
数据结构与算法-算法
前记
这里是补充数据结构里面缺失的对应算法,略产促
字符串匹配
字符串匹配一般是有一大串字符串target_str, 给给一个待匹配的字符串pattern_str, 找出pattern_str是否在target_str之中, 一般来说target_str会很大而pattern_str会很小.
最简单的就是暴力算法, 然后有Sunday算法和KMP算法, 暴力算法是一个字符一个字符的比较多, 思路简单, 但是计算资源会重复, 而后面两种算法只是基于前面的查找计算资源, 判断是否可以多跳几个字符, 减少计算资源的使用.
朴素的模式匹配算法
假设字母列表长度为m, 想要寻找的长度为n,则从头开始找,到第m-n+1位,寻找是否有相同的字母.
一般都是把n的长度当做滑动窗口的大小, 然后一位一位的增加, 直到窗口内容跟n一致
1 | |
Sunday算法
Sunday算法跟暴力算法一样, 会先检查是否匹配, 不过在检查到不匹配后, 并不是马上移位一位, 而是根据计算来判断是否可以进行跳位, 这一步也是Sunday算法比暴力算法快点秘诀, 但是遇到像上面的BBC ABCDAB ABCDABCDABDE和ABCDABD则性能会变差, 以下是Sunday算法的流程, 以How are you和you为例子:
- 第一次匹配: 发现匹配失败, 这时候就会去获取target_str字符串的第四位(因为you为3位), 发现第4位是空格, 不在
1
2How are you
youyou里面, 所以后面三位ar也不可能跟you匹配, 则直接跳到are的e进行匹配. - 第二次匹配: 从e开始检查, 发现匹配仍然是失败的, 则检查target_str字符串中
1
2How are you
youyou的o, 发现o存在与待匹配字符串中, 只能下移一位继续匹配, 最后发现后面都you是匹配成功.
1 | |
KMP模式匹配算法
KMP算法减少了一些已经计算过的计算量,但是他需要我们自己创建一个匹配表
对KMP算法的讲解:http://blog.csdn.net/chinwuforwork/article/details/51939826
1 | |
图的最小生成树
在一个有权的图中,既要做到遍历到所有点,同时要保证遍历顺序的权加起来是最小的
普里姆算法
普里姆算法的基本思想:普里姆算法是另一种构造最小生成树的算法,它是按逐个将顶点连通的方式来构造最小生成树的
从连通网络 N = { V, E }中的某一顶点 u0 出发,选择与它关联的具有最小权值的边(u0, v),将其顶点加入到生成树的顶点集合U中。以后每一步从一个顶点在U中,而另一个顶点不在U中的各条边中选择权值最小的边(u, v),把该边加入到生成树的边集TE中,把它的顶点加入到集合U中。如此重复执行,直到网络中的所有顶点都加入到生成树顶点集合U中为止。
普利母算法过程
1 | |
克鲁斯卡尔算法(优化版)
克鲁斯卡尔算法是一种用来寻找最小生成树的算法。在剩下的所有未选取的边中,找最小边,如果和已选取的边构成回路,则放弃,选取次小边
找最小边很容易,判断是不是回路就让我蒙了好久(现在还蒙- -),由于判断边的两个断点的最终根节点是否相同等于判断是不是构成回路,所以可以使用并查集来解决
构建最小生成树时,还要使等级低的指向等级高的,这样可以变成线性表,查找时速度就能得到提高
关于并查集:http://blog.csdn.net/qq_34594236/article/details/51834882
1 | |
图的最小路径
迪杰斯特拉算法(Dijkstra)
该算法执行过程中,把途中的顶点分为两个集合,当时已知最短路径的顶点集合U,以及尚不知道最短路径的顶点集合V-U。算法执行过程中,逐步扩充已知最短路径的顶点集合,每步从顶点集合V-U中找出一个顶点(它是当时已经能确定最短路径的顶点)加入U。反复执行这样的操作,直到从找到顶点v0到其他所有顶点的最短路径。该算法能同时给出这些路径以及长度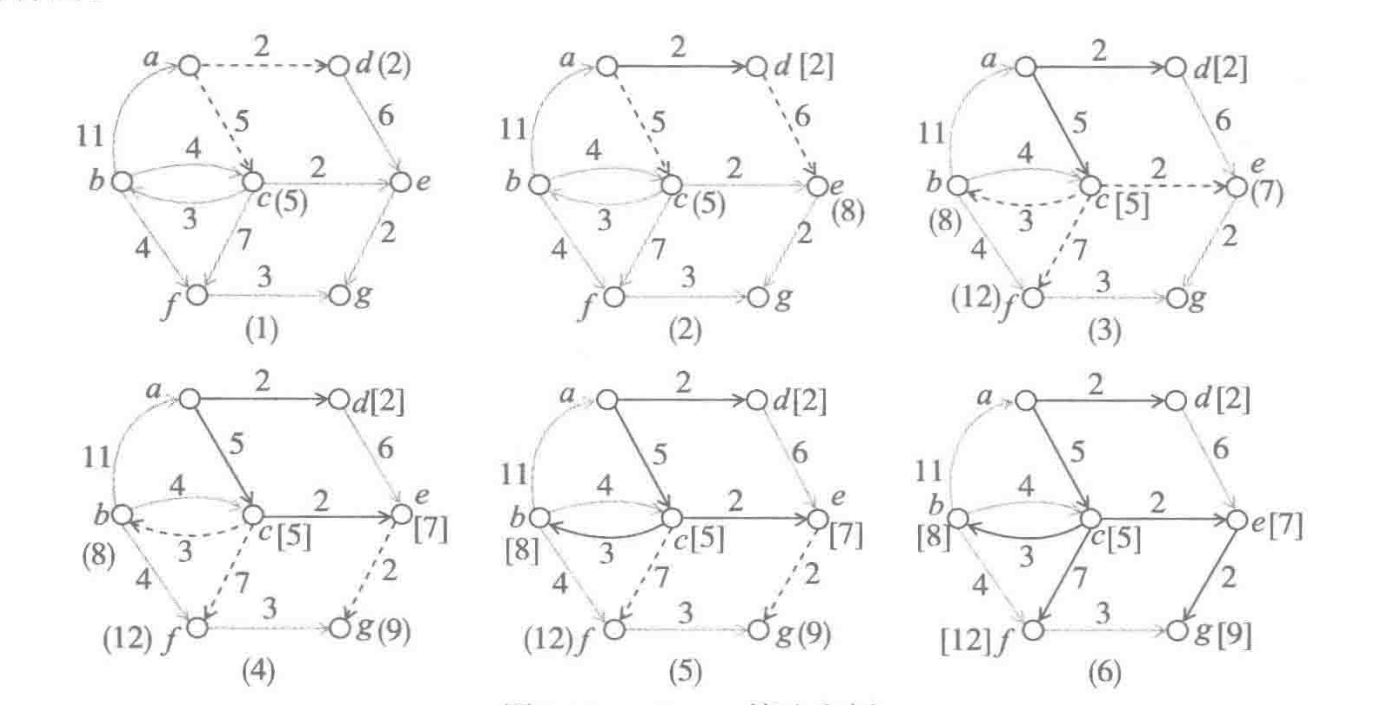 图示图
图示图
图中(1)状态,只有a在集合u,这是有两条边界变分别到顶点c和d。选择距离a最近的d加入u并标记相应的变,标出新发现的到顶点e的边界点,得到图(2)。这是最近的非u顶点是c,将其加入u后发现了3条新的边界边,找到的顶点e的新路径比原来的已知路径更短,记录这是的边界边和顶点的已知距离得到图(3)。将这是最近的非u顶点e加入集合u,记录到e的最短路径。由于新发现了从e一步可以到达g,记录相应的边界边,得到图(4)。这是虽然边界边中最短的是到g的边,但顶点b距离a更近,因此应该把b加入u。将b加入u后发现了一条到f的新路径,但其长度并不断与此时已知到f的最短路径(事实上,两条路径一样长),因此不需要更新路径,得到图(5).再经过两步,最后状态6给出了所有路径
1 | |
沸洛伊德算法
如果我要求顶点A到顶点B之间的距离的话,我可以先找一个顶点C,求解顶点A到顶点C加上顶点C到顶点B的距离和,如何这个距离和小于顶点A直接到顶点B的距离的话,那么这个时候就要更新一下距离矩阵中的值,将顶点A到顶点B的距离更新为:顶点A到顶点C加上顶点C到顶点B的距离和。这就是Folyd的核心思想了,那么如果要找到全局最优的解就要在选取中间顶点的过程中遍历所有的节点才行
1 | |
图的拓扑排序
拓扑排序算法
拓扑顺序就是:每次找到一个只指向别人的点 (学术性说法:入度为0),记录下来;然后忽略掉这个点和它所指出去的线,再找到下一个只指向别人的点,记录下来,直到剩最后一个点,所有记录的点的顺序就是拓扑顺序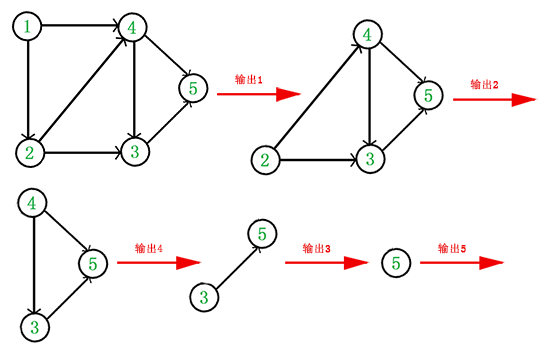 拓扑排序
拓扑排序
上图中,只有点1只指向别人,输出1;去掉点1和它伸出的两根线外只有点2只指向别人,输出2;…类推下去,得到拓扑排序结构: 1 2 4 3 5
1 | |
图的关键路径
关键路径算法
关键路径:在AOE网中,从始点到终点具有最大路径长度(该路径上的各个活动所持续的时间之和)的路径称为关键路径。
关键活动:关键路径上的活动称为关键活动。关键活动:e[i]=l[i]的活动
由于AOE网中的某些活动能够同时进行,故完成整个工程所必须花费的时间应该为始点到终点的最大路径长度。关键路径长度是整个工程所需的最短工期。
1 | |
- 本文作者:So1n
- 本文链接:http://so1n.me/2017/10/20/19/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

