {"{token}:{id}" : 0 ,"proxy" : "{proxy}"
可以看到结构中{token}:{id}对应着一个值0,在可重入锁中这个值有了一个新的含义–计数器,它会记录当前锁的重入次数,这样在获取释放锁时需要新增一个计数器的维护且在释放锁时需要判断计数器为0才代表是真正的锁释放。
此外,可重入锁还有一个特有的概念,那就是它只能在当前线程/协程重入,所以有了一些变化,比如在程序中锁的实例虽然不同,但是它们的锁名为一致时可以重入,还有它的WatchDog机制最好是在当前线程/协程第一次获取到锁的时候才启动,并在当前线程/协程最后一次释放锁的时候才关闭。Redis的数据结构,我选择了在让应用程序通过ContextVar共享数据,ContextVar实例可以在线程/协程中传播上下文,不过有个地方需要注意下,如下例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import asynciofrom contextvars import ContextVar"aaa" )async def sub (cnt ):set (cnt)f"Task:{id (asyncio.current_task())} , now_ctx_value:{cnt} , parent_ctx_value:{parent_value} " )async def main ():set ("bbb" )await asyncio.gather(sub("1" ), sub("2" ))"main ctx:" , ctx.get())if __name__ == "__main__" :
在运行代码后可以看到输出如下:
1 2 3 Task:140166475249768, now_ctx_value:1, parent_ctx_value:bbb
通过输出可以看到,对于不同的子协程,如果没有调用到ctx.set方法,那么它们依然能够获得到父协程写入上下文的内容,或者说它们得到了父协程上下文的一个副本,所以在后续的开发过程中,对于{token} {id}字符串的生成,需要先程序中的ctx获取token数据,然后再与id(asyncio.current_task)一起拼接,token的相关改造如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from contextvars import ContextVardict ] = ContextVar("lock_ctx" , default={})class AllowNestedLock (object @staticmethod def _new_token () -> str:return str (uuid1().hex ) + ":" + str (id (asyncio.current_task())) @property def _token (self ) -> Optional[str]:str ] = _lock_ctx.get().get("token" , None )if token:":" + str (id (asyncio.current_task()))return token @_token.setter def _token (self, token: Optional[str ] ) -> None :if token:":" )[0 ]"token" ] = token
它们最终只存锁的token本身,但在获取锁的时候要用Token跟协程ID拼接,设置锁的时候要把协程ID给移除。
有了上下文后,WatchDog的启动和关闭也可以跟上下文绑定在一起,具体表现在获取锁的时候通过上下文判断是否为第一次获取锁,如果是才会运行WatchDog并把当前实例传入上下文中,而在释放的时候通过上下文判断当前的实例是否为启用WatchDog的实例,是的话才会去关闭WatchDog。WatchDog是交给一个协程去单独运行的,它获取到的协程ID是本身而不是锁对应的协程ID,所以需要把协程ID传递给WatchDog中,修改后的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class AllowNestedLock (object async def __aenter__ (self ):if await self.acquire():if "watch_dog" not in ctx_dict:"watch_dog" ] = id (self)return selfraise LockError("Unable to acquire lock within the time specified" )async def __aexit__ (self, exc_type, exc_value, traceback ):if _lock_ctx.get().get("watch_dog" , 0 ) == id (self):"watch_dog" , None )await self._release()
Token逻辑整理完毕后就可以开始处理获取锁和释放锁的逻辑,由于可重入锁相比于之前的公平锁的数据结构只是多了一个计数器,所以应用程序中的代码不需要发生变动,只需要更改对应的lua脚本即可,首先是获取锁的lua脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if (redis.call('exists' , KEYS[1 ]) == 0 ) then 'hincrby' , KEYS[1 ], ARGV[1 ], 1 );'pexpire' , KEYS[1 ], ARGV[3 ]);'hset' , KEYS[1 ], 'proxy_name' , ARGV[2 ])'del' , ARGV[2 ]);return nil ;end ;if (redis.call('hexists' , KEYS[1 ], ARGV[1 ]) == 1 ) then 'hincrby' , KEYS[1 ], ARGV[1 ], 1 );'pexpire' , KEYS[1 ], ARGV[3 ]);return nil ;end ;return redis.call('pttl' , KEYS[1 ])
它相比于公平锁的主要区别是在于它在创建锁的时候,会标记计数器的计数为1且在发现锁已经存在时会判断这个锁是否是自己的,如果是计数器会加一且对锁进行续期,然后再返回加锁成功。lua脚本则是多了一个计数器的校验,它在发现锁存在时会使计数器减1,然后发现计数器不为0则告诉应用程序解锁成功,如果为0则会与公平锁一样执行释放锁,并通知应用程序的代理器,具体源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 if (redis.call('hexists' , KEYS[1 ], ARGV[1 ]) == 0 ) then return nil ;end ;local counter = redis.call('hincrby' , KEYS[1 ], ARGV[1 ], -1 );if (counter > 0 ) then return 0 ;else local proxy_name = redis.call('hget' , KEYS[1 ], 'proxy_name' )'del' , KEYS[1 ]);'del' , proxy_name);'lpush' , proxy_name, KEYS[1 ])'expire' , proxy_name, 3 )return 1 ;end ;return nil ;
接下来运行一段需要重入锁的代码,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 async def print_info (cnt: int ) -> None :f"Task:{id (asyncio.current_task())} , run cnt:{cnt} " )async def demo (manager: Manager, client: Redis ) -> None :await print_info(0 )async with AllowNestedLock(client, manager, "demo" , timeout=1 ):await print_info(1 )async with AllowNestedLock(client, manager, "demo" , timeout=1 ):await print_info(2 )await asyncio.sleep(1 )async def main ():await asyncio.gather(*[demo(manager, _redis) for _ in range (3 )])if __name__ == '__main__' :
在执行之后可以发现输出如下:
1 2 3 4 5 6 7 8 9 Task:140051624218856, run cnt:0
通过输出结果可以发现代码能够正常运行,但是这个代码有一个小问题,如下例子:
1 2 3 4 5 6 7 8 async def demo (manager: Manager, client: Redis ) -> None :await print_info(0 )"demo" , timeout=1 )async with lock:await print_info(1 )async with lock:await print_info(2 )await asyncio.sleep(1 )
这个例子的demo函数的锁实例实例是相同的,那么就会导致WatchDog会在第一个async with调用时启用,但是在第二个async with语法块执行结束时被关闭。Redis中的锁概念不同而引起的,接下来将在读写锁中解决这个问题。
4.读写锁 读写锁是锁设计中比较重要的一种锁,在对于大多数读操作远远大于写操作的业务系统中,读写锁能大大的减少锁带来的资源竞争频率。它最重要的核心思想是当有读锁存在时,依然可以获取读锁,而不能获取写锁,当读锁存在时,写锁和读锁都不能继续获取。
为了保证他们是同一个锁,但是却有两种类型的情况,可以在锁的数据结构中添加一个mode字段来标识当前锁的类型。Redis中为每一个读锁标记单独的过期时间,而锁的数据结构表示的是它最大的过期时间,那么数据结构将会变成下面这样:
1 2 3 4 5 6 7 8 9 {"lock name" : {"mode" : "read" ,"{token}:{id1}" : 1 ,"{token}:{id2}" : 1 "{token}:{id1}" : 1 , "{token}:{id2}" : 1 ,
这样一来,一个简单的读写锁结构就创建完成了,同时由于每个锁都有自己一个对应的数据,那么应用程序不再需要通过ContextVar来维护可重入的概念,直接通过锁对应的数据结果进行判断即可,WatchDog机制也将会像公平锁一样。
不过读写锁的可重入还是有一点不一样,在前面说到读锁下可以继续创建读锁,然而读写锁是互斥的,所以读锁下可以重入读锁,但不可以重入写锁。
Redission比较奇怪的是支持读锁重入读锁,第一次写锁后可以重入读锁。
另外,读写锁于之前的公平锁也有一点区别,由于读锁下可以继续创建读锁,所以读锁与读锁之间并没有什么联系,但是一旦有写锁参与就需要考虑它们的公平性了。比如先写后读,由于存在一个写锁堵住时,有一堆读锁正在等待,所以先写后读的通知是使用广播的情况处理,而先读后写则是像之前一样单播通知下一个锁可以去获取锁。
此外,先读后写还需要避免一个写锁饥饿的情况,由于读读没有冲突,当先有读锁时,写锁就需要等待,而在写锁等待的时候可能还有新的读锁进来,这样即使之前的读锁释放了,写锁也无法拿到锁,所以需要新增一个字段,这个字段代表当前是读锁,但已经有写锁在等待了,后续的读锁需要等写锁执行完毕后才可以获取锁。
在经过简单的分析后,可以看到读写锁的逻辑也没有那么复杂,比较绕的还是锁唤醒的步骤,所以本章着重说明监听器的实现,对于获取锁,释放锁,锁续约只会简单讲解,具体的读写锁实现和测试见rw_lock.py
4.1.监听器 在前面分析读写锁中,提到了读锁唤醒写锁时需要以广播的形式进行通知,但仍然需要考虑到公平锁的特性,在这种情况下,之前的监听器是没有办法实现的,需要进行改造。
首先是为了保证公平锁的可行以及在读读锁时需要单播,所以先入先出的结构必须存在,这样只能保留单播的功能,并通过单播链式唤醒的形式实现广播的功能,如下图:
Redis高级锁实现之读写锁的伪广播功能.png
图中有三个队列,红色放块表示写锁,绿色方块表示读锁,其中最左边的队列都是写锁,中间的队列是读写锁交替,对于这两个队列,监听器每次只会唤醒一个方块。而对于最右边的队列,它存在了读锁连续的情况,那么监听器会先唤醒第一个绿放块再唤醒第二个绿方块,然后就重新进入等待BLPOP的通知。
为了实现这样的效果,存入到队列中的数据需要新增一个标识位用于标识它属于读锁还是写锁,同时也要从asycnio.Queue换成deque,因为asyncio.Queue只暴露出获取队头的元素而没有提供查看下一个元素内容的方法。
分析完成后,开始对监听器进行修改,首先是针对Manager的修改,修改部分的源码如下:
1 2 3 4 5 6 7 8 class Manager (object def listen (self, lock_name: str , lock_mode: str ) -> asyncio.Future:if lock_name not in self.listener_dict:return f
通过代码可以看到listen方法新增了一个lock_mode参数用于标识当前锁的类型,然后在发现锁不存在时创建的容器是deque而不是asyncio.Queue,最后推送到队列中的数据也有点不一样,它不再只是future,而是lock_mode和future的组合。Proxy,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Proxy (object async def run (self ) -> None :while True :bytes ]] = await self._manager.client.blpop([self.name], self._manager.timeout)if result is None :continue 1 ].decode()if listen_name not in self._manager.listener_dict:f"{listen_name} not in listener_dict" )continue while True :if not len (listener):None )break if f.done():continue True )if lock_mode == "read" and listener and listener[0 ][0 ] == "read" :continue else :break
通过源码可以看到Proxy的主要不同是在释放future后会判断自己是不是读锁,如果是且队列不为空的话,会主动去查找下一个等待的锁是属于什么类型,如果是读锁,那么会唤醒它。
4.2.读锁 前面说到读锁相比公平锁需要考虑的问题如下:
1.读锁占用的情况下,依然可以获取新的读锁,但是它们的超时时间可能是不同的。
2.当前是读锁的情况下,当有写锁在等待时,读锁获取会失效。
为此读锁的lua脚本实现也会多了一些逻辑判断,读锁的获取锁脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 local mode = redis.call('hget' , KEYS[1 ], 'mode' );local wait_write = redis.call('exists' , KEYS[3 ]);if (mode == false ) then 'hset' , KEYS[1 ], 'mode' , 'read' );'hset' , KEYS[1 ], ARGV[1 ], 1 );'set' , KEYS[2 ] .. ':1' , 1 ); 'pexpire' , KEYS[2 ] .. ':1' , ARGV[3 ]);'pexpire' , KEYS[1 ], ARGV[3 ]);'hset' , KEYS[1 ], 'proxy_name' , ARGV[2 ])'del' , ARGV[2 ]);return nil ;end ;if (mode == 'read' ) and (wait_write == 0 )then local ind = redis.call('hincrby' , KEYS[1 ], ARGV[1 ], 1 );local key = KEYS[2 ] .. ':' .. ind;'set' , key, 1 );'pexpire' , key, ARGV[3 ]);'pexpire' , KEYS[1 ], ARGV[3 ]);return nil ;end ;return redis.call('pttl' , KEYS[1 ])
脚本中会先判断当前锁的模式,如果为false则代表当前没有锁存在,可以马上创建读锁结构,不过与之前有所不同的是这段代码:
1 redis.call('set' , KEYS[2 ] .. ':1' , 1 );
由于需要区分不同读锁的过期时间,所以要单独的为每一个新增的读锁创建一个Key,以此来表示它对应的过期时间。
接着就是锁的释放,本来读锁的释放是比较简单的,但是读写锁允许多个读锁被获取,而它们的过期时间是不同的,那么每次移除一次读锁都需要判断当前是否有其它读锁存在,如果有读锁存在则需要设置锁结构的超时时间为现存读锁中最大的超时时间,否则就移除锁并发送通知到监听器,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 local mode = redis.call('hget' , KEYS[1 ], 'mode' );if (mode ~= 'read' ) then return nil ;end ;if (redis.call('hexists' , KEYS[1 ], ARGV[1 ]) == 0 ) then return nil ;end ;local counter = redis.call('hincrby' , KEYS[1 ], ARGV[1 ], -1 );if (counter == 0 ) then 'hdel' , KEYS[1 ], ARGV[1 ]);end ;'del' , KEYS[2 ] .. ':' .. (counter+1 ));if (redis.call('hlen' , KEYS[1 ]) > 1 ) then local maxRemainTime = -3 ;local keys = redis.call('hkeys' , KEYS[1 ]);for n, key in ipairs (keys) do tonumber (redis.call('hget' , KEYS[1 ], key));if type (counter) == 'number' then for i=counter, 1 , -1 do local remainTime = redis.call('pttl' , KEYS[3 ] .. ':' .. key .. ':rwlock_timeout:' .. i);math .max (remainTime, maxRemainTime);end ;end ;end ;if maxRemainTime > 0 then 'pexpire' , KEYS[1 ], maxRemainTime);return 0 ;end ;end ;local proxy_name = redis.call('hget' , KEYS[1 ], 'proxy_name' )'lpush' , proxy_name, KEYS[1 ]);'expire' , proxy_name, 3 )'del' , KEYS[1 ]);return 1 ;
4.3.写锁 由于写锁本身的特点,它不可以重入也不与他人共享,所以它对应的锁结构比较简单,锁的获取与释放的逻辑也相对的简单,不过它有一个注意点就是当它要加锁时,发现有读锁存在,那么它应该设置一个标记位防止后面的读锁会在写锁没释放前就获取。
写锁获取锁的脚本如下,通过源码可以看到,它与公平锁的源码类似,唯一的区别是判断当前的锁为读锁时,会在Redis中设置一个标记:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 local mode = redis.call('hget' , KEYS[1 ], 'mode' );if (mode == false ) then 'hset' , KEYS[1 ], 'mode' , 'write' );'hset' , KEYS[1 ], ARGV[1 ], 1 );'pexpire' , KEYS[1 ], ARGV[3 ]);'hset' , KEYS[1 ], 'proxy_name' , ARGV[2 ])'del' , ARGV[2 ]);return nil ;end ;if (mode == 'read' ) then 'set' , KEYS[2 ], 'wait_write' );'expire' , KEYS[2 ], ARGV[3 ]);end ;return redis.call('pttl' , KEYS[1 ])
而写锁的释放逻辑也是非常的简单,它相对于公平锁的区别在于它在释放锁的时候会释放它写入的标记,脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 local mode = redis.call('hget' , KEYS[1 ], 'mode' );if (mode ~= 'write' ) then return nil ;end ;if (redis.call('hexists' , KEYS[1 ], ARGV[1 ]) == 0 ) then return nil ;end ;local proxy_name = redis.call('hget' , KEYS[1 ], 'proxy_name' )'lpush' , proxy_name, KEYS[1 ]);'expire' , proxy_name, 3 )'del' , KEYS[1 ]);'del' , KEYS[2 ]); return 1 ;
5.总结 由于Redis拥有丰富的数据结构以及支持lua脚本,所以它能支持很多种不同类型的锁实现,但是它仍然有一个缺点就是它的可用性不高,无法保证锁的完整性。虽然Redis的作者提供了一个红锁的解决方案,这个方案比较复杂,但仍然无法确保锁的准确性,在极端情况下仍有可能导致两个应用持有同个锁。Redis来实现分布式锁,需要选择其它方案。

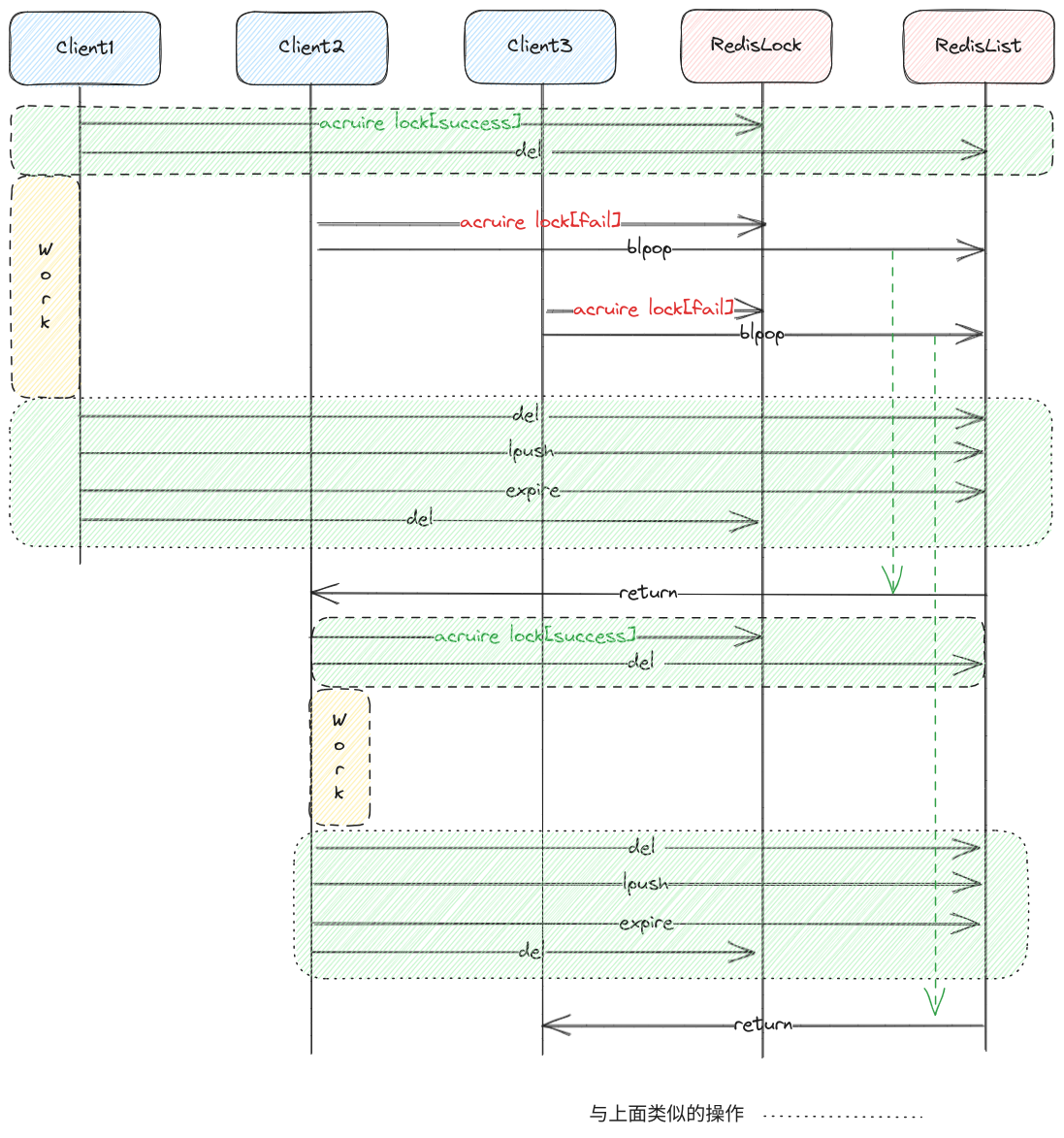 Redis高级锁实现之公平锁.png
Redis高级锁实现之公平锁.png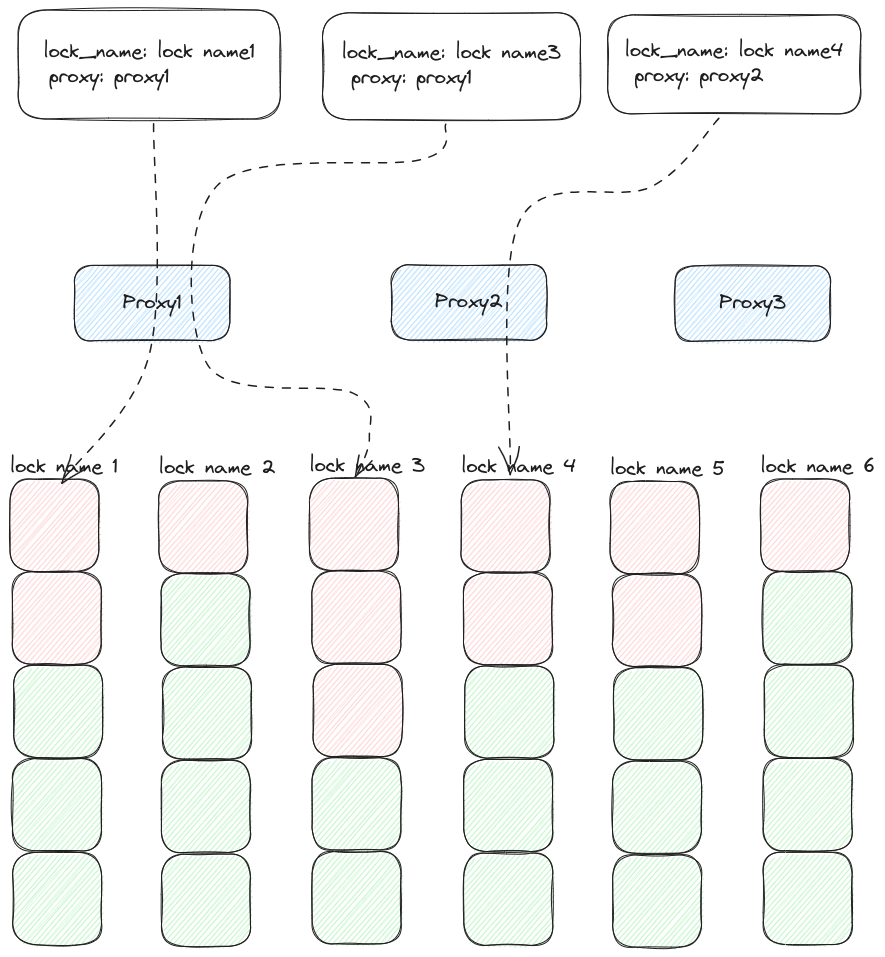 Redis高级锁实现之代理器接收事件与处理.png
Redis高级锁实现之代理器接收事件与处理.png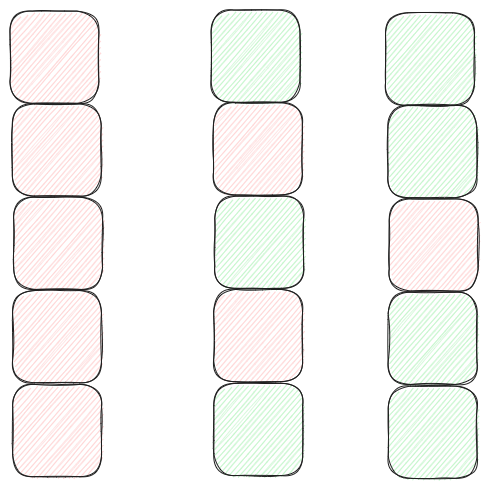 Redis高级锁实现之读写锁的伪广播功能.png
Redis高级锁实现之读写锁的伪广播功能.png
