RPC框架编写实践--服务的优雅的重启
前记
无论是微服务, 还是普通的API服务器, 他们都是进程, 服务在发布的时候, 必定会重启, 这时候会先杀掉旧进程, 再启用新的进程, 但旧的服务还在进行通信, 这时候强制杀掉这些旧进程, 会造成脏数据, 以及客户端端连接到服务的连接中断。要解决这些问题, 就要做到服务能优雅的关闭或重启的时候可以保障整个总体服务零宕机。
1.API服务的实现
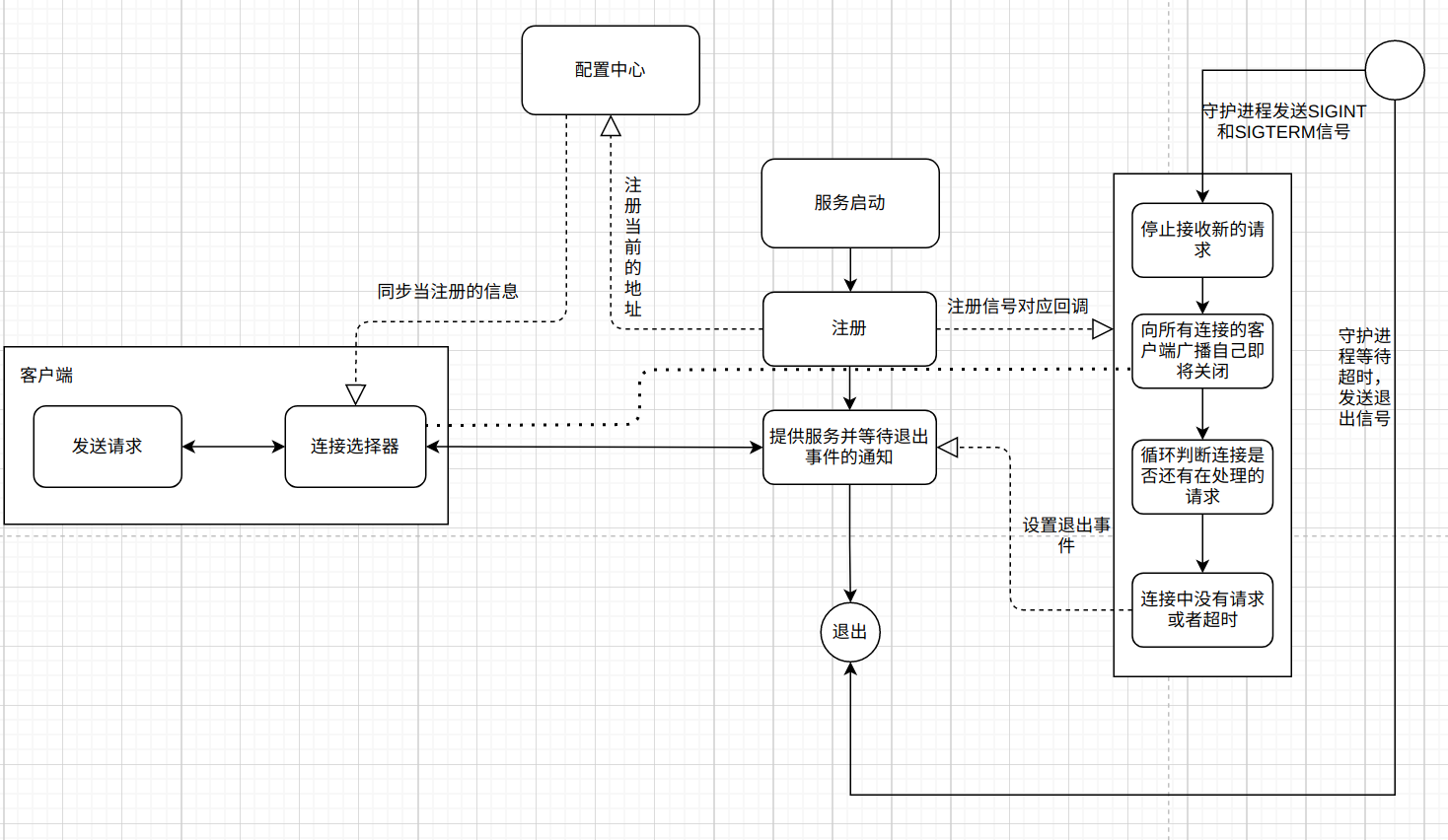
我的实现逻辑是通过参考uvicorn而来的, 它用于Python的异步API服务, 所以这里也以一个常见的API服务发布流程来介绍, 常见的API服务架构如下:
 uTools_1630140082901.png
uTools_1630140082901.png
这个服务十分的简单, 就是用户通过客户端访问到客户端指定的Nginx服务器,然后Nginx根据UpStream的配置, 把数据转发到对应的Api Server 1或者Api Server 2, 他们的提供的服务是一样的。
如果在某段时间, 我们在对服务端程序Api Server 1或者Api Server 2进行更新或重启时,如果我们直接使用kill -9杀掉旧进程并启动新进程, 则会有以下几个问题:
- 1.请求正在处理中, 可能只执行一半的变更, 然后直接出错。
- 2.旧的请求还未处理完,如果服务端直接关闭退出,会造成客户端中断。
- 3.新的请求通过
Nginx分发过来的时候, 服务还未重启完毕, 这时会由Nginx直接返回错误。
那么要怎么解决问题呢?
1.2.Nginx动态更改
在发布时, 我们一般会使用滚动更新, 就是先重启Api Server 1再重启Api Server 2, 这个步骤是:
- 1.更改
Nginx的UpStream配置, 流量只能发到Api Server 2, 然后重启Api Server 1。 - 2.
Api Server 1重启完成后, 更改Nginx的UpStream配置, 流量只能发到Api Server 1, 然后重启Api Server 2。 - 3.
Api Server 2重启完成后, 更改Nginx的UpStream配置, 流量会发送到Api Server 1和Api Server 2。
可以看到这个动作是非常的繁琐的, 就连我描述的文字都有大量的重复, 所以就会追求让这个步骤自动化, 比如引用了Nginx + etcd + confd的组合, 但是当服务需要频繁重启时, 就会发现这个组合性能不好。 这时就会转向OpenResty+etcd或者Nginx + etcd + Upsync, 它们的大致原理都是一样的, 首先是依赖于Etcd(也可以是其他配置中心), 来提供配置服务, 并由其他工具如CI/CD来控制配置, 并由conf, Upsync或者是OpenResty的lua来根据配置中心的变动动态更新Nginx的UpStream配置。
1.3.优雅的退出服务
重启必定会涉及启动和退出, 启动很简单, 只要能确保服务启动时能将自己的信息注册到注册中心即可, 而对于服务退出, 则多了几个步骤。
如果比较熟悉Supervisor, 就会知道它有个配置stopwaitsecs, 这个配置就是最大等待进程关闭是时间(单位:秒), 为了程序能健康退出, 我们需要按照我们的业务需求来配置这个参数, 这个参数会用在关闭进程的逻辑中。
Supervisor的关闭进程实现原理是发送信号SIGINT或者是SIGTERM给进程, 进程收到信号会开始停止接收连接, 然后等待现有链接关闭完成后再自己退出, 但是难免会有一些特殊的情况, 导致连接关闭的时间过久, 这些情况是非常的异常的, 我们也不可能一直等着, 所以Supervisor会等待stopwaitsecs秒后强制关闭进程。
而程序内部是怎么实现的呢, 我从uvicorn中偷师, uvicorn.server是uvicorn的服务代码, 只负责启动和关闭服务, 非常简单。
uvicorn.server代码的一开始, 就声明了要监控的信号是SIGINT和SIGTERM, 通过注释可以看出这两个信号分别是我们执行Ctrl+C和Kill命令触发的信号:
1 | |
这个信号会在通过serve方法中的install_signal_handlers来启用监听的, 并且挂载了对应的触发函数handle_exit:
1 | |
这个函数十分简单, 就是更改类里面的should_exit和force_exit属性。
而serve的方法是启动服务时调用的, 也就意味着在启动的时候监听信号, 此外serve在初始化后会执行main_loop, 这个方法通过on_tick来按照初始化要求来判断要返回self.should_exit或者是force_exit的状态, 如果状态为True就会一直循环下去, 否则就会退出循环(当然on_tick还做了其它与当前分析无关的事情):
1 | |
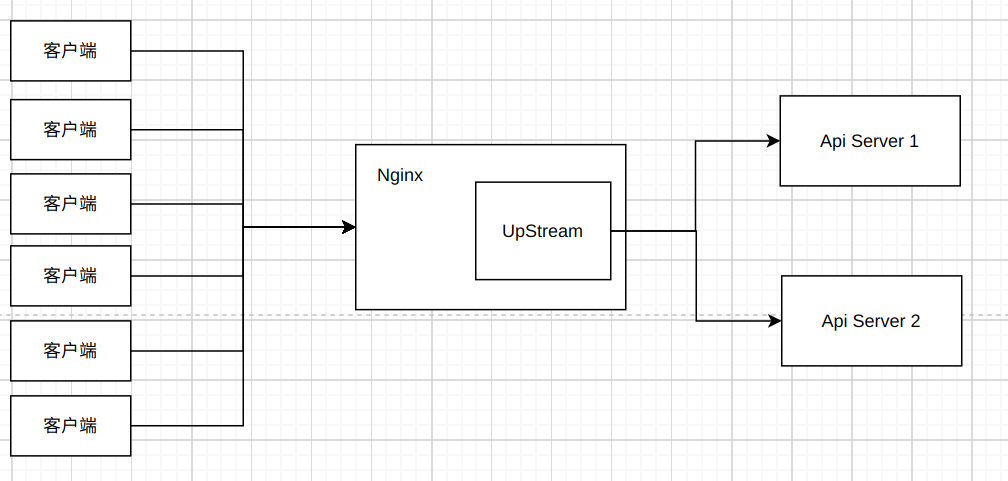
在main_loop执行完毕之后, 会执行shutdown的方法:
1 | |
从方法中的注释可以很清晰的知道, 这个方法主要做的是几件事:
- 1.停止接收新的连接建立
- 2.调用关闭连接的方法(该方法不会马上关闭连接, 而是逐渐等请求完成)
- 3.等待所有请求完成响应
最后整个流程整合如下图: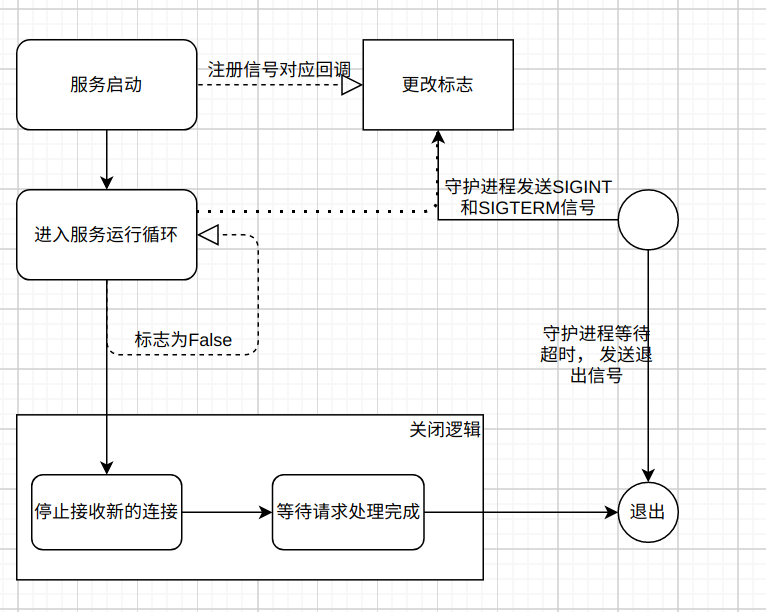 uTools_1630145321990.png
uTools_1630145321990.png
2.如何实现
上面说的逻辑可以整合成下图, 后台控制是CI/CD, 当提交代码后合并到master分支时, 就按照CI/CD脚本去控制配置中心更改配置以及重启对应的服务进程: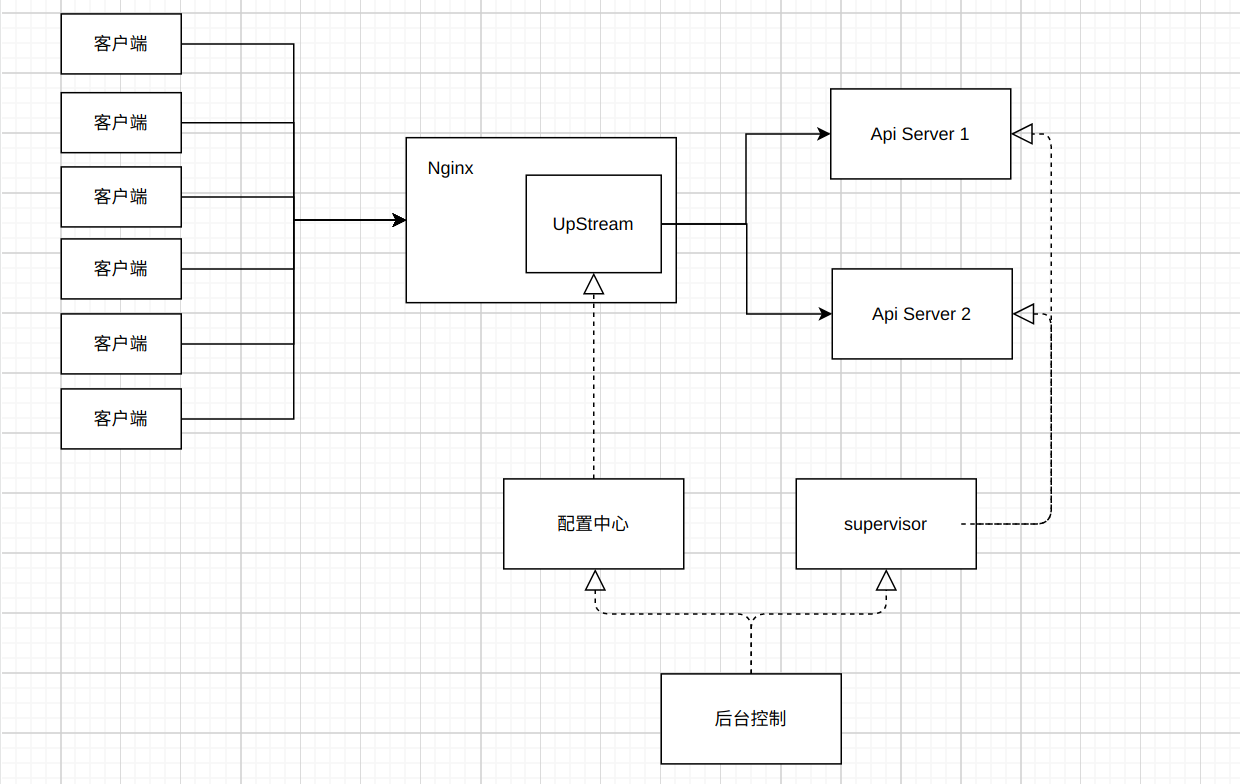 uTools_1630140104665.png
uTools_1630140104665.png
但是我在实现RPC框架时, 想到的场景是多个服务互相调用的情况, 而他们只依赖于配置中心一个第三方的系统, 于是我需要对上面的逻辑进行更改, 逻辑图如下:
uTools_1630164548242.png
首先对于客户端, 客户端会提供一个连接选择器,可以把它认为是一个简化版的网关, 它会从配置中心同步对应的服务信息。客户端发送请求时, 会先生成请求, 然后根据连接选择器, 从中挑选有用的连接(也就是自适应负载均衡),并通过该连接把请求发送到对应的服务器。
而对于服务端, 会在启动的时候注册一个退出通知事件、注册一个信号通知回调以及向配置中心注册自己的连接信息, 并提供服务, 这时客户端的连接选择器就能同步到服务端的信息, 然后与服务端建立连接。
当服务端进程收到SIGINT或者是SIGTERM的信号时, 会触发回调, 服务端监听的socket会停止接收小心的请求, 同时向所有客户端连接广播自己即将关闭的消息(兼容没有使用配置中心的客户端), 然后一直等待所有连接的请求已经处理完毕或超时,再调用退出事件, 使服务退出。至此, 整个优雅的重启逻辑搞定了。(代码比较分散, 且与uvicorn一样, 就不贴出来了)
- 本文作者:So1n
- 本文链接:http://so1n.me/2021/08/28/RPC%E6%A1%86%E6%9E%B6%E7%BC%96%E5%86%99%E5%AE%9E%E8%B7%B5--%E4%BC%98%E9%9B%85%E7%9A%84%E9%87%8D%E5%90%AF/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

