
使用Graphite小结
前记
初次认识Graphite时,Graphite已经发展了十年了,那时在负责kamailio相关工作内容,为了监控和查看kamailio数据,查找到的文章Kamailio statsd, better statistics in your voip platform.,虽然不太认同作者把statsd客户端的嵌入kamailio的理念,但发现Graphite这东西还是很不错的(虽然后面接触了Prometheus emmmm…….不过Graphite可以保存长期的历史数据,并根据时间自动做聚合旧数据, 这个优点Prometheus是无法代替的).
Graphite是一个包含了用于接收和整合数据的carbon,存储数据的时序数据库Whisper还有一个提供API的server.
它的理念十分简单,存的数据只有timestamp-value,该数据存在key的文件里面,用户可以用过以*.*.*的方式来设置数据维度或者标签.而写数据就更简单了只要发送TCP/UDP文本{key} {value} {timestamp}到carbon即可.同时他还提供按数据落盘时长来聚合数据的归档功能,觉得这个功能是非常棒的,因为数据的有分冷热的, 我们也不会专门去查看一年前的具体数据,只会去查看他的大概数据.
1.Graphite的好处
- 类似于RRD的时序数据库
Whisper,支持Metrics的精度递减,如一天内10s一条,七天内合并为1m一条,一年内1h一条(这点最棒!) - 带有丰富的查询函数, sum/min/max/avg/alias等等
- 简单的TCP/UDP协议,很容易插入数据
- 通过carbon-relay实现一个完整的HA方案
- 通过carbon-aggregator时间数据聚合方案
- 查询结构支持REST-API,查询功能丰富,查询简单
- 配置简单方便
- 支持百万数据收集(官方说的,实际上会打折扣)
2.Graphite组件
初次接触Graphite会比较蒙圈,因为一个最简单的完整Graphite需要由carbon-cache,Whisper,GraphiteWeb组合在一起
2.1组件介绍
- carbon-cache
它的主要功能是把接收到的数据先写在内存里,等过了一段时间后,把数据都flush 到whisper里.
carbon.conf中的[cache]定义了监听的端口和缓存策略,默认是2003端口接收文本协议,2004端口接收pick协议,此外还提供一个叫CACHE_QUERY的配置,方便GraphiteWeb从carbon-cache查询数据;
storage-schemas.conf 定义了Metric数据的retentions规则,当carbon-cache收到一个新的Metric时,就会创建一个新的.wsp文件,并把该规则应用到该文件上(所以文件创立后,再更改规则是没用的) - carbon-relay 提供复制和分片功能,为分布式而服务。carbon.conf中的[relay]定义了监听的主机、端口和分发模式;relay-rules.conf定义了在rules模式下详细的分发策略。
- carbon-aggregator 负责数据的聚合,通过聚合减少数据库压力防止磁盘爆掉.涉及到的配置文件:carbon.conf中的[aggregator]定义了接收和分发的主机;aggregation-rules.conf定义的是聚合策略。
- Whisper
存储数据的时序数据库,本身没有暴露出公共接口.但是Carbon-Cache会将以Whisper数据库格式将数据写入磁盘.以及直接从磁盘上的Whisper数据库文件查询数据.Graphite以上面两种形式来完成Whisper的读写. - GraphiteWeb 提供一些简单的图表和API功能,同时对一些查询到的数据进行缓存.GraphiteWeb在查询数据会通过carbon-cache来获得数据, carbon-cache会查询Whisper数据,以及还缓存在内存中的数据,再一起返回给调用者.
2.2结构介绍
TODO
3.与Graphite相关组件
由于Graphite十分简单,单纯使用Graphite是无法完成监控的,他还需要其他组件一起组合起来,才能变成一个完善的监控系统
聚合数据-Statsd
Graphite只存单纯的value,没有像Prometheus有time,gauge,set等概念,所以我们把数据写入Graohite前,需要自己先聚合数据,好在出现了一个StatsD,我们可以把数据发送给Statsd,由他实现time,gauge,set等功能,然后每隔一段时间再统一发送到Graphite里面(每隔一段时间也是比较重要的,自己把value直接写入Graphite时,多个Client也要控制到相同的写入点,不然看数据很难受).收集系统指标-Collectd
如果像从zabbix之类转过来的用户,应该会很怀念zabbix自带的报警指标,而collected就是这样的存在,通过配置,collected会收集机器上面的系统指标并发送到Graphite.报警系统
这一点我觉得是Graphite最缺的生态了,到现在都找不到一个适合Graphite且操作界面简便,配置简单的报警系统..如果不需要拥有ui界面,可以考虑自己编写一个简单的报警系统,如果需要界面,我觉得moira和Bosun都是比较不错的选择(需要注意的是,截止到2020-04,bosun的快速入门docker版本并不是最新的,需要下载后再自己手动替换.不然看了官方的配置文档会一脸闷逼)4.优化
Graphite的使用比较简单,只要更改下配置文件即可,比起使用,经常遇到的问题是如何去优化.虽然作者说Graphite很容易的去处理百万Metrics,但是实际上使用时觉得作者是有些场景没考虑进去.比如在查找某个metric中最大的前5个,而这个查询需要去打开所有的metric,消耗的时间和cpu都是非常痛苦的…
1.使用SSD,毕竟是存在硬盘上的,SSD的速度更快.
2.如果Metric太多,那就尽可能的减少数据精度.比如可以降到1分钟记录一次就不要10秒记录一次,这样可以减少写入的压力和文件的大小
3.使用Carbon-Aggratoe做预聚合.比如可以预聚合某个维度的Metric为All,这样在查询所有数据时,可以只查AlL的数据
4.写入层改用一些c或者go的方案如
carbon-relay改为carbon-c-relay.5.缓存部分预查询的数据 在使用图片时,可以配置让GraphiteWeb支持Memcached,缓存已查询的数据.在查询数据时只能自己实现一个proxy-api-server(把时间以某个间隔聚合再以查询查询变为key即可),并加上一个redis为查询的数据做缓存
6.替换GraphiteWeb为GraphiteApi,因为他只保留核心的Query功能,速度稍微快一些,同时他的插件功能也是很不错的.
7.替换Whisper为Kenshin,Kenshin通过把多个metric聚合到同一个文件里面,减少了查询时打开文件的开销,极大的降低了IOPS,不过由于底层逻辑已经变了,替换是需要一些成本
8.使用集群,集群能同时缓解读写的开销,同时增加系统可用性
9.使用标签功能,目前Graphite支持类似于Prometheus的标签功能,比原本的
*.*.*好很多,对性能也带来一定的提升,不过使用了GraphiteApi的话,就没办法使用标签功能了,GraphiteAPI到目前还未支持标签功能.(注:carbon-cache的配置中,标签功能默认开启的,如果不想使用需要配置carbon.conf的ENABLE_TAGS = False,不然会打印出大量的日志,影响服务器I/O)
5.其他
这里说的是平时遇到一些小问题或提高效率的方法说明
写入间隔
如果数据先到Statsd,再从Statsd写入Carbon,那一定要配置好Statsd与Carbon的间隔,不然可能会出现一些null的数据.
如果是自己多节点聚合数据再发送到Carbon,那要统一每个节点的发送时间是一致的,不然会出现数据间隔波动,数据展示会十分奇怪,同时聚合数据有时会出现数据不准的问题.Metric命名
因为Metric是数量非常多,我们需要把Metric根据命令来分类,方便管理与查询.
首先是Metric的大类,主要有- server-服务
- app-应用
- system-系统指标
- container-容器几大类.
之后再根据小类的情况进行细分,比如有这样一个Metric:server.server_name.project.region.ip.key, 就是按照服务名,项目名,地区,IP,最后才是Metric本来的名字.如果在命名遇到像region和ip这类Metric,不知道哪个先哪个后,那就要根据自己的业务查询情况,看看哪个先置被查询的文件数会少以点,以少的Metric来命名.
批量查看Metric或者批量修改Metric(以whisper-resize.py为例子)
用久了Graphite,肯定会遇到Metric管理的问题,比如有个Metric命名为Server.so1n.{app1, app2, app3}
如果我们要用whisper-resize.py去操作Metric,那就会进入/path/Server/app路径里面,进行如下操作1
2
3whisper-resize.py Server.so1n.app1 # 省略参数
whisper-resize.py Server.so1n.app2 # 省略参数
whisper-resize.py Server.so1n.app3 # 省略参数如果只有3个还好,有时有很多个或者是类似这样Metric:Server.{so1n, user_1}.{app1, app2}要进入多个路径更麻烦,这时候就需要借助其他命令进行批量处理了, 如:
find ./ -type f -name '*.wsp' -exec whisper-resize.py --nobackup {} 1s:2d 10s:31d 60s:365d \;这个命令要主要加上’{}’和’;‘具体见find使用方法, 也可以写成一个脚本来调用:1
2
3
4
5for f in $(find $1 -iname "*.wsp"); do
if [ -a $f ];
then whisper-resize.py # 省略参数
fi;
done自动删除无用Metric
如果用Graphite来做监控时,被监控的机器会出现变动, 当机器被删除后,Graphite中对应的Metric并不会被删除,需要我们进行人工干预,同上面一样我们也是用find命令来处理1
find /opt/graphite/storage/whisper/* -name '*\.wsp' -mtime 1 -delete其中
/opt/graphite/storage/whisper/*是whisper的路径,-mtime 1的1是代表文件最后修改时间是1天之前,-delete代表删除的动作
只要自己配置好命令的路径和天数,并运用到crontab中,即可自动删除无用Metric预测磁盘容量
在用时序数据库时,我们必须要做的就是去预测我们的规则(在Graphite是retentions规则)对空间占用的影响,会不会跑满磁盘的总空间.
carbon-cache在初次接收时会为每个指标创建一个Whisper文件,大小是由配置的精度和retentions确定的,Whisper数据库文件永远不会单独变小或变大.
因为Whisper文件会根据精度和retentions确定生成多少个数据点,而数据点的大小固定为12位.
所以我们可以确定存储容量大小跟精度和retentions有关系,但是自己计算太麻烦了,直接使用whisper-calculator.py 再输入retentions规则,如:10s:30d,10m:180d即可得知空间占用大小.
6.集群
在使用Graphite时,最让我困惑的是,我该如何去横向拓展Graphite,以提高Graphite的可用性和性能.在13年之前国内外都很难找到关于Graphite的横向拓展文章(我18年才接触),截止到本文章发表之前,国内也没有搜索到几篇关于Graphite的集群相关文章,经过一番搜索也只看到豆瓣和微博在使用Graphite(限定于大厂).而豆瓣通过改造Whisper为Kenshin,并用了稍微不同的架构来达到横向拓展的能力,而微博只看到18年时疯狂招人并维护一套跟Graphite的体系,我还没找到他们发表的相关文章.
搜索一圈后有一些感慨(可能是我搜索姿势不对),明明是一个挺不错的监控软件(不止于监控),感觉国内用Graphite的公司真少,可能18年大家都已经掉头到了go体系或者上云了,还好还有很多关于Graphite的英文文章可以参考.
6.1集群结构
Graphite的集群看起来复杂,实际上却是很简单的,因为Graphite的集群架构就是给一群单点Graphite的写入写出套上一层网关层处理数据和节点调用.集群的架构图如下,分为机器A,B,C. 其中A是最外层的carbon-relay和Gtaphite Web, 他们所属机器是Master机器, 负责处理写入数据和读取数据. 而另外两个小框是B,C机器, 他们负责数据的存取.
如图, A机器代表网关层节点上面跑着接受Metric的carbon-relay以及GraphiteWeb,carbon-relay负责接受Metric并利用hash分配到不同的机器B,C.而GraphiteWeb则根据请求去B,C机器采集数据,合并后返回给调用者.
B,C机器代表存储节点,它的功能则是一样的,负责存储数据,基本与单机Graphite一样,由carbon-relay把Metric分发给两个carbon-cache,并由GraphiteWeb提供接口给master的GraphiteWeb获取数据
这个架构的优点就是简单,没引入其他比较复杂的技术,同时网关节点跟存储节点横向拓展比较方便,特别是在引入配置中心后,配置文件的更改就可以自动化,只要做到安装Graphtie即可.
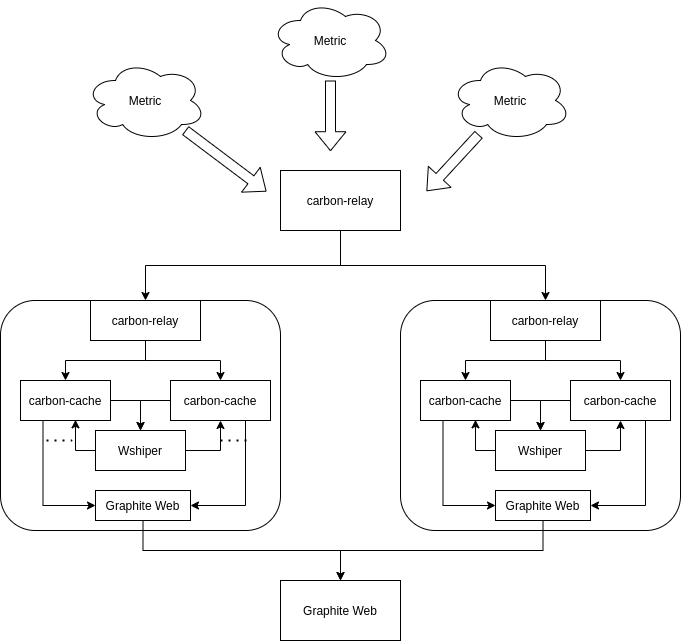 Graphite架构图
Graphite架构图
6.2如何配置
6.2.1存储节点
首先是改造存储节点,如果只使用单个carbon-cache的话,可以根据内核数增加新的carbon-cache,将配置
1 | |
改为
1 | |
启动方式从bin/carbon-cache.py start改为bin/carbon-cache.py –-instance=a start和 bin/carbon-cache.py –-instance=b start
carbon-relay配置改成如下,可以根据metric的一致哈希自动分配给对应的carbon-cache,由于是carbon-relay与carbon-cache的数据交换,把传输方式改为PICKLE,这样子传输速度快一点.
1 | |
接下来就是GraphiteWeb(如果用GraphiteAPI自行变通),通过更改local-setting.py文件的CARBONLINK_HOSTS:
1 | |
GraphiteWebc在查数据时,可以通过多个Carbon-cache一起查询,增加查询效率.
可以发现存储节点的配置是固定的,可以直接使用docker或者ansible一键部署.这样关于存储节点的配置就结束了,接下来就是配置网关层
6.2.2网关节点
还是以B,C节点为例,假设B节点ip为10.0.1.10,C节点为10.0.1.11,由于网关层只是负责把数据写入指定存储节点与从存储节点读取数据,所以只需要配置carbon-relay以及GraphiteWeb即可.
首先是carbon-relay,同样也是配置一致哈希与目标位置,同时配置REPLICATION_FACTOR,一般REPLICATION_FACTOR的值应该大于等于3(示例是2),确保数据安全保存.
1 | |
然后就是GraphiteWeb,他的配置跟存储节点一样,只要把CLUSTER_SERVERS配置为存储节点的GraphiteWeb,即可
1 | |
这样网关层就配置完毕了,唯一缺点就是每次新增存储节点时,网关层都需要重新更改配置并重启进程,这里可以根据自己的基础服务进行改进
附录
安装
StatsD, Graphite, Grafana方案唯一的缺点就是安装繁琐了,所以把自己的安装过程记录下来,当然目前有许多打包,如果需要可以参考打包安装的对应链接.
使用系统安装如(debian)的包会比较旧,一般都是python2,如无其他需要默认所有安装默认python2比较好
1.打包安装
2.分步安装
2.1graphite
若可以按以下安装的,之后安装方法查看此链接:https://www.digitalocean.com/community/tutorials/how-to-install-and-use-graphite-on-an-ubuntu-14-04-server
1 | |
注:以该方式安装后路径是(pip):/etc/carbon/ or /etc/whisper/,而以下示例路径是(python setup.py install):/opt/graphite/
2.1.1carbon
1 | |
或者
1 | |
在bin文件夹下,能够找到如下三种不同类型的Carbon守护进程:
- Cache:接受通过各种协议传输来的指标项数据并以尽可能高的效率将它们写入磁盘;在接收到指标项时,将指标项值缓存在 RAM 中,并用底层的 Whisper 库按照指定的时间间隔将这些值写入磁盘。
- Relay:有两个不同的用途:将输入的指标项复制并分区。
- Aggregator:运行于 cache 前方,在 Whisper 中记录指标项之前,缓存这些指标项一段时间。
2.1.2 Whisper
1 | |
or
1 | |
2.1.3运行carbon
使用默认配置文件
1 | |
2.1.4查看whisper数据
路径:/opt/graphite/storage/whisper
查看命令(对于后辍为.wsp的可用, 使用方法为命令+路径):
- whisper-info.py (whisper-info脚本获取为这些指标项创建的 Whisper 文件的元数据信息。)
- whisper-dump.py(whisper-dump是一个更完整的脚本,可以输出所有存储保留周期内的原始数据以及 Whisper 文件的元数据信息。)
使用方法1
2# grep是为了去除无效数据
whisper-dump.py invite.wsp | grep -v ': 0,'2.1.5graphite-api
或者1
pip install graphite-api --install-option="--prefix=/opt/graphite"按需确定自己是否需要1
2
3
4
5
6# 注:目前不支持python3, 请用上面的pip再加指定位置的方法,或者先安装cairocffi (0.9.0)
mkdir ./path/...
cd ./path/...
git clone https://github.com/brutasse/graphite-api
cd graphite-api
python setup.py install创建graphite-api的配置文件:1
2
3
4
5
6
7
8
9
10
11
12
13sudo apt-get install libpango1.0-0
sudo apt-get install libcairo2
sudo apt-get install libpq-dev
# python2
sudo apt-get install python-dev \
build-essential libssl-dev libffi-dev \
libxml2-dev libxslt1-dev zlib1g-dev \
python-pip
# python3
sudo apt-get install python3 python-dev python3-dev \
build-essential libssl-dev libffi-dev \
libxml2-dev libxslt1-dev zlib1g-dev \
python-pip
/opt/graphite/conf/graphite-api.yml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16search_index: /opt/graphite/storage/index
finders:
- graphite_api.finders.whisper.WhisperFinder
functions:
- graphite_api.functions.SeriesFunctions
- graphite_api.functions.PieFunctions
whisper:
directories:
- /opt/graphite/storage/whisper
carbon:
hosts:
- 127.0.0.1:7002
timeout: 1
retry_delay: 15
carbon_prefix: carbon
replication_factor: 1
在这个配置文件中,
search_index的路径一般为:/opt/graphite/storage/index,如果没有则需要自己运行 build-index.sh(位于/opt/graphite/bin, 需要安装graphite-web, 由于使用了graphite-web所以不用生成)命令生成,记得运行命令chmod 0644 index更改权限
whisper的数据路径配置为/opt/graphite/storage/whisper,这个是在carbon配置文件 /opt/graphite/conf/carbon.conf 中使用配置项LOCAL_DATA_DIR进行定义的。
注:如果遇到dlopen() failed to load a library: cairo / cairo-2且不会用到图形元素的可以屏蔽掉graphite_api/app.py526行以及下面相关的image代码,同时屏蔽/render/glyph.py
里的import cairocffi,不然需要安装更多依赖
2.1.6uwsgi
1 | |
debain和ubuntu系统或者运行后提示无法加载graphite_api.app模块的则需要先安装uwsgi-plugin-python(如debian:运行apt-get install uwsgi-plugin-python)
配置uwsgi
1 | |
如果搭配nginx ,也就是上面的uwsgi配置写的是socket而非http
在nginx配置中添加
1 | |
1 | |
2.2StatsD
2.2.1安装
1 | |
2.2.2 更改配置
在Graphite为StatsD更改匹配模式
1 | |
2.2.3 重启
1 | |
2.3grafana
1 | |
配置nginx反向代理grafana
1 | |
- 本文作者:So1n
- 本文链接:http://so1n.me/2019/03/27/%E4%BD%BF%E7%94%A8Graphite%E5%B0%8F%E7%BB%93/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

