RPC框架编写实践--最小RPC框架的依赖
前记
在2019上半年时, 项目需要用到RPC来为不同服务间建立连接, 便开始调研RPC相关的内容, 由于项目本身是基于Asyncio生态的, 所以就开始找基于asyncio生态的RPC框架, 那时候Python上关于Asyncio的RPC框架比较少, 只有一个aiorpc, 它能满足RPC的基本功能, 但缺少了其他的RPC框架带有的服务治理功能(称为服务管理会不会更好点???), 所以在那时候开始, 我就想开始造一个Python Asyncio生态的RPC框架–rap, 这个项目除了满足在任一语言的RPC的功能外(虽然其他语言的没编写…), 还要满足快;核心功能简单;可以单独为python提供高阶功能; 在没其他服务依赖的情况下就能单独使用, 同时又可以通过插件的形式进行功能拓展。
而RPC框架编写实践系列文章是我编写这个框架时的想法和总结。
注:由于用到了
Asyncio所以他有一些利弊
1.RPC框架需要什么
毫无疑问, RPC框架最重要的部分就是RPC, RPC的全称为远程过程调用, 它的本质是客户端把用户的本地调用转化成一个消息, 通过一个连接发送到服务端, 而服务端根据收到的消息进行解析, 并根据消息调用函数再计算结果, 最后把结果返回给客户端, 并由客户端返回给用户的过程。
而RPC框架则是上述调用过程的封装, 使得调用者可以通过RPC框架像调用本地函数一样调用远程的函数, 从而无须关注底层细节。
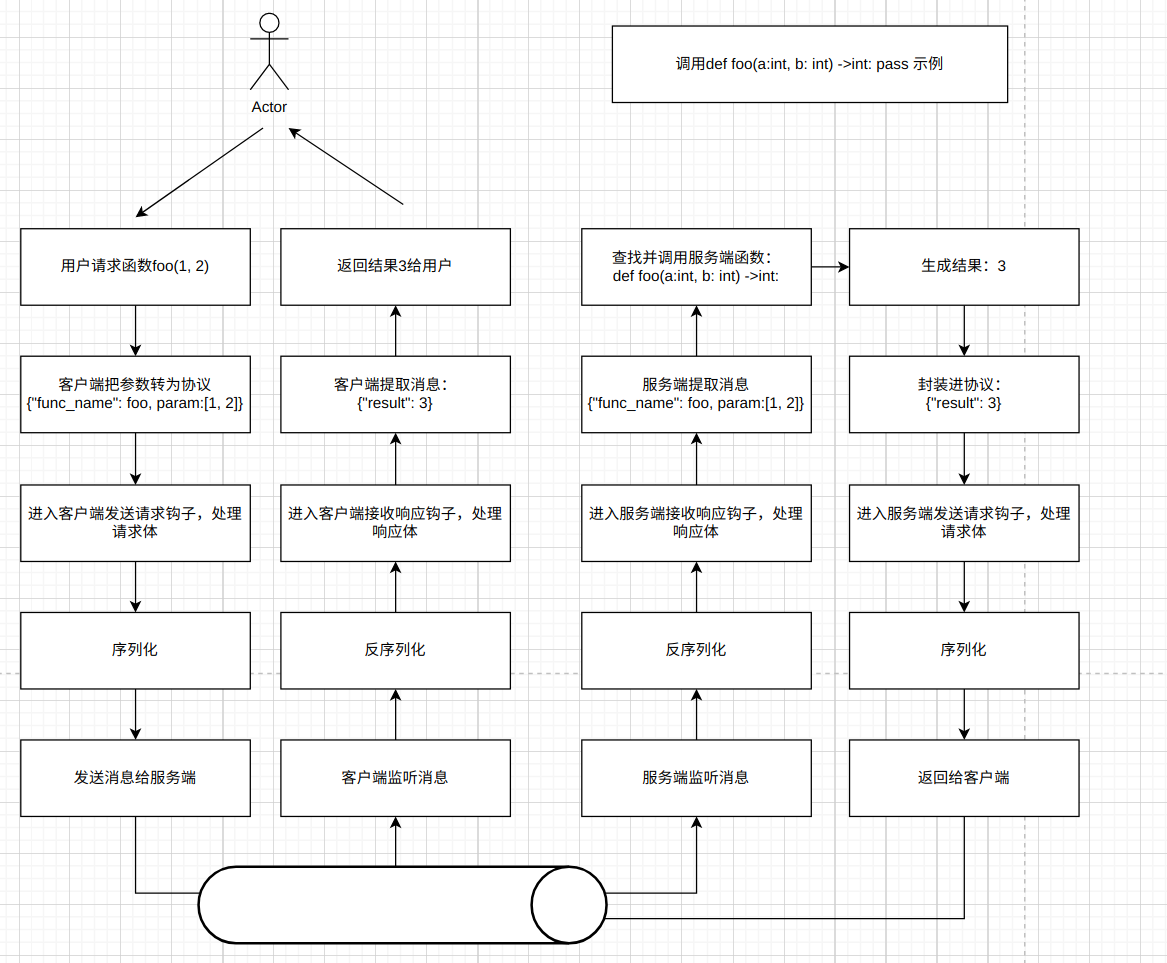
那这个调用过程需要什么呢? 我先设想了一个最简单的业务–用户调用一个foo函数:
1 | |
然后再把这个业务的调用转换为一个设想的RPC请求流程, 便是如下图: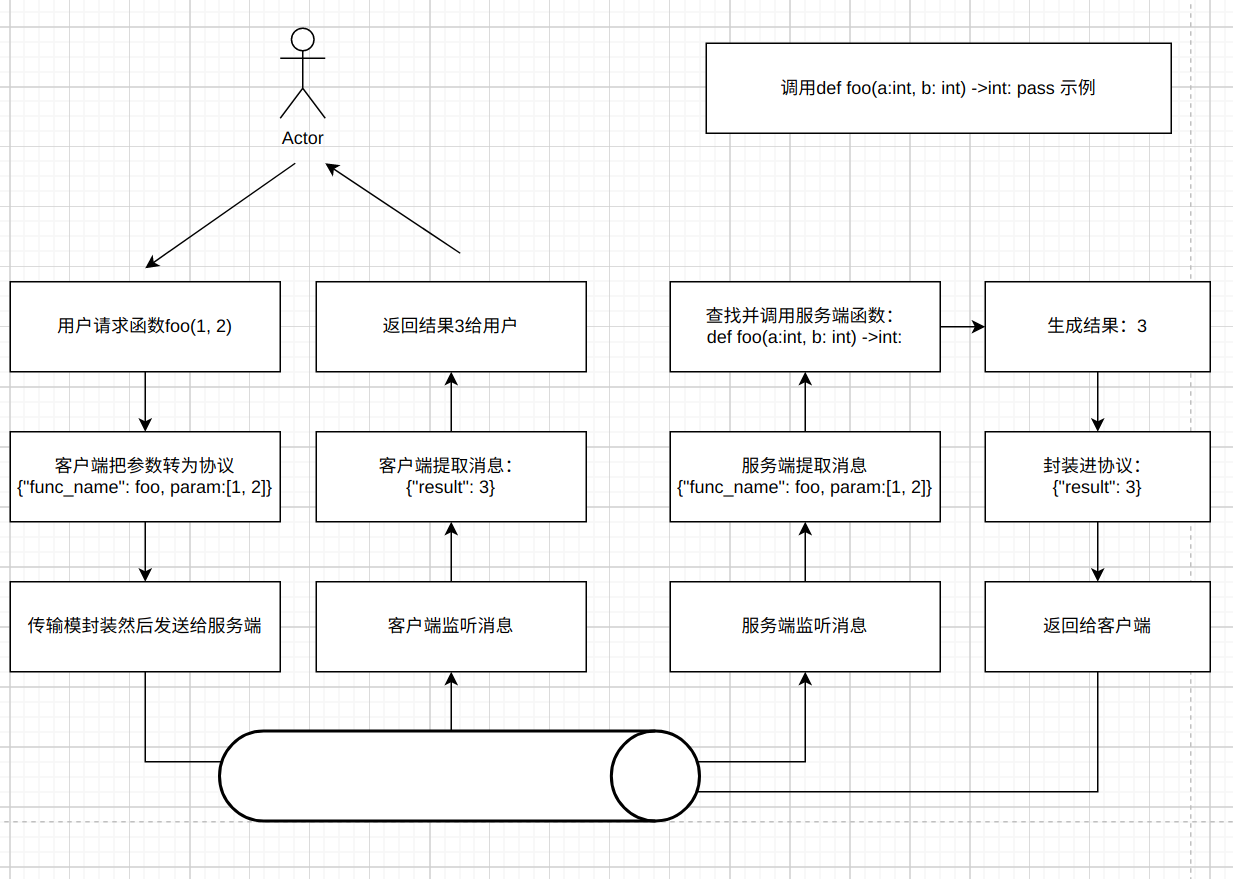 image.png
image.png
可以看出RPC框架需要先把调用的函数签名根据应用层协议进行转换, 通过连接把数据传输到服务端; 服务端在收到请求后根据应用层协议提取信息, 并根据信息查找对应的函数再进行调用, 最后把生成的结果返回给客户端, 由客户端处理后返回给用户。此外, 由于要传输信息, 序列化和反序列化是必不可少的。
从整个流程可以发现, 一个RPC框架起码要拥有应用层协议, 序列化与反序列化, 以及网络传输, 完成了这几点, 就能编写出一个最简单的RPC框架。
2.传输层协议
目前RPC框架的协议一般都是多种协议组合在一起的, 有传输层协议, 应用层协议等等(采用OSI模型分层, 下同)。
目前传输层协议有两种, 一种是TCP, 它传输稳定可靠,能尽量的保障信息不丢包。 而另一种是UDP, 它的可定制性很强, 传输的性能开销小, 但跨网络时会有可能丢包。
而RPC框架要做到适用性和可用性都比较强, 所以目前的RPC框架的传输层协议都是选用了TCP协议(只有用在内网网络的才会去考虑UDP), 而我也选择了TCP作为了我的传输协议。
3.应用层协议
通过调研发现, 目前是开源RPC框架要不就是基于TCP协议来开发自己的应用层协议, 要不就是直接使用HTTP来作为自己的应用层协议。这两种方式都各有各的优势, 选用HTTP作为应用层协议, 就能拥有成熟的生态,可以使用Nginx等中间件, 但是HTTP请求会传输很多字段, 有些字段可能是永远都用不到了,会浪费传输性能, 而选择了自己定制应用层协议, 则不能使用一些成熟的中间件, 但能尽量的使请求体保持简单, 在经过综合考虑后, 我选择了自己定制应用层协议。
在定制应用层协议之前, 需要先想清楚需要基于应用层协议来实现哪些功能,在查阅了一些RPC框架后, 我确定了几个基本的功能:
one-by-one形式的收发消息: 这个功能用于最基础的收发消息。- 双工形式的收发消息: 目前市面上的RPC框架都支持该类型的消息, HTTP也通过WebSocket来支持双工收发消息, 我也想让我的框架支持这种消息, 并且命名为
Channel - 控制连接状态的消息: 为了让连接保持稳定以及及时发现错误, 需要通过
Keep-Alive机制来保活, 而这类消息是独立在用户调用的消息之外的。 - 加快传输速度: 由于RPC框架会承担很大的流量, 同时要为用户保障性能和足够低的响应时间, 所以就需要尽量的加快传输速度, 同时也不要增加太多系统占用。
确定好了基本功能后就可以开始制定协议了, 好的协议必须拥有良好的拓展性和简洁性, 由于我也是第一次订制私有协议, 还在探索中, 所以就从HTTP协议里面吸取一些灵感(少部分从AMQP协议吸取灵感)。
首先是HTTP/1, 也就是用得最多的HTTP请求形式–one-by-one, 这种请求只会请求一次响应一次, 如果没有进行优化, 每次请求都会经历创建TCP, 进行请求, 读取响应,销毁TCP四个阶段, 而TCP的创建和销毁是非常浪费性能并且会增加很多时间。 所以到了后面HTTP就开始支持连接复用, 也就是持久化连接, 这种方式可以让客户端对同一域名长期持有一个或多个不会用完即断的TCP连接, 典型的做法就是客户端维护一个FIFO队列, 在每次取完数据之后一段时间先不自动断开连接, 而是放回队列里,以便在获取下一个资源时直接复用,省去了TCP创建销毁的成本。
但是, 连接复用这一技术并不完美, 它最明显的副作用就是队首阻塞的问题, 比如有两个请求A和B,他们使用了同一个TCP连接, 当A请求发送后且对应的服务端一直没有响应时, B请求就得一直等待, 直到TCP连接收到了A请求的响应。 实际上TCP连接是可以近乎同时发送A请求和B请求, 也可以近乎同时收到A响应和B响应, 但是HTTP/1.0并无法识别这个响应是那个请求产生的。
到了HTTP/2, 它就开始利用TCP的流机制, 在HTTP/2中, 帧是最小粒度的信息单位,它可以用来描述各种数据,譬如请求的Headers、Body,或者用来做控制标识,譬如打开,关闭连接等。 同时每个帧都附带了一个流ID以标识这个帧是属于哪个流, 这样子客户端就可以根据标识ID将不同的响应与请求一一配对,从而解决了无法识别同一连接在同一时刻收到两个请求的问题。 这个设计的HTTP/2的最重要的技术特征之一,它被称为HTTP/2多路复用。
在习惯
one-by-one后初识HTTP/2的多路复用可能很难转变过来, 我在理解的时候, 会把一个HTTP连接比作一条河流, 每个请求相当于一个货物, 发送者发送货物时会给货物打上自己的标记, 然后交由船来运输, 有的船都会载上货物从A地驶向B地, 有的船会载上货物从B地驶向A地, 他们不用关心货物是什么, 而货物都有自己的一个标识, 码头根据标识就可以知道这个货物是那个请求发出, 要收回什么请求。
从HTTP协议的迭代史可以发现, HTTP是在逐渐的提高对TCP连接的复用, 从而减少资源的浪费, 而对于RPC来说, 它天生需要极好的传输性能和较少的机器成本开销, 同时从客户端建立连接时创建的连接会一直存在, 直到双方有一方出现异常等原因才会断开连接, 所有请求通过连接来传输数据, 场景十分简单, 所以它会更需要多路复用。
那要怎么实现多路复用呢? 大概步骤如下:
- 请求函数在进行请求之前会分配到一个唯一的标签, 然后会通过标签在一个共享容器创建一个空位置等待数据的到来, 接着会按照协议把标签放到请求体里面, 并发送给服务端。
- 服务端收到请求生成响应时就会按照协议把该标签放入到响应体中并返回数据到客户端的连接。
- 客户端的连接在创建的时候会启动一个后台任务, 这个任务会一直从连接读取数据, 如果有数据来了, 就会解析数据, 根据协议提取标签并把数据放到容器的指定位置, 如果没有找到对应的位置则需要丢弃数据(证明这个连接没发送过该标签的数据)。
- 请求函数从空位置中等到数据的到来, 会返回给用户, 并且删除该位置, 防止内存溢出。
以下是简单的伪代码说明(具体源码可以见:https://github.com/so1n/rap/blob/master/rap/client/transport/transport.py):
1 | |
了解完了多路复用可以发现, 协议中有一个必不可少的字段, 这个字段就是上面所说的消息标签, 这个字段我在协议中命名为相关id, 此外在了解连接复用的时候, 我也顺便了解了HTTP协议的设计, 通过HTTP协议的设计, 我从中提取了几个字段, 最后整合成以下几个字段:
- 消息id: 这个消息id是单调递增的, 可以让双方知道是否有消息重发以及为以后功能做拓展。
- 协议版本: 一般协议都会随着迭代而发生变化, 所以需要一个字段来标识当前的协议版本是哪个, 方便客户端和服务端针对性的识别。同时, 这个字段应该尽量的处在协议的最前面, 因为它是最不可能发生更改的。
- 消息类型: 从HTTP/2的设计可以看出, HTTP/2会单独传送一个请求来控制打开和关闭连接, 此外还会发送
keep alive请求来保持与服务端的连通, 这类请求与普通的one-by-one请求是不一样的。 而且我还希望有类型websocket的场景, 他也与上述两种请求类型不一样的, 所以就需要一个字段来区分他们的类型, 具体的类型如下:event: 这类消息用来控制传输的连接状态和行为, 这类请求允许客户端和服务端都可以收发,比如ping,pong以及确定连接生命周期的declare,msg,drop等等。msg: 这类消息跟传统HTTP/1很像, 也是最经典常见的消息模型,他只接受一发一收,收发的相关id必须一致channel: 这类消息可以类似于Websocket, 是一种可以同时双向收发的消息模型, 也可以改为一发多收或者多发一收, 完全由实现者自己定义。
- 相关id: 这个值的存在就是为了实现上面所说的多路复用, 客户端通过相关id可以找到这个响应是哪个请求的响应。
- 目标url: 这个字段就像HTTP的URL一样, 客户端可以通过url找到服务端对应的路由函数。 不过对于RPC来说url没必要那么长, 一般rpc的目标函数匹配都是通过哪个组, 组里面的哪个函数来查找, 所以url会以
/{group}/{func name}来表示。 - header: 协议的设计不仅要精简, 也要容易拓展, HTTP中的header就很方便用户自定义拓展, 所以我也采用了header字段
- body: 该字段存的是响应体和请求体,也是类似于HTTP.body。
- status code: 该字段跟HTTP一样,只有响应的时候才有的, 小于300的为正常请求, 大于300小于400的为功能上的拓展, 大于400小于500的为异常请求, 大于500则是有破坏性的异常。
需要的字段确定完后, 就可以排列成一个协议, 按照简单和变动比较少的放前面的原则, 最终请求消息协议定义为:
1 | |
响应消息协议则定义为:
1 | |
现在, 应用层协议终于定制完了, 但是还是不够, 因为程序里的在读写的协议实际上还都是存在内存中的数据结构或对象, 然而网络传输只传输二进制编码, 同时不同的语言中的对象类型的表达方式是不一样的, 所以需要一种通用的且能把数据结构或对象转换为二进制编码的方法–序列化, 以及反向操作–反序列化。
4.序列化与反序列化
序列化与反序列化是网络传输中的重中之重, 本质上也是一个协议, 大概处于OSI模型的表示层。
一般人接触最多的序列化协议是Json, 它通用, 成熟, 调试起来也非常方便, 但是占用空间大, 序列化时也会比较久, 从而影响了传输的性能, 所以我并没有挑选Json作为我的序列化协议(之前在使用starlette框架时知道Python中有ujson和ojson两个库, 它们本质上也都是Json, 但是通过特定的方法减少了序列化时对CPU的性能影响)。
但是我没有能力开发一个成熟稳定的序列化协议, 所以只能在开源协议中挑选, 开源的序列化协议每种都有优点和缺点,它们在设计之初有自己独特的应用场景, 而在挑选序列化协议时, 我根据以下几点进行分析:
- 通用性: 也就是这种协议是否支持跨平台, 跨语言, 不过不支持, 那通用性就会大大降低。
- 流行性: 流行性主要是用的人多不多, 如果用的人不多, 资料会比较少, 解决坑的速度也会变慢。
- 成熟性: 协议是否成熟, 部分序列化协议诞生的时候性能很强, 但功能不多, 同时也不稳定, 不安全, 如果想要做一个稳定的RPC框架, 使用的序列化协议也必须成熟稳定。
- 空间占用: 如果序列化后占用的空间还是比较多, 会增加网络的传输压力, 减少响应时间。
- 时间占用: 如果序列化协议比较复杂, 那解析时间就会比较久, 占用更多的CPU时间, 由于我使用
Python asyncio生态进行开发, 复杂的协议会导致占用CPU时间比较多, 会降低QPS, 所以这类协议不能挑选。
除此之外还有一个是可读性, 人们容易阅读可读性高的序列化协议, 这样的话调试会十分方便, 但增加可读性必定会导致空间占用大, CPU解析时间久, 所以这一特性不纳入我的考虑范围内。
在经过寻找后, 我发现了msgpack这个序列化协议, 它是一个二进制的Json序列化协议, 与Json很像, 但是还是有一些区别, 如下图: uTools_1629389662645.png
uTools_1629389662645.png
这是官网的一个截图, 它介绍一个数据结构序列化后Json和msgpack的占用空间大小和结果, 可以看出它针对网络传输进行了设计, 序列化的结果本身非常的紧凑, 体积减小了很多, 这样可以减少网络传输的流量, 提高了传输的性能, 同时通过它的文档了解到它的使用方法跟Json差不多, 对使用者而言它的使用方法跟Json差不多, 没多少学习成本, 对于我的需要来说简直是完美搭配的。
对于序列化的一些见解, 以及一些序列化的对比可见序列化和反序列化
maspcak基准测试可以见:https://github.com/alecthomas/go_serialization_benchmarks 或者是:https://github.com/endel/msgpack-benchmark
5.总结
调研完了传输协议, 序列化协议, 以及定制好了自己的传输协议后, 就可以开始写一个最简单的RPC框架了, 但是展示所有代码会占用大量篇幅, 所以这里会以图展示一个简单的请求流程, 首先是连接的生命周期流程: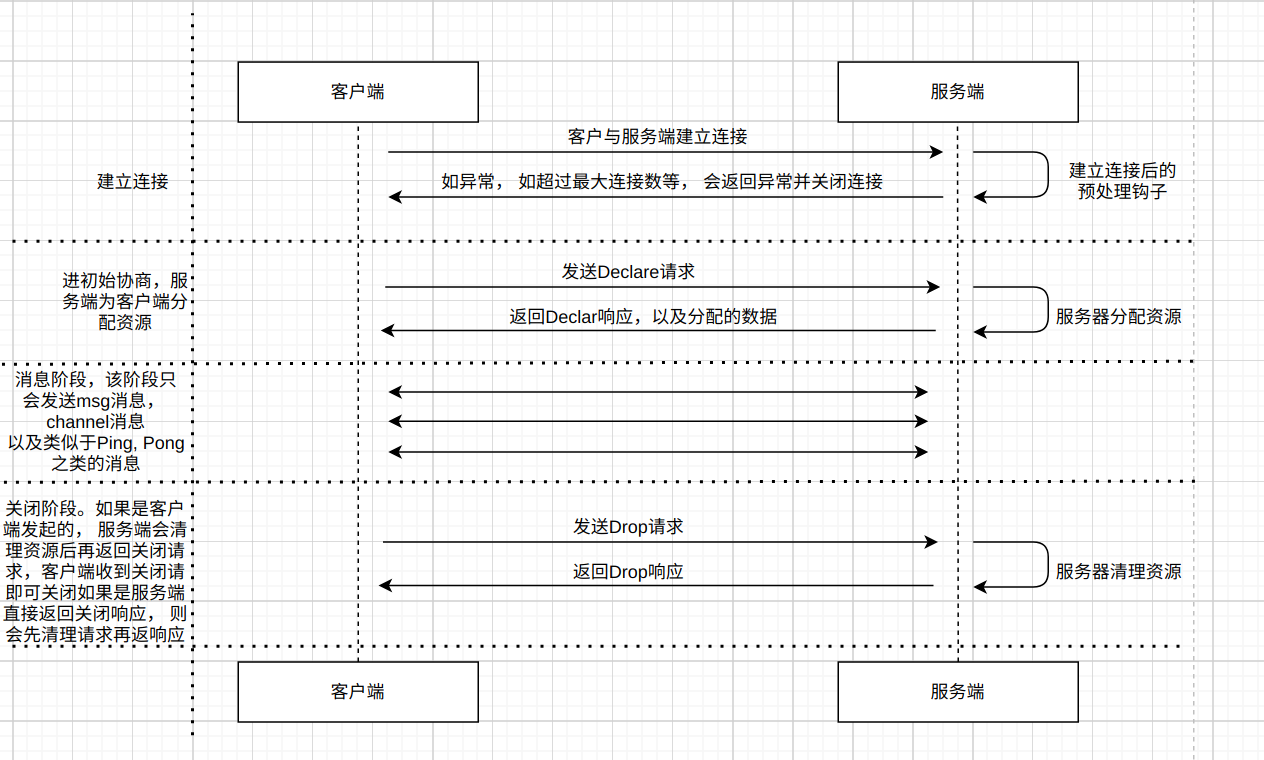 image.png
image.png
然后是每个请求的流程(与一开始构想的流程很像):image.png
从图里可以看出, 图里除了上面描述的东西外, 还多了一些钩子, 这是因为图里所示只是完成一个最基本的RPC框架, 它只满足了最简单的远程过程调用功能。 但是RPC涉及到了网络传输, 有了很多不确定的因素, 所以框架还需要一些服务治理的相关功能, 而这些功能大部分将通过钩子进行拓展, 后面将慢慢介绍这些服务治理的相关功能, 有些是单独出现, 有些是组合出现。
- 本文作者:So1n
- 本文链接:http://so1n.me/2021/08/19/RPC%E6%A1%86%E6%9E%B6%E7%BC%96%E5%86%99%E5%AE%9E%E8%B7%B5--%E6%9C%80%E5%B0%8FRPC%E6%A1%86%E6%9E%B6%E7%9A%84%E4%BE%9D%E8%B5%96/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

