RPC框架编写实践--熔断器
前记
当依赖的服务已经出现故障时,熔断器会主动阻止本服务对依赖服务的请求,从而保证自身服务的正常运行不受依赖服务影响, 也减少依赖服务异常期间的压力,防止服务雪崩效应。
1.服务雪崩问题
服务雪崩, 是一个非常严重的问题, 它描述的是一个短时间内大量服务相继不可用的场景, 而引起服务雪崩的原因基本上都是很简单的, 比如一个超时问题。
如图, 这是一个简单的服务调用图, 服务A1会调用服务B1和服务B2, 服务A2也会调用服务B1和服务B2, 而客户端会连接到服务A1和服务A2, 服务B1和服务B2各自连接一个专属的MySQL服务, 正常情况下, 他们都能正常的工作着, 而且也没什么异常情况发生, 响应时间很短, 在0.00x秒左右, 吞吐率也OK。
假设有一天, 突然请求量开始上来了, 服务B1某个方法连接的MySQL出现问题, 所在的机器CPU直接飚满了, 此时服务B1的响应时间会越来越久。而在正常情况下, 我们对服务间的调用超时会设置在3秒左右, 当服务A1请求到这个有问题的方法且发现B1的服务没有在3秒内响应时, 就会断开重新请求, 但是服务B1还在执行刚才的调用过程, 随着时间的推移, 服务B1积累正在处理的请求数会越来越多, 也越来越力不从心, 即使服务A1和B2的其他请求没有涉及到数据库, 服务B1也没有办法在短时间内做出响应。
这时候服务A1和服务A2也会积累着很多请求, 服务A1和A2慢慢的也会被拖垮, 而且它们是是客户端调用的接收端, 客户端会非常多, 这时候可能会出现占用大量文件描述符的情况, 导致无法处理客户端的请求, 最后从客户端的使用者来看就是整个服务不可用了。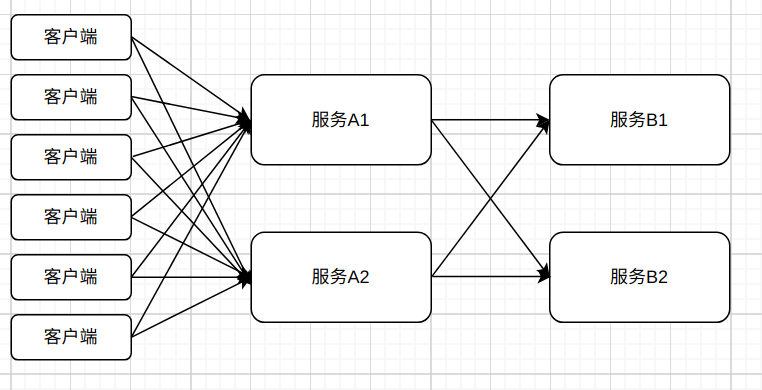 uTools_1630052386741.png
uTools_1630052386741.png
可以看出上面的服务雪崩的例子是由于服务B1处理请求太久,而服务A1以为是网络出现问题,进行大量重试而造成的。如果能让服务A1失败时快速重试, 或者是多个服务互相调用时, 能透传超时参数, 那么这个问题是能被缓解的, 但是超时的参数很难被设置好, 而且要确定什么时候重试, 重试多久失败, 重试间隔多少也非常的难。最好的情况就是服务A1知道服务B1当前不可用, 先不请求它, 直接返回错误, 直到服务B1恢复到正常状态, 而这样的一个实现就是本文要说的熔断器。(在电路中, 如果负载突然飚到很高, 熔断器就会自动熔断, 等待人工去恢复)
2.熔断的几种方式
熔断是服务自我保护的一种方式,用于确保服务不会受请求突增影响变得不可用,至少确保服务不会奔溃, 常见的熔断方式有:开关熔断、限流熔断、客户端动态熔断。
开关熔断是一个最简单的熔断方式, 通常是把配置放在一台第三方服务器, 客户端在调用某个服务之前, 会先通过第三方的配置服务器了解这个服务是否还在使用, 如果有就正常请求, 没有的话就不请求直接返回失败。
通常这种场景用在于一些电商项目, 比如某个大促节日的时候, 都会通过配置的方式把某些无关紧要的服务先变为不可用, 把部分机器性能让给主要服务, 通常这种熔断的状态只有开和关, 可以手工和定时去更改配置。
一般情况下为了提升性能, 同时在服务多的时候会引用网关或者配置中心, 那么这个开关熔断实现起来就会更简便, 同时也能减少重复调用的网络请求。 如通过配置中心实现的开关熔断, 调用服务会在内存存一份与配置中心同步的配置, 但配置中心的配置发送更改时, 通知服务更改内存的配置, 程序在调用服务前直接通过内存的配置数据进行判断, 决定是否要调用服务。
限流熔断
是一种特殊的熔断, 它本身是负责限流的功能, 但是由于限流会使请求量达到一定的程度时开始拒绝请求, 所以可以认为是一种特殊的熔断。不过限流除了直接拒绝请求外, 还可以实现均速排队的功能, 如在某一时刻有大量的请求到来,而接下来的一段时间都处于空闲状态,我们会希望系统能够在接下来的空闲期间处理这些请求,而不是在第一秒直接拒绝多余的请求。对于限流的具体实现则在下一篇文章再叙述客户端动态熔断
客户端在调用服务端的时候可以自己统计数据, 当发现过去某个阶段请求了100次, 但有70次失败, 它就可以预估接下来的失败概率会越来越高, 不再请求服务了, 而是直接返回错误。 不过服务端也不可能一直不可用, 所以客户端也需要能感知到服务端已经变得可用了。
上面3种实现中, 只有客户端动态熔断是全自动, 同时也是根据是否有错误来判断的, 同时这个熔断是放在客户端的, 在服务间网络出现异常时, 也能正常熔断, 可用性会更高。
3.熔断器的实现原理
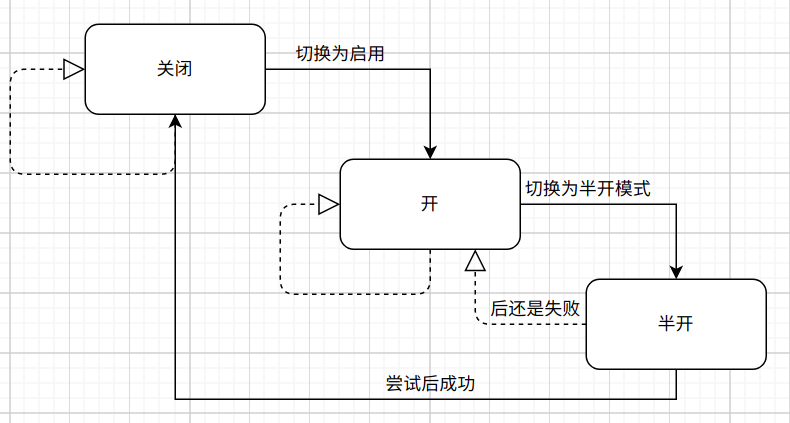
熔断器的本质上是一个包含了熔断检测, 熔断开关, 数据统计三个功能的状态机, 它通过收集统计数据来更改熔断开关, 每次有新的请求就会通过熔断检测判断当前请求可否放行, 它的3种状态分别是:
- 全开 此时熔断器打开, 使用快速失败返回, 请求不会请求到服务端
- 半开 当熔断器开启到一定的阶段后, 会到了尝试阶段, 此时的熔断器会允许少量的请求通过, 并通过这些请求来判断下一步的状态
- 关 此时熔断器关闭, 所有请求可以正常的到达服务端。
这几种状态的切换是有针对性的, 如下图, 全开只能切换到半开, 半开可以按条件切换为全开或者关, 而关只能切换到全开。
uTools_1630058698458.png
这些状态切换的条件全取决于最近一段时间内的统计指标, 客户端服务在调用阶段会收集一些请求和响应数据, 这些数据是具有近实时性的, 比如最近10秒或者最近一分钟的数据才被认为是有效的, 然后会按照固定的阶段时间获取有效的数据并统计得出如服务错误率的指标(采用滑动窗口的方式, 具体实现可见RPC框架编写实践–服务治理的基石, 避免了毛刺现象), 并根据指标判断当前应该是全开、半开还是关闭阶段。
不过, 上面这种实现的半开关不是很灵活, 从全开切换为半开需要一个固定的休眠时间, 而服务的恢复时长是不确定, 如果有一种机制能实时知道的话, 那就更好了。Google Sre的策略实现就是避免了这样的一个问题,它的思路非常简单, 就是每个窗口期计算一次当前的请求成功率, 并按照这个成功率来决定应该放行多少请求量, 同时确保即使成功率为0的时候也有少量的请求被放行, 这些被放行的少量请求就是用于探测服务是否可以用的, 它们的量级不多, 不足以让远端服务崩溃。
该算法理解起来简单, 实现起来也简单, 这个算法依赖于两种指标, 一个是客户端请求数, 一个是客户端请求成功的数量, 然后根据这两个指标过去两分钟内的数据判断熔断器的状态:
- 通常客户端请求数等于客户端请求成功的数量, 此时为全开模式
- 客户端请求服务端开始出现异常,请求成功的数量逐渐减少, 此时为全开模式
- 客户端请求服务端持续的异常, 请求成功数依然来逐渐减少, 直到请求成数大于K变量乘以请求成功的量时, 进入半开模式, 会按照两个指标计算出来的概率进行限流。
- 客户端请求服务端持续的异常, 同时部分请求直接被拦截, 主动丢弃, 请求成功数的占比越来越少, 计算得出拦截的概率也在逐渐变大, 直到最大值(请求数/(请求数+1)), 此时只有极少的流量通过。
- 客户端请求服务端的异常逐步减少, 拦截的频率也逐渐变少,直到等于0, 至此, 当前的限流阶段结束, 重新进入全开模式。
流程里面涉及到的概率计算则是基于以下的公式:
$$max(0,\frac{requests-K*accepts}{requests+1})$$
公式中K的默认值是2, 但是可以根据自己的情况进行调整, 降低K值会让客户端更快的进入半开模式, 增加K值则相反。 这个公式十分简单, 计算起来也不复杂, 即使是实时计算, 也不会怎么浪费CPU的性能, 而且Google文档中描述该算法在实际使用效果极为良好, 可以使整体上保持一个非常稳定的请求速率。
关于K默认值为2的官方说明:
一般来说推荐采用K=2,通过允许后端接收到比期望值更多的请求,浪费了一定数量的后端资源,但是却加快了后端状态到客户端的传递速度。
举例来说,后端停止拒绝该客户端的请求之后,所有客户端检测到这个变化的耗时就会减小。另外一个考量是,客户端节流可能不适用于那些请求频率很低的客户端。在这种情况下,客户端对后端状态的记录非常有限,任何想提高状态可见度的手段相对来说成本都较高。
Google Sre对于公式的描述见:https://sre.google/sre-book/handling-overload/#eq2101
中文版见《SRE: Google运维解密》第21章客户端侧的节流机制
4.代码实现
通过分析可以得出Google SRE弹性熔断是根据成功率动态调整的, 实现简单, 让新手简单易懂, 同时可以自动探测服务是否恢复, 也满足了自动化的特点, 所以我采用了该方法实现熔断器。
由于我的框架是支持双工模式的, 所以不是像HTTP/1.0的框架一样使用中间件, 而是重新定义了一个叫处理者的方案, 处理者提供了process_request和process_exc分别处理客户端请求和服务端的异常响应, 我只要统计process_request的调用次数即可得出请求数, 统计process_exc以及process_request的特定异常得出错误数, 并用请求数减去错误数就能得出请求成功数, 其中的特定异常是指框架里面自己封装的status属性值大于等于500的异常。
同时, 框架已经实现了一个窗口统计的类, 我是基于这个类统计的,详见文章:RPC框架编写实践–服务治理的基石,以下是具体的代码实现(最新代码见circuit_breaker.py):
1 | |
- 本文作者:So1n
- 本文链接:http://so1n.me/2021/08/27/RPC%E6%A1%86%E6%9E%B6%E7%BC%96%E5%86%99%E5%AE%9E%E8%B7%B5--%E7%86%94%E6%96%AD%E5%99%A8/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

