在网上发现了wxpy这个库,可以调取一些微信API来玩转微信,本文主要是在提取微信好友数据
Python玩微信(1):初探wxpy 1.前期准备 wxpy项目主页 里面有它的相关介绍pyecharts项目主页 ,是python与百度echarts的桥梁,我用来做数据分析
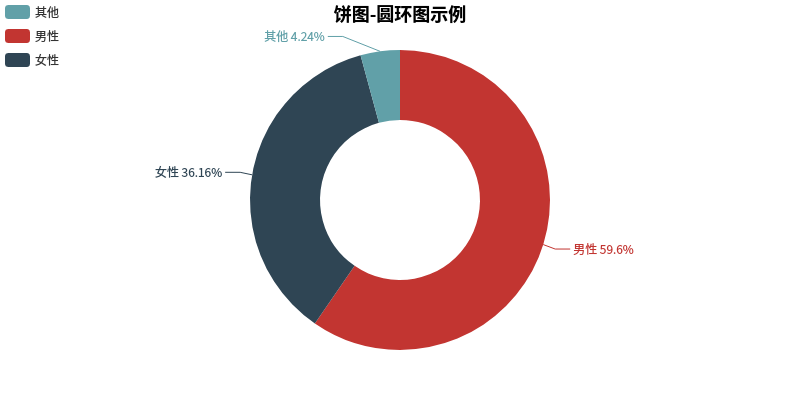
2.查看微信好友男女比例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from wxpy import *from pyecharts import PieTrue ) False ) 0 for i in friends[1 :]: if sex == 1 :1 elif sex == 2 :1 else :1 len (friends[1 :]) "男性" ,"女性" ,"其他" ]float (male),float (female),float (other)]"饼图-圆环图示例" , title_pos='center' )"" , attr, v1, radius=[40 , 75 ], label_text_color=None , is_label_show=True ,'vertical' , legend_pos='left' )"sex.html" )
结果输出如图enter description here
3.查看好友地区分布 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from wxpy import *from pyecharts import Map'市' def s (x ):return x+bTrue )False ).search(province = '广东' )for f in friends :map (s,citys)list (r)for i in cityss:'市' )for value, attr in a.items():map = Map("广东地图示例" , width=1200 , height=600 )map .add("" , attrs, values, maptype='广东' , is_visualmap=True , visual_text_color='#000' )map .render("city.html" )
数据呈现如下:enter description here
4.查看好友签名,并利用jieba分词,再制作成词云 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from wxpy import *import reimport jiebaimport matplotlib.pyplot as pltimport WordCloudimport PIL.Image as Imagebot = Bot(cache_path = True)friends = bot.friends(update=False) male = female = other = 0 signatures = []in friends:signature = i.signature.strip().replace("span" , "" ).replace("class" , "" ).replace("emoji" , "" )rep = re.compile("1f\d.+" )signature = rep.sub("" , signature)text = "" .join(signatures)wordlist_jieba = jieba.cut(text, cut_all=True) wl_space_split = " " .join(wordlist_jieba)my_wordcloud = WordCloud(background_color="white", max_words=2000, max_font_size=1000, random_state=42, font_path='./hanyi.ttf').generate(wl_space_split) "off" )
结果显示如图:enter description here

 enter description here
enter description here enter description here
enter description here enter description here
enter description here
