
Python Asyncio 之常见的三个坑
前记
Python Asyncio是一个用户态协程的实现,没有任何系统级的调度干扰,这意味着它能更快的被调度,但是由于Asyncio是后面才被加入到Python中,所以带来一些不方便的使用和容易踩坑的用法。
1.不同事件循环问题
在asyncio诞生初期,loop.get_event_loop的设计不是很友好,需要多次调用才能知道当前的事件循环已经在运行以及获取到对应的事件循环,如下代码:
1 | |
通过代码可以看到,在Python3.7之后只需要调用asyncio.get_running_loop方法则可以判断当前是否有事件循环运行,也可以获取到事件循环。而在Python3.6之前需要分多步走,于是很多asyncio相关的库都会采用如下用法获取正在运行的事件循环对象:
1 | |
但是这样很容易引发不同事件循环的问题,如下例子:
1 | |
在这个例子中会虚构了一个不可用的客户端–BadClient,它在初始化时会获取或者创建当前的事件循环,并在fake_request这个模拟请求的方法中使用,但是在通过uvicorn运行app并访问路由后可以发现程序会抛出如下异常信息:
1 | |
该信息告知当前程序被连接了两个事件循环,这是一个非常严重的错误。造成这个错误的原因是BadClient在初始化的时候会自动的选择一个事件循环,但是uvicorn在运行的时候会重新为当前程序设置一个新的事件循环,这就导致后续运行路由的事件循环与BadClient并不是同一个事件循环。
这是一个asyncio设计导致的历史遗留问题,好在现在很多库在抛弃Python3.6的支持后就不在__init__方法中进行事件循环的初始化,而是哪里用到了就在哪里获取,保证使用时用到的事件循环会与当前程序的事件循环一致,所以大部分问题都可以通过升级对应的依赖库来解决。
此外,也可以通过延迟加载的方式,使client在uvicorn启动之后再初始化,并绑定到app实例中,如下代码:
1 | |
这样既能解决正常运行时的不同事件循环问题,也能解决测试用例中不同事件循环的问题。
2.阻塞代码问题
Python Asyncio有许多优势,在正确的使用下可以让程序发挥出极高的性能,特别是在使用uvloop后,程序的性能甚至能够媲美node和go的性能。但是由于Python Asyncio的async传染性原因以及Asyncio是后面才加入到Python生态中,导致asyncio有一套与sync相独立的生态。
所以Python虽然有着跟js,dart相似的async,await语法使开发者能更简单方便的进行异步编程,但是仍有一些网络库没有适配asyncio生态而使用者却不知情从而导致代码阻塞的情况。
举个例子,很多新接触的开发者因为FastAPI的便利性选择了FastAPI进行Web开发,大部分路由也会选择用async函数,如下:
1 | |
然而在涉及到外部请求时,很多开发者会选择用requests库,因为它在Python生态中实在是太出名了,于是编写出来的代码可能是这样的:
1 | |
此时的任何库的使用方法都是正确的,使用用浏览器进行请求也可以得出数据,但是通过ab压测出来的数据却是出奇的差,如下是我使用ab进行50个请求,10并发的压测(省略不重要的数据):
1 | |
通过结果可以发现用了12秒才能处理完50个请求,换算出来的QPS只有4左右,这个性能是非常的拉跨的,而造成这个问题的原因是在async路由中用到了阻塞代码导致的。当堵塞代码运行时,整个事件循环都没有机会运行,所以整个程序只能串行的处理所有请求。
在这个示例代码是错误的用到了requests这个库,大部分开发者都知道它不与asyncio兼容,所以可以很快速的定位出来,但是有些库并没有明显的说明,得如何去定位呢?有两种办法,一种是通过使用经验去排查,另一种是通过asyncio的Debug模式。
2.1.使用经验法排查
所谓经验法排查,就是只看代码就知道哪些代码会阻塞Asyncio的运行,而这需要开发者知道Asyncio能调度的对象是什么,因为只有Asyncio能调度的对象才不会阻塞Asyncio的运行。
在Python Asyncio调度原理中介绍过,Asyncio就是一个简单的循环程序,每一次循环执行一件事。当它发现有Handle和TimerHandle两个调度对象中的一个可以运行时,就会把执行权交给调度对象,直到调度对象让步时Asyncio的循环程序才会继续执行,所以当调度对象执行的代码消耗的时间比较久时会阻塞到整个Asyncio的运行进而影响程序的执行性能。但是如果把这些阻塞代码交给非CPU执行,并通过Handle和TimeHandle来告知Asyncio的循环程序自己什么时候可以继续执行什么时候可以让出,那么CPU就能一直执行Asyncio的调度工作,Asyncio就能发挥极其强大的调度性能了,程序也就能够跑的更快。
比如asyncio中的时间处理,它会把时间何时到期的逻辑封装到TimerHandle中,再扔进事件循环中的数据结构–堆,事件循环每次循环时都会获取堆中时间最近的TimerHandle,如果发现确实到期了就马上执行,否则就继续循环,直到到期的TimerHandle可以被执行。asyncio.sleep就是采用这种处理方式,这种方式相比于time.sleep虽然会多费一点CPU,但是在空闲的时候并不会完全占用当前线程的执行,所以Asyncio的事件循环能一直运行着。
而Handle对象也是类似的,只不过它承载的是Task,Future,sock&epoll等事件的处理,不过它们之间的关系比较复杂,如果想具体了解的可以看我之前写的关于Asyncio的文章,它们的简要关系如下图: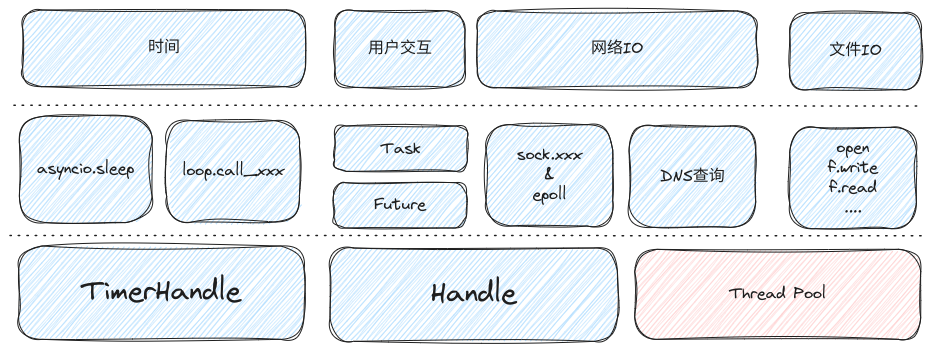 如何正确的使用asyncio-可调度的分类.png
如何正确的使用asyncio-可调度的分类.png
通过图可以发现在使用asyncio提供的方法后大部分的时间,交互,网络IO都不会阻塞到事件循环的运行。
不过网络IO中有一个例外的就是DNS查询,因为DNS查询的方法–socket.getaddrinfo与其他sock的方法是有区别,其它的sock方法都可以异步执行,而它是阻塞执行。这也就意味着在一个线程中,如果执行了socket.getaddrinfo方法就会把整个asyncio的事件循环阻塞住。为此asyncio通过run_in_executor方法来解决这个问题,具体源码如下:
1 | |
通过源码可以看出,在使用asyncio.getaddrinfo进行DNS查询时是会把这个任务委托给给线程池处理,这样DNS查询就不会影响事件循环的运行。不过默认的线程数量是有限的,如果需要更多的线程帮忙工作则可以通过如下方法把Asyncio事件循环的默认线程池调大一些:
1 | |
此外,通过图中还可以发现文件IO也标注了需要通过线程池去运行的,这是因为*unix系统目前并没有一个稳定好用的文件io异步API,所以epoll暂未支持文件IO相关的异步操作,相信再不久的将来可以通过io_uring使用到文件的异步。
Linux中的AIO设计的不好,且不是所有API都是异步的, 如果有兴趣,可以通过[译] Linux 异步 I/O 框架 io_uring:基本原理、程序示例与性能压测(2020)了解
2.2.asyncio debug排查
很显然,经验法排查比较考验开发者的使用经验的技术储备,而且也容易出现漏网之鱼。此外还有一些容易被忽视的场景,比如大消息体的Json序列化或者加解密等费CPU的逻辑代码,如下:
1 | |
这段代码使用到了Asyncio生态的HTTP库去获取一个URL的资源,按照经验法分析,这段代码基本没有什么阻塞Asyncio事件循环的可能性,但是如果这个网址返回了一个巨大的Json内容,那么就有可能因为Json序列化而阻塞到Asyncio事件循环的运行。
这种问题通常都是非常难排查到的,好在Asyncio提供了一个debug选项,通过这个选项可以知道哪些代码有可能阻塞到Asyncio事件循环的运行,如下代码:
1 | |
这个程序会并发执行4个任务,每个任务都是一个协程,分别为t1,t2,t3和t4。理论上它们四个协程能够并行运行的,但是由于time.sleep(1)的存在,会导致一部分时间Asyncio会被time.sleep(1)阻塞着,在运行程序之后可以看到终端打印如下输出(其中每行输出的开头是我手动标识的,用于标识是哪个协程输出的信息):
1 | |
通过输出可以发现,Asyncio能够识别sub_task1和sub_task3都包含阻塞性的代码,sub_task1阻塞了两次,而且它们的阻塞时间都是在1秒左右。
在更进一步分析,并标识了输出信息与协程的关系后可以知道:
- t1协程是直接以
sub_task1开始调用的,所以它一开始就被sub_task1阻塞了。 - t2协程虽然通过
asyncio.sleep休眠了两秒,但这两秒是通过把控制权让步给事件循环的,所以事件循环执行t2的时间是很快的,所以不会发出警告信息。 - t3协程与t1协程类似,都是被
sub_task1函数阻塞了。不过唯一的区别是t3协程的开始函数是sub_task3,所以在输出警告信息时会显示执行sub_task3函数(或者整个协程链)阻塞了1秒。 - t4协程则是采用套娃的模式,在t4协程中会通过
asycniot.create_task方法创建出一个新的协程来执行sub_task1函数,所以此时是有两个协程链,分别为sub_task4开头和sub_task1开头的协程链。其中sub_task4协程链只需要等待sub_task1协程链执行完成,所以不会阻塞事件循环,而sub_task1协程链则与t1协程一样阻塞了事件循环,所以最后asyncio会报sub_task1函数阻塞了1秒。
通过这些分析可以知道,这个示例代码中的阻塞点就是sub_task1函数,不过他只显示哪个协程链有异常,具体哪里有问题还是需要根据经验法继续排查。更多asyncio Debug的开启方式和参数配置可以参考asyncio Debug Mode
协程链这个名字是我取的,实际上每个
asyncio.create_task创建的Task都可以理解为一个任务链,Task会通过await来传递协程的让步和继续点信息,详细可以通过Python的可等待对象在Asyncio的作用了解。
3.少用loop.xxx,多用asyncio.xxx
Asyncio最重要的就是事件循环,所以初期很多方法都是跟EventLoop有关,但是这些方法太底层了,同时又支持一个程序起多个EventLoop,所以对于一个刚接触Asyncio的新手容易因为loop.xxx方法而踩坑。
为了解决这些问题,Python在后续的版本中推出与loop.xxx相对应的asyncio.xxx方法,开发者只要使用这些方法,基本可以避免很多错误的使用事件循环的问题。因为它们在执行的时候都会找到当前运行的事件循环或者初始化一个事件循环,比如开始运行协程程序的方法:
1 | |
现在已经可以使用asyncio.run代替了,如下:
1 | |
asyncio.run不仅使代码更加简便,同时也做了很多额外的工作,比如asyncgen资源的回收,线程池的回收以及防止在同一个线程起多个事件循环等。而与asyncio.run相同的还有asyncio.to_thread,它是loop.run_in_executor的变种版本,但是使用者无需考虑loop对象的使用。
不过在许多asyncio.xxx方法中有一个例外的是–run_coroutine_threadsafe,由于它是负责跨线程的调度,所以无法自动的匹配到正确的loop对象,所以需要手动传递loop对象,如下代码:
1 | |
这段代码是创建一个事件循环并放到子线程中运行,然后在通过asyncio.run_coroutine_threadsafe方法安排子线程的事件循环去执行对应的任务,如果不手动自定事件循环的话,它就只能找到当前主线程的事件循环。
4.总结
由于Asyncio是后面才出现的,且不像go,Dart,js一样隐式的运行事件循环,又使用了async,await的语法,所以导致很容易用错。而gevent不会污染原有代码,只需要注意猴子补丁的使用方法即可,随着使用的时间越来越多,我越觉得gevent才是Python的正确协程之道,不过Asyncio是受官方支持的,后面肯定会越来越好的。
- 本文作者:So1n
- 本文链接:http://so1n.me/2023/12/28/python_asyncio_lib_how_to_use_it_correctly/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

