
记一次TCP长连接过多的问题--实际上是被攻击了
前记
在接手了公司的SIP项目后的不久,发现服务器时不时就遇到了kamailio进程(用于处理sip协议)占用了过多的文件描述符,直接超过限制的情况,造成kamailio进程无法接收新的请求,影响线上用户使用。
这个问题有个两个难点,一个是只有发生问题才能进行排查,而发生问题时需要快速重启进程,不然影响用户使用;另一个问题由于发生时间充满随机性,而且时隔半个月到一个月才发生一次,所以整个解决流程用了快3个月,其中共发生了4次。
不过从发现问题到解决问题倒是收获了很多,只是到了后来才发现造成该问题的根本原因是客户端由于觉得接口加密逻辑有bug就跟API接口的商量一起下线加密逻辑,而我又不知道,加密逻辑下线后导致sip服务器的ip被暴露出来,引发SIP服务器被攻击…
1.SIP连接的特性
SIP服务器不像http服务器一样一个请求一个链接,而是用户在使用时就是一条长链接,并且一直存活着.一开始客户端的设计时只有客户端打开期间才有长链接,之后客户端改为后台常驻长链接也能存活,变成了用户只要不强制杀死客户端,服务器就会为之保留一个长链接。服务器的长链接数量发生了6倍的提升.
2.更改文件描述符限制
由于链接量的提升,导致了服务器更容易触发文件描述符过多的问题,由于刚接触对kamailio以及Linux不熟悉,在整理了一些资料后,就去咨询大佬,询问是不是由于服务器被攻击导致的,大佬说可能性不大,主要是用户链接数量增长了,而Linux限制的文件描述符造成了该问题的发生,在查阅资料后发现Linux的文件描述符限制在1024,修改即可。
2.1更改默认文件描述符限制值
更改文件描述符这个比较简单,通常可以通过ulimit -n查看默认限制值,以下是修改命令
1 | |
一般来说完成上述命令就可以了,然而kamailio运行在自己的用户组下, 同时是被Systemd托管的(守护),还需要改Systemd的默认配 /etc/systemd/system.conf 的 DefaultLimitNOFILE 和 DefaultLimitNPROC的值才能更改成功。
3.iptables限制和TCP调优双管齐下
改进了文件描述符后问题并没有解决(只是解决了客户端启用常驻功能后用户连接数量的限制),通过使用Tcpdump捉包分析后发现,根本原因还是由于一些恶意请求,造成了服务器启用了大量的半开链接(TCP握手后就不再发送请求),而这些恶意请求根本还没到kamailio层,光查看kamailio数据和日志是看不出问题的原因。之后通过iptables限制请求和TCP调优(主要是尽早关闭半开链接)可以从跟本上解决该问题.
注:这个问题解决时间比较长的原因是 发生异常的情况间隔比较久,需要等到异常才能捉取数据,同时跟大佬还猜测可能由于客户端异常造成的原因.
3.1误打误撞的找到问题
由于之前要写个定时程序来检测SIP服务器接口的可用性,本着能不造轮子就不造轮子的原则查了很多开源库,但查遍了python的开源库,要不就实现太完美了,接听电话都实现了也引用了很多其他的东西,要不就是要引用Twisted和zope,觉得这两个库太重了,要是出现问题再排查的话就很麻烦了。所以最后自己手撸了一个简单的SIP协议和利用sockets发送报文来模拟ping,检测SIP服务器接口的可用性。
然后很碰巧,在上线这个程序后不久,SIP服务器就会发生这个问题,凭着一直认为自己很渣,写的程序有问题的态度后,开始排查这个程序是不是有忘记关闭socket等问题,然后在进行第一步输入ss -a查看所有socket时(见下图有个185.104..。。),发现有个ip在这个输出列表里出现了很多次,通过命令:
1 | |
 ip占用端口
ip占用端口
发现该ip已经占用了684个链接了,而且之后利用tcpdump捉包发现该ip发的都是空包,并且在发送一段时间后自动转为半开链接,到此该问题的症状已经找到了—该ip发送大量的非法请求,导致占用了kamailio进程的可用文件描述符数量,导致kamailio进程无法再去处理正常链接而无法响应服务为止.
到了找出问题时,监控服务器也上线了,对每台服务器的文件描述符都进行了监控,通过监控数据可以看到,都是数据量突然上升,两小时后才下降(这个两小时也是一个重点,后来TCP调优后再看此图时才发现,linux默认在创建链接的两小时后tcp发送keep_alive发现对方没回包,服务器主动关闭了该sockets)
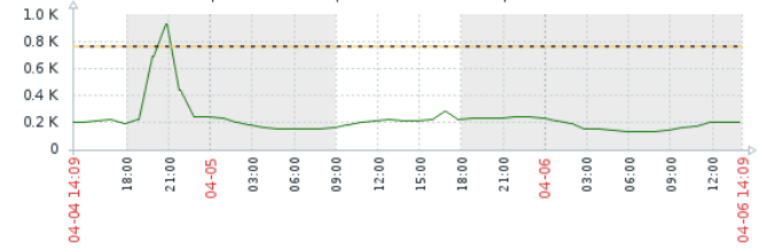 img
img
2.2使用iptables限制请求
找出问题后解决起来就容易多了,由于是短时间内有大量相同ip的请求,那只要不再响应或接受这部分请求就可以了,而iptables的recent模块就是实现这一功能的。
1 | |
通过iptables的recent模块的配置,目前可以防止请求,但是recent模块默认只记录100条记录,需要通过修改配置文件才可以去修改限制,而此时部分服务器长链接是数量基本都在2000,3000以上,后面预计长链接数可能会达到10000以上,靠这种方式效率还是太低了,而且占用了太多机器内存。
注:
如何修改记录条数限制见:https://linux.die.net/man/8/iptables的recent模块部分。
每个系统的iptables配置都不太一样,这里就不贴出来了debian见这里
2.3动态限制请求
为了解决上面使用iptables recent方案的问题,重新梳理了一下问题。发现该问题的触发时间是随机的,而且触发间隔非常久,如果能得知服务器开始被攻击就马上限制请求,而不要实时运行,那效果就会非常不错了.
通过上面的命令:
1 | |
可以得知目前系统同一ip请求最多的是连接数据库的请求(因为那个ip是数据库ip),而且从来不会超过43(kamailio配置最多就43个子进程),而恶意请求通常的ip都是从0开始的,而且是以200个请求/半分钟的频率增长,那我只要通过脚本定时运行判断哪个ip是数量多过,然后就加入iptables的限制,当数量少时把他移除就可以了。但是,每有一个ip就往iptables加入一条规则,如果规则多了,那每个包都要遍历一遍规则去判断,O(n)的时间复杂度太影响性能了,所以引用到了ipset模块,把复杂度从O(n)变为O(1),同时由于ipset带有timeout的功能,移除规则的工作也可以去掉了,方便了许多。
脚本示例代码如下(如果要提高性能,可以把netstat改为ss)
1 | |
创建ipset和iptables规则如下
1 | |
之后利用crontab 定时运行脚本即可,由于需要频繁读取日志,所以定时的间隔也需要考虑在内,不过后面通过日志解耦系统逻辑,所以也不用再跑脚本了,详情可以看我另一篇文章
3.TCP调优
通过这个问题,也发现了服务器启用了长链接,有很多问题需要处理的,不然会加重服务器的负担,影响性能,如果客户端那边因为网络问题而掉线,但是并没有关闭链接,而此时服务器还是维持链接的打开,直到keep_alive机制在两小时后启动,并判断客户端没有在使用时才断开链接(部分来自于网络).至于为什么是两小时以及不怎么建议随便修改,那可以重新看一看TCP协议卷1.
1.尽早关闭半开放链接
1
2
3
4
5
6# 探测包间隔
net.ipv4.tcp_keepalive_intvl = 75
# 探测失败次数
net.ipv4.tcp_keepalive_probes = 3
# 建立链接后的多长时间开始发送探测包
net.ipv4.tcp_keepalive_time = 12002.尽早关闭关闭失败的链接链接。
由于手机网络不是很稳定,会经常出现网络闪断的情况,当server端发现client端很久没有心跳,那我就得将该链接回收。由于Client端已经不可达,那server端链接会处在FIN-WAIT-1。这个时候该tcp链接已经是一个孤儿链接,也就是说它已经不属于任何一个进程。在不可达的情况下,它会默认发送9次,重试8次。由于该状态是非常占用资源的最大可占用64KB。所以我们得尽快让这个链接从FIN-WAIT-1中解放出来:
1 | |
- 3.快速释放FIN-WAIT-2,虽然该状态没有FIN-WAIT-1那么耗资源。
1
net.ipv4.tcp_fin_timeout=30 - 4.开启TCP syncookies,防止DDOS攻击
1
net.ipv4.tcp_syncookies = 1 - 5.syn报文(每个报文都需要排队)队列长度,超过该长度,请求就被丢弃,内存大于128M的默认为1024
1
net.ipv4.tcp_max_syn_backlog = 65536 - 6.每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目
1
net.core.netdev_max_backlog = 32768 - 7.定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数
1
net.core.somaxconn = 32768 - 8.是否启用时间戳选项,该选项会影响net.ipv4.tcp_tw_reuse,默认开启
1
net.ipv4.tcp_timestamps = 1 - 9.是否快速回收处于TIME_WAIT状态下的socket,由于手机网络时间戳会出现乱跳,所以必须关闭,这个默认关闭。
1
net.ipv4.tcp_tw_recycle = 0 - 10.被动接受tcp链接时,第二次握手发送SYNACKs的次数,默认为5,对应的时间大概为180秒,官方说法。
1
net.ipv4.tcp_synack_retries = 3 - 11.跟上面刚好相反,是主动发起tcp链接,发送SYNs的次数,默认为5,对应的时间大概为180秒,官方时间。
1
net.ipv4.tcp_syn_retries = 3 - 12.我们关闭了TIME_WAIT快速回收,我们通过tcp_tw_reuse和tcp_max_tw_buckets来控制TIME_WAIT避免吃光机器,该值默认180000.
如果服务器是作为客户端存在的,因为客户端连接受本地端口数限制,所以最好通过tcp_max_tw_buckets控制一下;如果服务器是作为服务端存在的,那么没有端口数的限制,只要情况允许,最好把tcp_max_tw_buckets设置大一些。纯粹就是防御dos攻击的,最好别认为降低该值。1
net.ipv4.tcp_max_tw_buckets=180000 - 13.开启处于TIME_WAIT态的socket重用,默认关闭。这个重用的是TIME_WAIT的端口,不是内存等,这个对客户端有意义。
1
net.ipv4.tcp_tw_reuse=1 - 14.确定TCP栈如何使用内存,当大于上限是报文将丢弃。一般按照缺省值分配,上面的例子就是读写均为8KB,共16KB
1.6GB TCP内存能容纳的连接数,约为 1600MB/16KB = 100K = 10万
4.0GB TCP内存能容纳的连接数,约为 4000MB/16KB = 250K = 25万
1 | |
- 15.表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间,2.2中默认180秒,之后默认为60秒
1
net.ipv4.tcp_fin_timeout=30 - 16.丢弃已经建立的tcp链接之前,需要多少次重试,默认15次,根据RTO的值,大概13-30分钟
1
net.ipv4.tcp_retries2=5 - 17.放弃回应一个tcp连接请求之前,需要多少次重试,默认为3
1
net.ipv4.tcp_retries1=3 - 18.收包速度大于内核处理包的速度时,输入队列最大报文数
1
net.core.netdev_max_backlog = 32768 - 19.listen系统调用,最大的accept队列长度,超过该值时,后续请求被丢弃
1
net.core.somaxconn=32768 - 20.针对孤立的socket(已经从进程上下文中删除,可是还有些清理工作没有完成),我们重试的最大次数。也就是server端close之后发[F.]的次数-1(0会重试一次),重负载服务器建议调小,默认为7。
1
net.ipv4.tcp_orphan_retries=1
- 本文作者:So1n
- 本文链接:http://so1n.me/2019/04/06/%E8%AE%B0%E4%B8%80%E6%AC%A1TCP%E9%95%BF%E8%BF%9E%E6%8E%A5%E8%BF%87%E9%95%BF%E7%9A%84%E9%97%AE%E9%A2%98---%E5%AE%9E%E9%99%85%E4%B8%8A%E6%98%AF%E8%A2%AB%E6%94%BB%E5%87%BB%E4%BA%86/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

