前记 在使用FastAPI/Starlette进行大文件处理路由开发时,有可能会发现路由的响应时间会比其他框架开发的路由还要慢,而这跟Starlette的设计有关。
1.上传文件 在FastAPI的官方文档介绍了上传文件的方法时,只介绍了UploadFile对象的使用,而在Starlette官方文档中除了介绍UploadFile对象的使用外,还介绍了处理文件流的Stream方法。由于FastAPI的各种网络处理都是基于Starlette的,所以FastAPI可以同时使用这两种方法来接收客户端上传的文件,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import timefrom fastapi import FastAPI, UploadFile, Request@app.post("/uploadfile/" async def create_upload_file (file: UploadFile ) -> dict:len (await file.read()))return {"filename" : file.filename}@app.post("/streamfile/" async def create_file (request: Request ):list [bytes ] = []async for chunk in request.stream():len (chunks))return request.headers.get("filename" )import uvicorn
这两种方法在FastAPI中最主要的差别是FastAPI的OpenAPI能够支持UploadFile对象,而Stream则不支持。此外还有一个不容易被发现的差别–他们在处理大文件的性能有明显的差异,比如下面这个例子,首先是在当前路径下创建两个文件,他们的大小分别为1MB和10MB:
1 2 dd if =/dev/zero of=file_1mb bs=1024B count=1024if =/dev/zero of=file_10mb bs=1024B count=10240
通过ls命令可以看到他们一个文件大小为1M,另一个为10M:
1 2 3 4 ls -alh
在文件创建完毕后,先在终端启动FastAPI服务,并向streamfile和uploadfile接口各发送两个请求,一个请求的文件大小为1mb,另外一个请求的文件大小为10mb,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 'POST' \'http://127.0.0.1:8000/streamfile/' \'accept: application/json' \'Content-Type: multipart/form-data' \'file=@file_10mb' 'POST' \ 'http://127.0.0.1:8000/uploadfile/' \'accept: application/json' \'Content-Type: multipart/form-data' \'file=@file_10mb' 'POST' \'http://127.0.0.1:8000/streamfile/' \'accept: application/json' \'Content-Type: multipart/form-data' \'file=@file_1mb' 'POST' \ 'http://127.0.0.1:8000/uploadfile/' \'accept: application/json' \ 'Content-Type: multipart/form-data' \'file=@file_1mb'
接着再切回到运行FastAPI服务的终端,通过日志可以发现对于1MB文件的请求,他们的响应时长是差不多的,而对于10MB文件的请求,Stream的响应时长却只有UploadFile的一半:
1 2 3 4 5 6 7 8 9 10 "POST /streamfile/ HTTP/1.1" 200 OK"POST /uploadfile/ HTTP/1.1" 200 OK"POST /streamfile/ HTTP/1.1" 200 OK"POST /uploadfile/ HTTP/1.1" 200 OK
造成这个差别的原因是UploadFile对象中使用到的file为Python的SpooledTemporaryFile,同时设置了max_size为1MB。 在这个配置下,UploadFile会持续的接收文件流并交给SpooledTemporaryFile处理。 当接收的流大小小于1MB时,流的数据是存放在内存中,当接收的流的大小超过了1MB时,才会把位于内存的文件转移到硬盘中,而且后续接收的所有流都会写入到硬盘中。
这也意味着Starlette在接收文件时,如果文件的大小小于1MB,那么文件就会存在内存之中,如果文件大于1MB,那么文件会写入到硬盘中。所以对于小于1MB的文件,UploadFile不会涉及到IO操作,而对于大于1MB的文件,UploadFile在写入数据以及路由函数调用read方法时都会涉及到IO操作,最终,整个路由的执行时间会变慢了一些,具体原理如图:1730639563221SpooledTemporaryFile_With_Web.png
图中的逻辑名为假脱机策略,通过该策略可以有效的防止用户上传大文件导致挤爆机器内存而无法继续提供服务,但是也因此产生了多次IO调用从而导致了处理上传文件的效率变得低效。
1.2.解决方案 前面说到,使用UploadFile上传大文件时速度比较慢的原因是UploadFile在处理大文件时会涉及到文件的IO处理,如果把这个IO处理的影响给移除掉,那么就没有性能问题了。
1.2.1.修改max_file_size配置参数 适用场景:机器内存比较大,上传的文件频率不高但却对性能有明显的需求。
通过修改max_file_size参数的大小,可以防止SpooledTemporaryFile把文件从内存写入硬盘,从而移除了IO处理的影响,修改方法如下:
1 2 3 from starlette.formparsers import MultiPartParser20 * 1024 * 1024
上述方法把文件大小的判断改为20MB,这个参数大小可以根据自己的业务进行判断,不过需要注意的是,如果这个接口使用很频繁,或者用户上传的文件比较大时,可能会让系统的内存挤满,从而导致程序OOM。
1.2.2.修改临时目录 适用场景:只接收客户端上传的文件并进行存储,不会进行其他处理。
服务端接收文件一般有两个需求,一个是处理文件,另外一个是存放文件。如果当前的需求是为了存放文件,那么可以通过该方法更改保存的临时目录,修改方法如下:
1 2 3 4 5 6 7 8 9 import tempfile"path/to/tempdir/here" from starlette.formparsers import MultiPartParser0
这样一来就等于把保存文件这一个功能交给了UploadFile对象处理,也是达到了减少额外IO处理的影响。
1.2.3.重新实现流处理 适用场景:不考虑FastAPI的OpenAPI功能, 考虑到需要尽量少的使用内存,同时还需要在程序中处理文件流。
在前面介绍的FastAPI两种接收方法中,除了UploadFile外,还有一种名为Stream的方法,通过Stream实时读取数据并写入文件或者进行实时的流处理也能减少IO的影响。不过该方案需要自己去解析流,直接保存流内容到文件中容易导致文件无法打开,好在multipart已经提供了一个很好的解析器了,只需要稍微修改就可以实现流的解析,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from fastapi import FastAPI, Requestfrom multipart import PushMultipartParser, MultipartSegment, parse_options_header@app.post("/streamfile/" async def create_file (request: Request ):"content-type" )assert real_content_type == "multipart/form-data" str = "" int = 0 with PushMultipartParser(boundary_dict["boundary" ]) as parser:while not parser.closed:await stream_gen.__anext__()for result in parser.parse(chunk):if isinstance (result, MultipartSegment):f"== Start of segment: {result.name} " )if result.filename:f"== Client-side filename: {result.filename} " )for header, value in result.headerlist:f"{header} : {value} " )elif result: len (result)else : f"== End of segment" )return {"filename" : filename, "length" : file_length}import uvicorn
Note:
python-multipart有点鸡贼, 没有讲究先来后到的原则,直接使用了multipart的包名,如果你安装了python-multipart且它的版本小于0.0.13,那么上述代码可能无法正常运行。通过魔改,也可以定义一个类似于UploadFile的对象,同时又支持在OpenAPI展示。
2.大文件下载
Note: 本章节不考虑通过程序在内存生成数据并以文件形式返回给客户端等文件不存在于硬盘的场景,比如拉取数据库的数据,然后以文件响应的形式返回给客户端。
目前大部分开发者对大文件下载的性能要求并不大,所以Starlette以及Sanic等开发者并没有完善这个功能的想法,然而在进行测试时可以发现他们的性能都比较差。如下测试,由于FastAPI和aiohttp的static路由都是使用了各自的FileResponse,所以我使用了他们的static路由进行测试,首先是把上述的file_1mb和file_10mb文件移动到当前目录的static子目录中,然后创建两个文件,一个文件存放FastAPI的代码,如下:
1 2 3 4 5 6 7 8 from fastapi import FastAPIfrom fastapi.staticfiles import StaticFiles"/static" , StaticFiles(directory="static" ), name="static" )import uvicorn
另外一个存放aiohttp的代码,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import asynciofrom aiohttp import web"/static" , "./static" )def main (port=8000 ):if __name__ == '__main__' :
接下来,使用ab命令进行压测:
1 > ab -n 1000 -c 100 http://127.0.0.1:8000/static/file_10mb
具体数据就不贴出来了,只贴QPS的数据,通过如下数据可以发现aiohttp每秒处理的请求数量是FastAPI的5倍:
他们的性能差别为何如此之大呢?原因在于他们的FileResponse实现,首先是Starlette的FileResponse,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class FileResponse (Response ):async def __call__ (self, scope: Scope, receive: Receive, send: Send ) -> None :await send("type" : "http.response.start" ,"status" : self.status_code,"headers" : self.raw_headers,if scope["method" ].upper() == "HEAD" :await send({"type" : "http.response.body" , "body" : b"" , "more_body" : False })else :async with await anyio.open_file(self.path, mode="rb" ) as file:True while more_body:await file.read(self.chunk_size)len (chunk) == self.chunk_sizeawait send("type" : "http.response.body" ,"body" : chunk,"more_body" : more_body,if self.background is not None :await self.background()
在这段源码中,大部分都是与ASGI协议设计相关,只要中间的才是正直传输文件的逻辑(从注释点开始),可以看到FileResponse的主要工作原理是通过anyio.open_file打开文件,并读取文件的内容后再以ASGI协议发送到ASGI服务器。
而AioHTTP有所不同,它的FileResponse主要源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class FileResponse (StreamResponse ):async def _sendfile_fallback ( self, writer: AbstractStreamWriter, fobj: IO[Any], offset: int , count: int ) -> AbstractStreamWriter:await loop.run_in_executor(None , fobj.seek, offset)await loop.run_in_executor(None , fobj.read, chunk_size)while chunk:await writer.write(chunk)if count <= 0 :break await loop.run_in_executor(None , fobj.read, min (chunk_size, count))await writer.drain()return writerasync def _sendfile ( self, request: "BaseRequest" , fobj: IO[Any], offset: int , count: int ) -> AbstractStreamWriter:await super ().prepare(request)assert writer is not None if NOSENDFILE or self.compression:return await self._sendfile_fallback(writer, fobj, offset, count)assert transport is not None try :await loop.sendfile(transport, fobj, offset, count)except NotImplementedError:return await self._sendfile_fallback(writer, fobj, offset, count)await super ().write_eof()return writer
通过源码可以知道,FileResponse的主要工作原理是先通过_sendfile的loop.sendfile方法尝试发送文件,如果发送失败,则使用_sendfile_fallback发送数据。_sendfile_fallback发送数据的逻辑与Starlette的FileResponse类似, 都是先打开文件,然后一批一批的通过网络传输给客户端。
经过对比可以发现AioHTTP与Starlette最主要的区别是AioHTTP比Starlette多了一个loop.sendfile的方法,这个方法就是AioHTTP大文件下载速度快于FastAPI的秘诀。loop.sendfile方法是os.sendfile的异步方法,它是Linux零拷贝的一个API调用,零拷贝与普通的文件读取并下载文件有些区别,如下图:1731142932157diff-large-file-download.png
Note:
那loop.sendfile的性能如此的好,其它框架为何并不感冒呢,主要是有以下几个原因:
1.Windows系统并不支持零拷贝
2.uvloop并不支持loop.sendfile方法(uvloop #228 ),如果Web框架支持sendfile的调用会违背了自己所声明的统一性,见sanic issue #2527 。(其实他可以弄成跟AioHTTP一样的设计的 - -)。
3.ASGI框架实现过于麻烦, 需要在ASGI协议传递较多的参数,影响后期的维护,见uvicorn #1210 以及starlette #1288
4.以RUST实现的ASGI服务器在传递文件描述符时,需要进行跨语言序列化,在不好维护的基础上还会引起性能损耗(btw,这是ASGI设计时没有考虑多语言的问题了,导致一堆C库的大佬抨击,比如uWebSocket)
2.2.解决方案 如果真的对大文件下载的性能有要求,那么有如下三个解决思路:
1.改用AioHTTP处理文件下载。
2.合并uvicorn和starlette中别人提交的零拷贝处理相关的代码。
3.如果API服务与Nginx服务在同一台机器上,那么可以通过Nginx的X-Accel-Redirect来委托Nginx提供高性能的文件下载服务。
第二个方法以后有机会再讨论,这里简单的介绍一下Nginx方案的使用方法。在这个方案中API服务器只需要处理用户的鉴权等下载文件之前的操作,并在最后返回一个带有X-Accel-Redirect的空响应即可,具体逻辑如下:1730910928548Nginx-large-file-download.png
为了实现这个逻辑,需要先配置一下Nginx,具体的配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 upstream api_backend_hosts {server 127.0.0.1:8000 ;keepalive 10 ;server {listen 80 ;server_name _;charset utf-8 ;location / {proxy_pass http://api_backend_hosts;proxy_http_version 1 .1 ;location /private_files/ {alias /home/server/private_files/
接着再创建一个FastAPI服务,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from fastapi import Response, FastAPIasync def file_route (file_name: str ) -> Response:"X-Sendfile" ] = f"/private_files/{file_name} " return resp"/api/file/{file_name}" , file_route, methods=["GET" ])if __name__ == "__main__" :import uvicorn
在运行Nginx和API服务后,只需要把文件放置到机器中的/home/server/private_files文件夹中,就可以通过Nginx和API服务完成大文件下载的功能,他们的性能还是杠杠的。
附录 目前Asyncio生态中有多个文件处理的库,如果你真的很在意不同库对文件处理大小的性能差异,那么你可以关注此issue 的相关讨论,最终你会发现通过asyncio.thread去调用同步方法的性能是最好的。
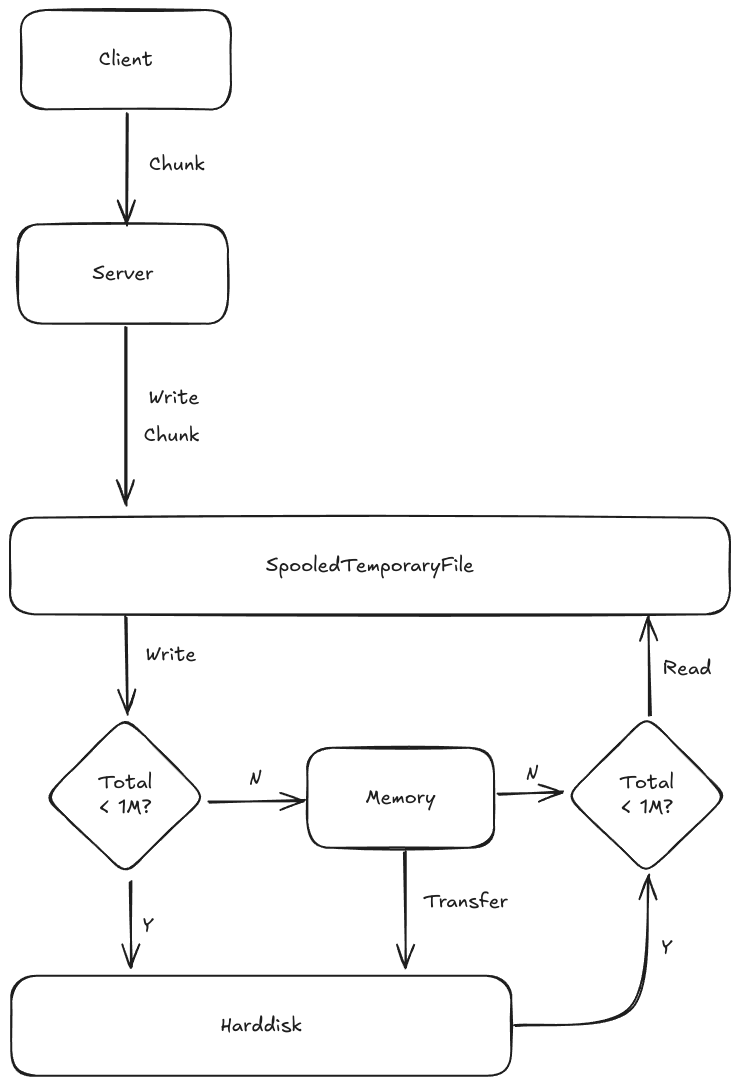 1730639563221SpooledTemporaryFile_With_Web.png
1730639563221SpooledTemporaryFile_With_Web.png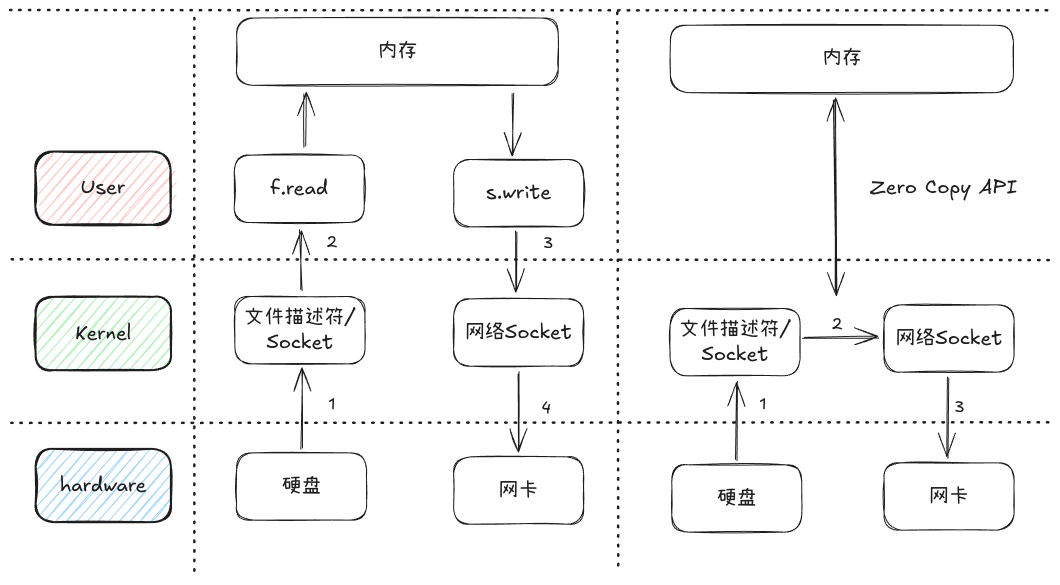 1731142932157diff-large-file-download.png
1731142932157diff-large-file-download.png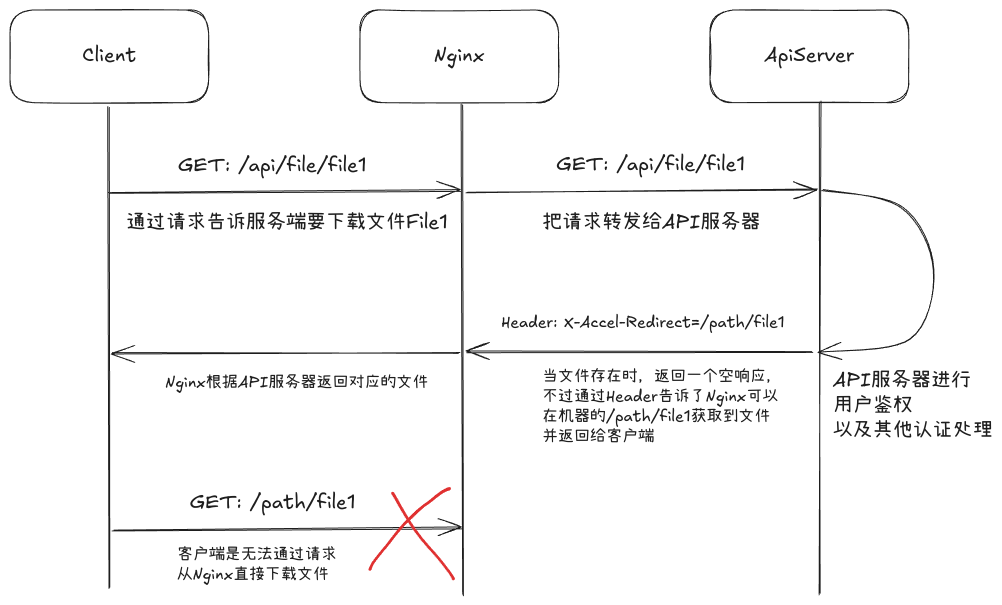 1730910928548Nginx-large-file-download.png
1730910928548Nginx-large-file-download.png
