
Redis Scan命令踩坑笔记
前记
大部分人在接触Redis时就都会了解到Redis是以单线程的形式处理用户命令,导致O(N)的命令有极大的几率会阻塞Redis,所以在使用Redis时需要放弃一些O(n)命令的使用,比如不要去使用KEYS命令而应该使用SCAN命令,然而SCAN命令也有一些坑。
1.踩到的坑
为了减少MySQL的压力,在部分变动比较少的表会通过Redis套上缓存,如下代码:
1 | |
这段代码中会有一个cache装饰器,它每次被调用时会把key_name与传入的参数绑定为一个Key,比如某次调用的参数user_id为10086时,生成的Key为demo_system:user:10086。
它在执行时会先去Redis检查一下该Key是否存在,如果存在就直接返回数据,如果不存在就进入get_user函数通过MySQL获取user_id为10086的数据,不过在返回数据10086的数据之前会先缓存到对应的Key中。
可见这个实现非常简单,也没有什么坑,但是当遇到需要按照模糊匹配批量删除缓存的需求时,问题也就跟着过来了,因为Redis本身并没有按照模糊匹配再批量删除的方法,只能先通过Redis的KEYS或者SCAN的模糊匹配查找一批Key,然后再通过DEL命令批量删除。
为了防止Redis阻塞,大都会选用SCAN来进行模糊匹配并通过DEL命令删除,使用起来也简单,代码如下:
1 | |
通过这段代码就可以批量删除与demo_system:user相关的Key了,在测试环境验证基本也不会出现问题,但是当上到生产环境时就会发现拥有批量删除逻辑的接口在某些情况下它的响应时长会变得很长,比如我在排查某个业务时看到的Jaeger数据如下图: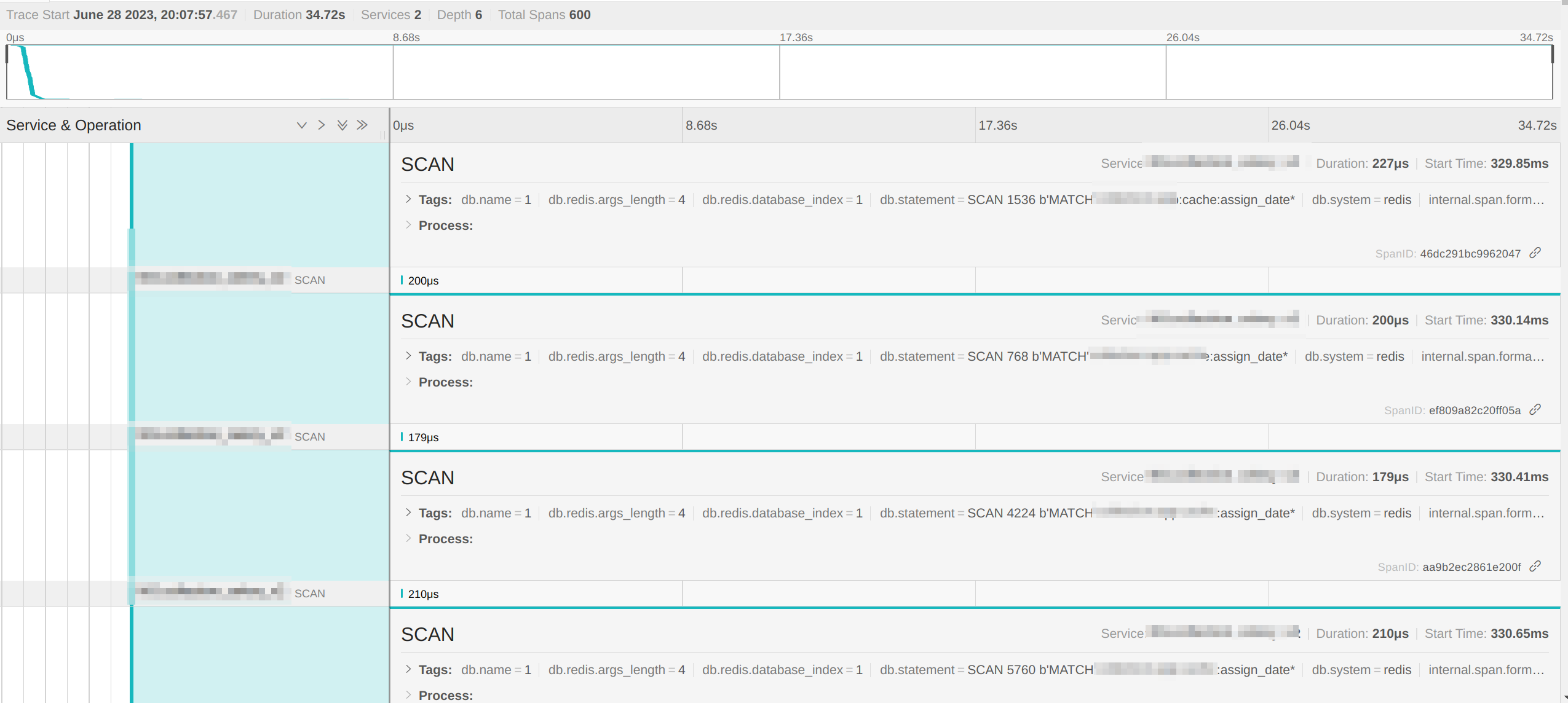 1688110959832截图_选择区域_20230629142027.png
1688110959832截图_选择区域_20230629142027.png
图中展示的是本次调用执行了多次SCAN命令,同时通过捕获的命令也可以知道SCAN的索引是一直在变的,而且不会重复,这意味着SCAN的执行逻辑是正常的,但是需要执行很多次才能获得最终的结果,所以导致接口的响应时长非常的长。
2.解决方案
当前的问题是当Redis的Key数量过多时,SCAN的扫描次数也变多了,导致服务需要向Redis发起多次IO交互,而每一次IO交互都需要一定的时间开销,最终导致接口响应时长变长, 所以解决这个问题的核心就变为在每次执行批量删除时尽量的减少SCAN命令次数(最终结果集不变的情况下)。
由于扫描次数是由SCAN命令中的COUNT大小和要扫描的Key总量这两个条件决定的,所以分别衍生出两套解决方案。
2.1.修改COUNT参数
如果代码中有大量依赖于SCAN命令且比较难更改的情况或者是代码中是使用了类似于django.core.cache的cache.delete_pattern封装函数,那么直接修改代码会非常麻烦,这时可以选择通过改大COUNT参数来减少SCAN命令的次数。
不过COUNT参数也不能太大,根据KeyDB中的描述在一个包含500万Key的Redis执行SCAN时,不同的COUNT参数与通过SCAN扫描所有Key的消耗时间的关系如下图:
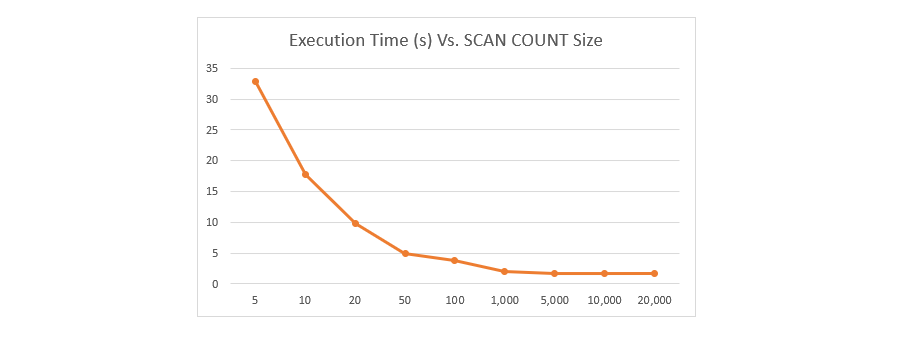
通过图可以看到,当COUNT大于1000时,通过SCAN扫码所有Key的消耗时间变化已经不是很大,但是我们也需要考虑COUNT过大时可能会对Redis的负载性能有影响,所以我们需要针对自己使用的Redis服务进行压测后,选择最适合当前Redis服务的COUNT(一般建议在100-1000之间)。
2.2.创建一个存放缓存Key的Bucket
由于缓存的Key的数量远远小于业务Key的数量,如果能做到只扫描缓存的Key而不是所有Key,那么SCAN命令执行的次数就会少了很多很多。
而这个解决方案就是通过创建一个单独的Bucket来存放缓存的Key,然后在模糊匹配时只扫描Bucket中的Key,最后在执行删除时除了删除业务Key外还需要同时删除Bucket中的Key。至于这个实现这个Bucket的方案有很多种,比如进程中的内存里或者一个公有文件中,但是Bucket的最佳实现还得是Redis的SET。
这个方案的实现最好是基于Redis客户端库再封装一层统一的调用,比如上面示例的cache装饰器,这个装饰器的核心逻辑如下:
1 | |
它会先判断key是否存在Redis中,如果存在就直接返回,不存在则调用函数获取结果,再把结果存入Redis后并返回。
在进行改造时,只需要先指定Bucket的Key名,然后在调用redis.set时把缓存的key存入到Bucket中,如下:
1 | |
然后删除的逻辑也需要修改,首先是把扫描Key从扫描Redis全局改为扫描Bucket,然后在删除Key时顺便把Key也从Bucket中移除,代码如下:
1 | |
这样一来就改造完成了,经过在线上跑了一段时间后,所有接口的响应时间并不会受删除Key的逻辑影响。
3.其他注意点
在翻阅Redis关于SCAN命令的文档后发现有如下这一段描述:
Scan guarantees
The SCAN command, and the other commands in the SCAN family, are able to provide to the user a set of guarantees associated to full iterations.
- A full iteration always retrieves all the elements that were present in the collection from the start to the end of a full iteration. This means that if a given element is inside the collection when an iteration is started, and is still there when an iteration terminates, then at some point SCAN returned it to the user.
- A full iteration never returns any element that was NOT present in the collection from the start to the end of a full iteration. So if an element was removed before the start of an iteration, and is never added back to the collection for all the time an iteration lasts, SCAN ensures that this element will never be returned.
H- A given element may be returned multiple times. It is up to the application to handle the case of duplicated elements, for example only using the returned elements in order to perform operations that are safe when re-applied multiple times.
通过描述可以发现SCAN命令会保证扫描出在遍历开始之前就已经存在Redis的值,但是如果有一个值是在遍历开始之后才加入的,那么SCAN无法保证一定能被扫描出来,不过对于当前的删除缓存Key场景并没有什么影响。此外SCAN多次扫描的结果可能有重复的,需要我们在程序中把扫码的结果重新整理并去重。
- 本文作者:So1n
- 本文链接:http://so1n.me/2023/06/28/how_to_safe_user_redis_scan/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

