
如何在FastAPI正确的使用依赖注入
前记
大多数使用静态语言的开发者都知道依赖注入是什么,但是对于使用Python的开发者却很少有机会接触到依赖注入,这是因为不同编程语言的机制导致的,具体可以通过《为何在Python生态很少听说到依赖注入》了解。
时过境迁,由于对Type Hints系统的完善以及大家对工程化的追求,越来越多的Python开发者开始接触依赖注入,相关的依赖注入框架也越来越多,普通开发者也能通过这些框架快速的使用依赖注入。
1.FastAPI中的一些依赖注入的糟糕使用方式
由于AI的火热,很多开发者开始接触Python并使用FastAPI进行后端开发,不过在使用的过程中会认为FastAPI的Depend的依赖注入是万能的。然而FastAPI的Depend并不是一个功能完备的依赖注入实现,这导致很多刚接触的人会错误的使用Depend。
1.1.在任意地方使用Depend
为何Depend不是一个完备的依赖注入实现呢,因为它提供的仅是针对请求资源的依赖注入,请求资源是它的当前上下文,如果离开了这个上下文,那么它将无法正确的运行,如下例子:
1 | |
该例子共分为三块:
- 第一块是
FakerDB,它是一个虚构的数据库类且通过create和get_user_info方法来模拟数据库连接的建立和使用,所以限定了需要先调用create方法进行初始化后才可以调用get_user_info方法。 - 第二块是获取
FakerDB的一个实现,它是一个非常简单的全局单例实现,在第一次调用的时候会实例化FakerDB,并在后续的所有调用都返回同一个FakerDB实例。之所以在get_user_db中进行初始化是为了防止DB和uvicorn在不同的事件循环上运行(虽然FakerDB不会触发这个Bug)。 - 最后一块是与
FastAPI相关的,其中startup_event是FastAPI启动时调用的事件,login是请求命中时调用的路由,该路由只返回用户信息。
此外,示例代码为了使代码逻辑可以复用,startup_event和login函数都通过Depends注入get_user_db函数来获取到FakerDB,然而在运行后示例代码后会发现程序报错了,它的报错信息如下:
1 | |
报错信息提示在执行startup_event函数时,所使用的user_db实际上是一个Depends,所以没有create方法可以使用。
如果是FastAPI的常用者,那么会知道FastAPI规定的Depends只能在路由函数中使用,而这段示例代码错误的在startup事件中使用了Depends,所以代码是无法正常运行的。
而更深层的原因则是和上面所说的一样,Depends只能根据请求资源去进行依赖注入,在无法获得到请求资源的地方,它都无法正确的执行依赖注入。
Note:
FastAPI的startup事件是直接采用startlette的方法而没有进行封装才导致调用失败。如果FastAPI也去修改startup事件的实现,那么它也是能够通过Depends去注入get_user_db函数,但是无法在get_user_db函数通过uid: str = Query()获取到请求的资源。
1.2.使用Depend共享了有限的资源
可以依赖注入的种类有很多,但是如果通过依赖注入共享了有限的资源则会导致系统并发能力受到资源限制。比如在FastAPI文档中出现的一个共享资源示例,其中最关键的代码如下:
1 | |
这段代码在请求命中create_user路由时会通过get_db获取一个连接实例,然后在create_user路由中使用,当create_user路由执行完毕时,get_db会调用db的close方法,这在大多数情况下是没问题的,但是对于那些并发比较高的业务则会导致系统的并发数被连接池限制了,比如连接池的大小设置为100,那么服务的最大并发数也只能为100。
为了能更好的说明这个问题,我把上面的示例代码进行更改,更改完的代码如下:
1 | |
同样的,示例代码也可以分为三部分:
- 第一部分还是
FakeDB,不过它现在不再负责连接的管理,只负责某个方法的实现,在这个示例代码中,它通过get_user_info提供了用户的个人信息数据。 - 第二部分是连接池的实现,这里采用队列来模拟连接池,
get_user_db函数中通过get方法来模拟获取db,并通过put_nowait来模拟把用完的连接返回到连接池中。 - 第三部分则是
FastAPI的组件,其中start_up会在程序启动时初始化Queue并为Queue推了三个FakerDB实例,这意味着连接池的大小为3。而login函数则是通过get_user_db获取db并先打印一条访问日志且通过asyncio.sleep(3)休眠3秒后再返回用户信息。
接下来运行示例的服务端代码,然后在另一个进程运行如下客户端代码:
1 | |
该代码会同时对同一个接口发起5个请求。
当代码运行完毕后,切回到服务端运行示例代码的终端,可以看到如下输出:
1 | |
通过输出结果可以发现,请求0,1,2同时被程序处理,而请求3,4只有在请求0,1执行完毕后才能被程序处理,所以当前路由的并发数只有3,而共享的连接池的数量也刚好为3。
通常情况下一个Web框架可以同时处理海量请求,而造成这一现象的原因则与Depend的实现有关。为了了解这个问题的原因,需要先了解整个请求在FastAPI的执行流程: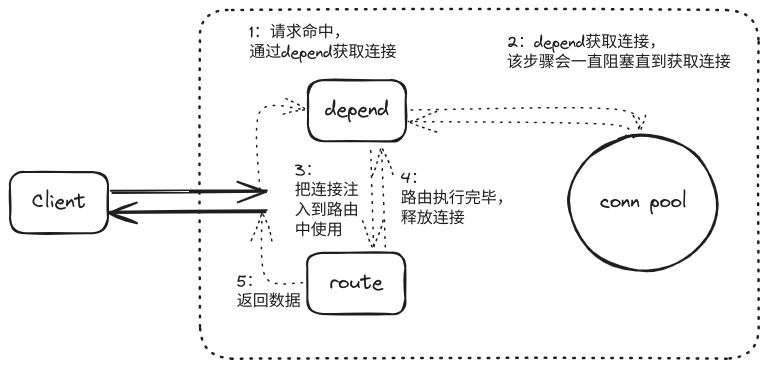 如何在FastAPI正确的使用依赖注入-FastAPI流程图.png
如何在FastAPI正确的使用依赖注入-FastAPI流程图.png
通过流程图可以看出当请求命中路由后,整个处理流程可以分为如下五步:
- 1:
FastAPI会先解析路由需要什么参数,其中uid: int = Query(...)代表从URL中获取uid数据, 而user_db: FakerDB = Depends(get_user_db)则代表通过get_user_db获取连接。 - 2:
get_user_db会通过连接池获取连接,如果没获取到连接则会一直阻塞,只有获取到连接后才会把连接返回给FastAPI。 - 3:
FastAPI从get_user_db获取到连接后会把连接注入到路由中。 - 4:路由使用连接,并在使用完毕后把连接归还给
get_user_db并由get_user_db把连接放回到连接池中。 - 5:路由执行完毕,把数据返回给客户端。
在2-4步骤中,连接会按照一定的顺序流转着,但是连接的总量是一定的,所以当连接池的连接被用尽且有新的请求命中路由时,请求就会堵在获取连接的步骤中,直到有新的连接被归还到连接池后才会继续执行,而这就是共享了有限的资源而导致系统并发数被限制的原因。
2.正确的在FastAPI使用依赖注入
正如《为何在Python生态很少听说到依赖注入》所说的,由于Python本身就是一个大的DI容器,所以使用依赖注入的场景比较少,但随着Type Hint的流行以及工程化思想的流行,越来越多的依赖工具诞生了,具体可以通过awesome-dependency-injection-in-python进行详细的了解,它不仅包括了依赖工具,也包括一些依赖注入的介绍文章。
awesome-dependency-injection-in-python介绍了很多依赖注入的工具,其中returns这个项目是非常好玩的,不过被选择最多的依赖注入工具是python-dependency-injector,因为它提供了很多依赖注入的实现,性能最高,覆盖的功能最全面,对Type hints的全方位支持,且提供了很多WEB框架的示例实现,所以它好用又非常容易入手。为此可以通过DI来解决FastAPI自带的依赖注入大部分都只跟请求相关的问题。
Note:
- 编写这篇文章的提纲时(2022-11),python-dependency-injector已经迭代到4.x版本了,随后项目不再活跃,也没有处理PR,不过在最近这段时间(2023-12),项目的开发者已经在处理
Python3.1.2版本的兼容问题了,也有许多开发者正在申请接手该项目的需求迭代开发。- python-dependency-injector下文简称
DI
DI分为容器–Containers,提供者–Providers,布线–Wiring三个大部件。 其中Containers是所有Providers的集合,可以把它简单的理解为一个Python的模块,而Containers内部的Providers可以认为是该模块内的所有可供外部调用的变量。此外,Containers在初始化的时候会自动解析内部Providers的依赖关系并自动编排,同时提供复制,覆盖以及重置单例等方法来丰富Containers的功能。
DI通过Containers和Providers完成了依赖注入的一部分工作,而Wiring则是提供把Containers中的Providers注入到用户函数的能力。Wiring分为三个部分,一部分是Containers的wire方法,它负责把Containers写入到指定的模块中。另一部分是inject,它是一个装饰器,用于告诉DI哪些函数需要被注入。最后一部分则是Provide,它负责把告诉DI需要的是Containers中的哪个数据或者Providers。
下面将以一个小例子来介绍如何在FastAPI中通过python-dependency-injector使用依赖注入,它的项目结构的代码如下:
1 | |
2.1.services
首先是负责核心逻辑实现的services.py,它的代码如下:
1 | |
代码中的InfoService依赖了Redis和client两个组件,并通过get方法暴露出自己的功能。该功能会检查url的状态,并把状态缓存到Redis中,减少重复请求带来的额外开支。
2.2.containers
容器层负责编排一些需要的组件,通过InfoService可以知道,目前需要client和redis两个组件,于是containers.py的实现如下:
1 | |
通过代码可以知道,client和redis都通过Providers创建,此外还用到了解析配置的config以及被组装好的info_service。
其中,Redis和client设置为单例的原因是连接的创建和销毁的成本都比较高且全局都要用到统一的连接池。
而info_service只是一个简单的业务实现,每次注入时都可以重新创建,且创建的成本不高,所以可以不通过单例来限制。
至于config则是DI自带的一个配置模块,它会读取配置文件并转为一个类,具体的配置文件内容如下:
1 | |
2.3.路由实现
在容器与业务逻辑实现完毕后,就可以开始实现路由了,路由的代码位于endpoints.py中,具体如下:
1 | |
这段代码与FastAPI规定的路由代码相比多了一个inject装饰器,它可以通过函数签名的Provide获取到该函数的依赖注入规则并根据依赖注入规则注入对应的数据。
不过如果直接使用Provide,那么FastAPI会直接解析失败,所以需要使用Depends把Provide[xxx]包裹起来,这样FastAPI就能够正常的解析路由函数并生成自己的依赖注入规则,此时FastAPI依赖注入规则如下:
| 变量 | 描述 |
|---|---|
| url | 通过Json Body中获取key为url的数据 |
| cache_timeout | FastAPI认为是一个普通的Depend实现,将通过调用获取到对应的数据 |
| info_service | FastAPI认为是一个普通的Depend实现,将通过调用获取到对应的数据 |
而DI的依赖注入规则如下:
| 变量 | 描述 |
|---|---|
| cache_timeout | Container中的config的default |
| info_service | Container中的info_service |
当请求命中路由后,会先由DI把依赖的数据进行编排注入到对应的Depends后再由FastAPI把数据注入到路由中使用。
2.4.app
最后是组装路由和事件的实现,它的代码位于app.py中,如下:
1 | |
这段代码主要作用是声明容器,注册路由和注册事件,最后再通过container.wire方法为当前模块和endpoints模块中的所有使用inject的函数生成注入规则。
如果在
container.wire之后使用inject装饰函数,那么该函数也无法被注入。
代码中拥有两个功能一样的startup事件函数,其中start_up_1函数通过app.container.redis来获取到container的Redis实例。而start_up_2则是先通过Provide和inject的组合获取到container,再通过container获取Redis实例,如果运行程序,会发现程序输出如下结果:
1 | |
通过输出结果可以发现,两个startup事件函数都能获取到Redis实例,且Redis实例是同一个。
此外,由于Provide包裹后会导致包裹的数据的类型信息丢失了。这时可以通过自定义Provide来解决的,首先是创建一个属于自己的Provide:
1 | |
接着在事件函数中直接使用MyProvide即可:
1 | |
但是如果用MyProvide(Container.redis)则会识别不出来…
2.5.总结
至此,整个例子已经实现完毕,通过这种方式可以把所有组件与FastAPI灵活的结合起来,且整个项目的依赖也将被理顺。当项目被理顺之后就可以避免很多Bug的发生,比如通过DI进行依赖注入可以间接的避免不同组件运行在不同事件循环的Bug。
此外,DI还有很多附加的功能,比如通过container的overriding可以在测试环境传入测试专用的组件;通过Resource provider去共享依赖资源或者通过Object provider去共享对象等等..
- 本文作者:So1n
- 本文链接:http://so1n.me/2023/12/07/how-to-use-dependency-injection-in-fastapi/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

