
Pre-Worker服务模型问题的思考
前记
目前TCP服务的工作模型有三种,但是开源的服务器基本上都是使用Pre-Worker模型,比如Nginx和Gunicorn。在阅读Gunicorn源码后我对Gunicorn为啥要采用这个模型感兴趣,所以查阅了一番资料并了解常见TCP服务工作模型的优缺点。
1.TCP服务的请求处理模式
大多数的TCP服务部署都是从单进程开始的,当请求数量逐渐变多后,单进程工作模型的服务就开始扛不住了, 这时就会想通过添加更多的进程来帮忙处理请求,于是就会诞生出另外两种基于多进程的工作模型, 这三种工作模型的特点如下(其中监听可以认为是调用socket.listen,处理可以认为调用socket.accept):
1.单个进程监听和处理
socket。这是最简单的工作模型, 只有单个进程同时监听和执行同一个
socket.accpet调用来接受新连接以及处理请求。2.单个进程监听
socket,多个工作进程处理socket(Nginx和Gunicorn的工作模式)。这是最常用的工作模式,整个进程组中有且只有一个
socket,主进程负责监听socket,工作进程负责执行socket.accept调用来接受新连接和处理请求。(工作进程的负载均衡由系统决定)3.多个工作进程,每个工作进程都有单独监听和处理的
socket。每个工作进程都有一个独立的
socket,并且通过SO_REUSEPORT标记使这类socket都能监听和处理相同的ip端口的请求。(工作进程的负负载均衡是由每个请求的hash决定)
上面三种工作模式的主要不同点是监听和处理的方式不同,这是因为Linux采用socket对TCP, UDP进行了封装,并产生了一套独立的调用过程,而开发者在使用socket进行TCP的网络编程时一般有几个步骤:
1.调用
socket.bind,给该socket实例绑定一个IP和端口,这样后续内核会把收到该IP端口的网络流量转发给该socket。2.调用
socket.listen,该调用对应着TCP的listen状态,当调用这个函数后,服务端就会进入到这个状态,意味着可以开始处理客户端的请求了。调用
socket.listen函数后,内核为该socket维护两个队列,一个是已经建立连接的队列,代表客户端与服务端的连接已经三次握手完毕;另外一个是还没有完全建立连接的队列,代表客户端已经与服务端开始尝试连接,但三次握手还没完成。3.调用
socket.accept,从已经建立连接的队列获取连接来处理,如果获取不到连接,则会一直等待直到内核把建立的连接返回给该进程调用,需要注意的是这时候返回的是另外一个socket,也就是监听的是一个socket,accept后是另一个socket,然后服务端就会通过调用新返回的socket的socket.read和socket.write方法来与客户端进行交互。
其中第二第三交互步骤如图: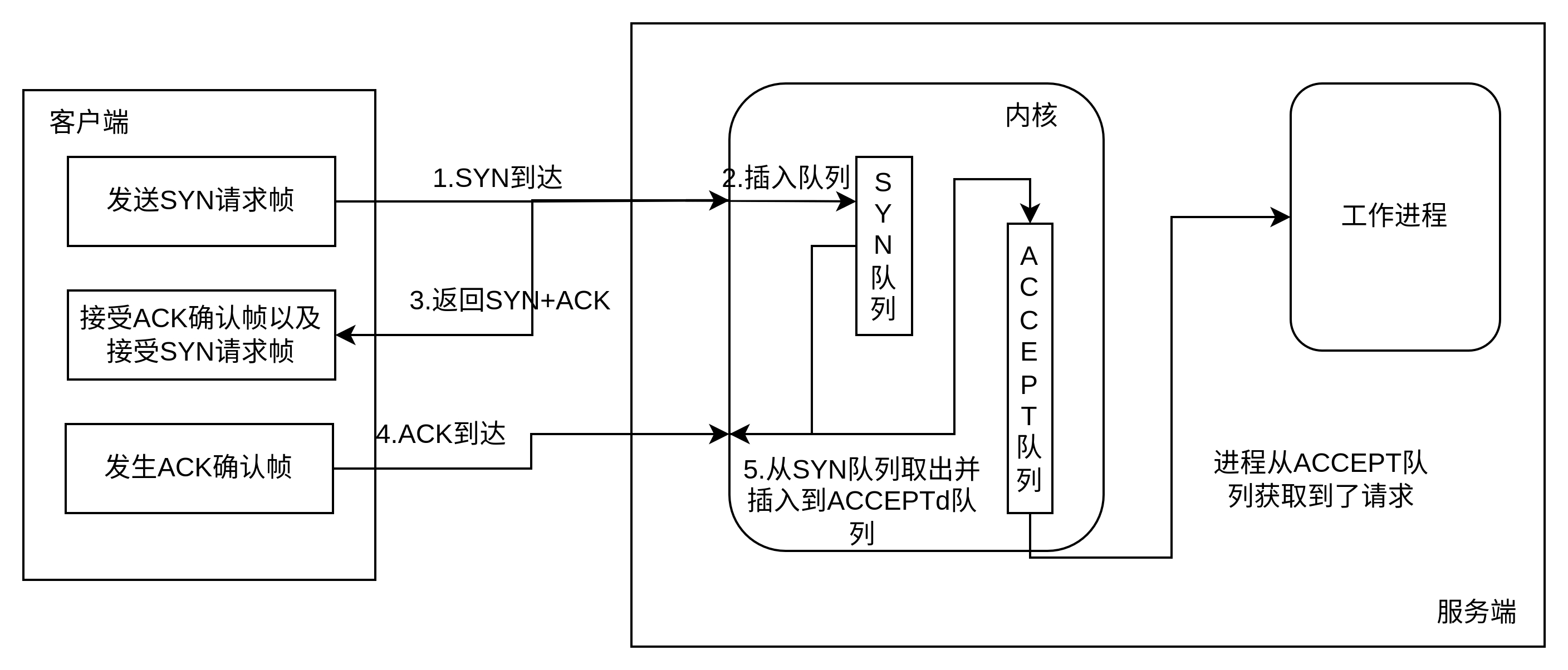 Pre-Worker服务模型问题的思考-socket交互
Pre-Worker服务模型问题的思考-socket交互
了解完了socket的交互步骤后再回顾上面的三种工作模式可以发现,第一种工作模式是一个进程包了3个调用步骤,第二种工作模式则是主进程包了前面两个调用,工作进程包了第三个调用。之所以这样区分是因为第二种工作模式一般都是采用主进程来管理工作进程,通过拓展多个工作进程来处理更多的请求数量,但是socket.accept是一个阻塞操作,而且每个请求进来的时候,服务端都会accept一次, 如果把socket.accept调用放在主进程,那么socket.accept的阻塞操作就会成为服务的处理请求瓶颈,拓展再多的工作进程也无法提升服务端的处理性能。
但是第二种工作模式也无法一味的通过提升进程来提升服务端的处理性能,因为这种工作模式会出现惊群效应。
2.惊群效应
对于Pre-Worker模型, 有一个最典型的问题就是惊群效应,惊群效应产生的原因是由于系统不知道网络数据包是何时到来,所以系统中对于网络数据包的接收都是采用异步进行的。
当服务端的socket处于listen状态之后就可以开始处理客户端的请求了,这时所有Worker进程都处于调用socket.accept后睡眠的状态中。而客户端发出的数据包会先抵达到网卡上,网卡就会通知内核数据包已经到了,内核就会开始将数据包填充到对应的socket队列并通知持有该socket的进程,由于目前没有进程来处理该请求,所以内核就会把所有持有该socket的进程全部都唤醒,但是最后只有一个进程能收到这个请求并执行后续的处理,其它的进程被唤醒后发现并没有数据可以接收则会继续睡眠。这些进程虽然被唤醒后没有执行任何操作,但是内核已经执行了对进程的调度和上下文的切换, 当并发量很大的时候,这几个步骤就会十分的影响服务性能,进而降低服务的并发能力。
可以看出,惊群效应就是多个进程抢夺一个资源而产生的问题,要解决这个问题,就需要解决资源的竞争,所以Linux内核通过引入一个名为WQ_FLAG_EXCLUSIVE的标记位来解决这个问题,当Worker进程调用socket.accept时,内核会发现这个操作带有WQ_FLAG_EXCLUSIVE的标记,就把他加入到一个accept队列的尾部, 每当有一个请求进来的时候,内核只会从这个队列的头部取出一个进程来处理请求,进程处理完成后内核再把它加入到队列的尾部,等待下次的请求到达。通过这样的设计,Pre-Worker就能避免了一个请求唤醒一片进程的情况。
2.1.Event Loop的惊群效应
通过查阅资料发现Linux通过WQ_FLAG_EXCLUSIVE标记解决了socket.accept的惊群问题, 但是现在很多服务通过基于事件循环的方法来提供更高的并发能力。比如我线上运行的服务就是用到了Gevent,而Gevent用到的核心事件循环则是Epoll,它与Select, Poll并称为Event Loop。
对于任何工作模式来说, 使用Event Loop后,进程调用socket.accept后的行为逻辑就不一样了,具体的逻辑步骤如下:
- 1.进程在调用
socket.accept时,Event Loop会把进程挂在socket对应的文件描述符的等待队列上。 - 2.当
socket的文件描述符有事件产生时,对应的驱动就会将等待队列上对应的进程进行唤醒。 - 3.被唤醒的进程会通过
Event Loop检查事件是否就绪,如果事件就绪就会返回对应的事件给刚才的进程。 - 4.检查
accept事件是否可调用, 如果可以就执行accept操作,并取得该四元组的对应socket。
可以看到,之前进程是挂在网络驱动上等着被内核唤醒,而在使用Event Loop后进程是挂在对应文件描述符的等待队列上等待被Event Loop唤醒,对于Pre-Worker模型下的每个工作进程虽然都有自己专属的Event Loop,但是他们都是等待着同样的资源,于是当该文件描述符有事件产生时,就会唤醒所有工作进程对应的Event Loop来检查事件以及判断是否可以返回事件给工作进程, 而且由于是通过Event Loop的逻辑来执行socket.accept,这样会绕过上面所说的WQ_FLAG_EXCLUSIVE标记的限制,从而又产生了惊群效应。
可以看到,Event Loop产生惊群效应的原因跟进程直接调用sock.accept十分的像,所以他们的解决思路也很像,首先是给Event Loop增加一个名为EPOLLEXCLUSIVE的标记, 然后开发者在编程时可以在Event Loop实例化后注册对应的标记,当进程在调用sock.accept且系统检到Event Loop带有该标记时,就会把进程挂在文件描述符的队列尾部,等到事件产生时,内核会只唤醒该队列的第一个进程来处理对应的事件。
关于标记
EPOLLEXCLUSIVE的具体内容可见:Add epoll round robin wakeup mode, 通过内容还可以知道还有一个标记EPOLLROUNDROBIN用来解决唤醒不均衡的情况,但是在Python中似乎没办法使用。
3.负载不均衡问题
3.1.一次线上日志的分析
目前线上其中一个服务的运行架构简化为下图: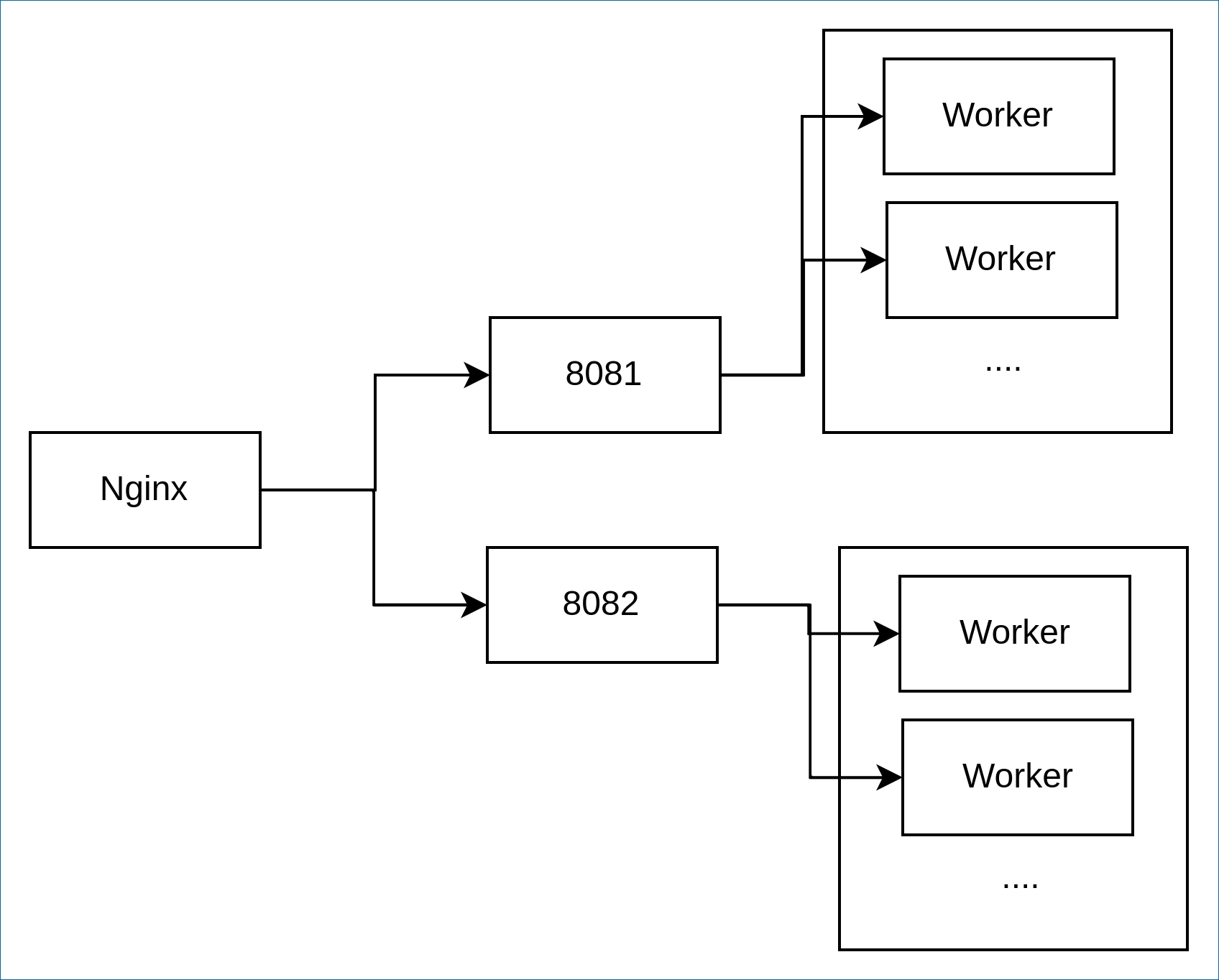 线上服务运行架构
线上服务运行架构
这个服务前置了一台Nginx,并由Nginx均衡地转发给后面的两个Gunicorn绑定的端口,这两个Gunicorn的Worker都采用Gevent Worker,同时Worker设置的数量是10个。
另外服务的应用程序每收到一条请求都会打印一条请求日志,该日志带有Worker的Pid,于是通过请求日志中Pid出现的次数就可以知道该Worker接受的请求数量有多少,在进行分析后得到的数据如下:
1 | |
通过数据可以发现,每个Worker处理的请求数量都是不一致的,且每2个Worker处理的数量是接近的,在经过上面的服务运行架构可以发现有个数据特点:
- 1.不同的实例下的
Worker处理请求数量分布十分的接近。如PID 2042属于Gunicorn实例1的Worker, PID 2034属于Gunicorn实例2的Worker,他们处理的请求数量分别为311245和311909,相差不大,且远远超过了同实例下的其它Worker处理的请求数量。 - 2.不同的
Worker处理的请求数量差别很大,处理请求数量最多的Worker比其它Worker处理请求的数量还多(同一实例情况下)
通过第一点可以发现Nginx的负载均衡是生效的,因为每个实例接收到请求是相近的,且每个实例的Worker接收请求数量的分布十分的接近。。通过第二点可以发现不同Worker的请求数量差别非常的大,它们之间相差的最大倍数达到了100倍,这极有可能是Gunicorn导致分发给Worker的请求不均衡。
这样的数据标明了服务存在部分进程饿死的现象,即使加再多的Worker也很难去分担之前Worker的请求,反而会因为进程过多导致服务器上下文切换次数变多而性能下降。
由于之前一直在使用Asyncio,所以我知道Event Loop在收到对应文件描述符的事件时,它不是以雨露均沾的方式去唤醒进程/线程/协程,而是会优先唤醒第一个注册的进程/线程/协程,只有第一个进程/线程/协程繁忙的情况下才会去唤醒后面的进程/线程/协程,造成了唤醒倾斜的问题,所以我猜测是这个规则引发了负载不均衡的问题。以下是一个验证Event Loop唤醒规则的demo代码以及注释如下:
1 | |
该程序的消费者注册到Event Loop的先后顺序与他们的ID有关,该程序中有两个队列,它们对应着两种类型的消费者, 第一种消费者只做消费(序号为偶数的消费者),第二种消费者除了消费外还休眠了0.1秒(序号为奇数的消费者), 在运行程序后,程序的输出结果如下:
1 | |
通过输出结果可以发现,10个消费者协程已经创建了,
对于带有休眠的消费者(序号1,3,5,7,9)他们都消费了一条数据,但对于普通的消费者(0,2,4,6,8),只有0号消费者有消费,这是因为在普通的消费者中,0号消费者是最早注册的,且这类型的消费者从队列获取数据所花费的CPU时间非常的少,所以0号消费者消费一次数据后又立即收到了Event Loop的调度继续消费,而带有休眠的消费者因为他们的休眠占用了一些时间,Event Loop调度了最先注册的消费者后想继续调度却发现它处于繁忙状态,这时就会调度下一个注册的消费者, 最终达到均匀的调度到每一个消费者。
不过这个例子只是单进程下跑出来的结果, 为了更更贴生产服务,我把Gunicorn的Sync Worker和Gevent Worker抽象为下面两个简单的TCP模型,他们的代码如下:
1 | |
服务端代码创建完成了, 接下来可以使用客户端代码来进行测试并统计, 代码如下:
1 | |
一切准备就绪,分别对两个模式的代码进行测试,结果如下:
1 | |
通过结果可以看出Sync Worker的输出结果是三个工作进程得到请求的数量是相近的,而Gevent Worker的三个工作进程得到请求的数量是不均衡的,特别是第三个工作进程得到请求点数量比前两个还少(如果去掉模仿IO的代码,Gevent Worker模型下测试的结果只有一个工作进程得到了所有请求点数量)。
4.两种问题的共同解决方案–SO_REUSEPORT
现在回顾下这两种问题,他们的核心都是围绕着对同一个资源(文件描述符/事件)进行争夺,如果能解决这一点,那么两个问题都能得到解决。而之所以需要对同一个资源进行争夺是因为Pre-Worker模型下是由Master进程创建了用户指定IP端口的socket并在调用监听操作后才分给工作进程的,如果这些socket都能由工作进程创建,那就能解决问题了。
可是在进行网络编程时,经常能发现端口被占用导致服务无法启动的情况,这就意味着工作进程不能创建监听相同IP端口的socket,这时就需要SO_REUSEPORT了。
通过SO_REUSEPORT,操作系统允许多个工作进程的socket绑定到同一个端口,这时候服务的工作模式就变为上面所说的第三种,既多个工作进程,每个工作进程都有单独监听和处理的socket,这种工作模式下每个工作进程持有的文件描述符都是自己专有的,没人一起争夺,这样无论是Synv Worker调用socket.accept还是Gevent Worker调用的socket.accept,他们都不会出现争夺的问题而产生惊群效应,他们的交互变化如图: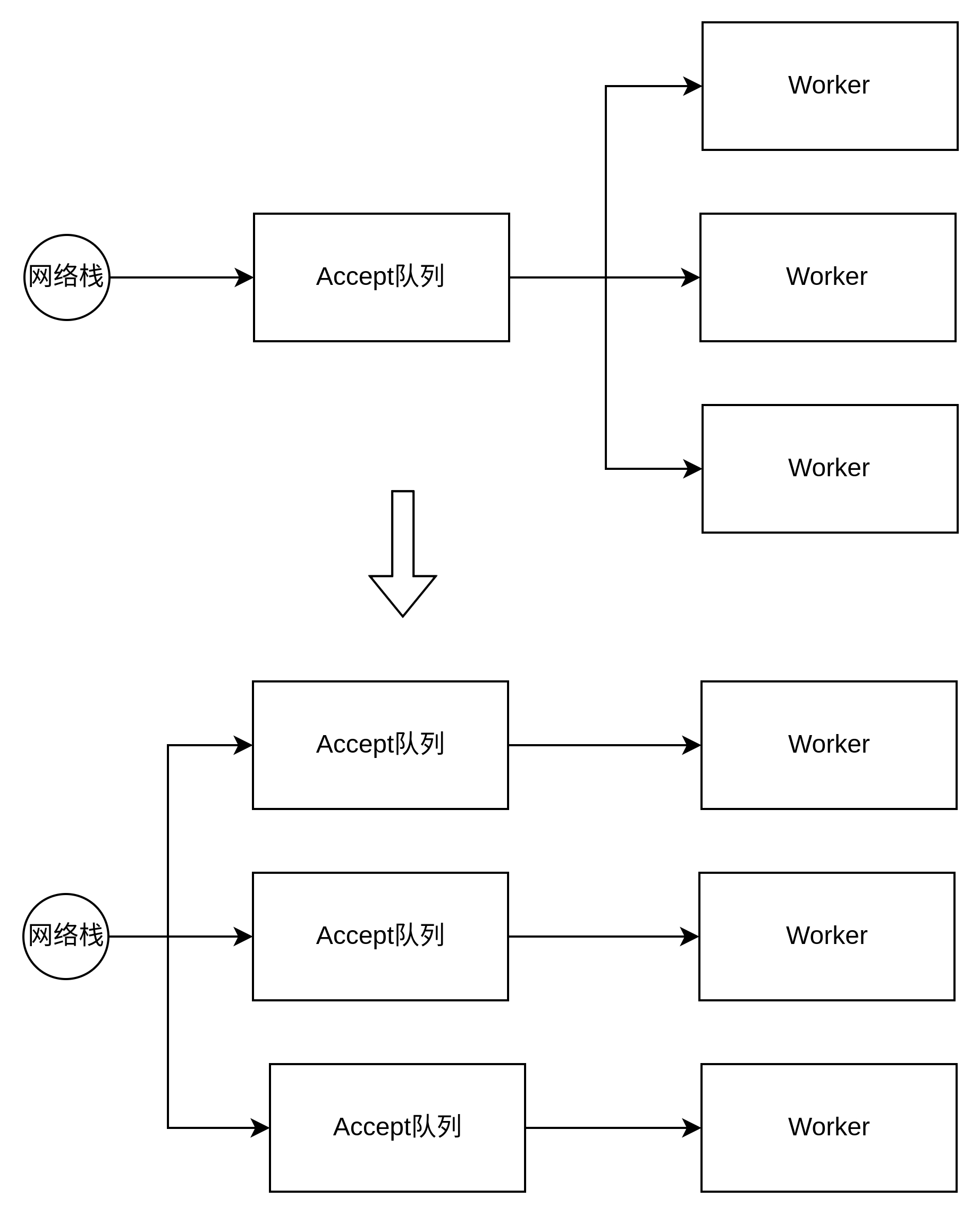 Pre-Worker服务模型问题的思考-不同工作模式交互图
Pre-Worker服务模型问题的思考-不同工作模式交互图
通过图可以看出,在使用SO_REUSEPORT后,对于同一个IP端口从单个Accept队列变为多个Accept队列,每个队列对于工作进程来说都是独有的,并且Linux会通过对四元组把请求hash到不同的Accept队列,最后使得每个Worker都能获得相同的连接数量,从而实现负载均衡。
为了验证SO_REUSEPORT是否发挥作用,现在基于上面Gevent Workrt模型的简易代码进行修改:
1 | |
修改完成后,再运行刚才的客户端测试脚本, 得到输出如下:
1 | |
通过结果可以看出虽然第一个工作进程得到的数量还是最多的,但是三个工作进程之间的差距已经是非常的小了。
Gunicorn虽然支持设置
SO_REUSEPORT但是他自带的Worker类型仍然是以第二种工作模式运行着,所以我们需要去修改它的Worker,才能以第三种工作模式运行。
不过,使用了SO_REUSEPORT后会带来两个新的问题,第一个也就是官方自己说的(如下),如果绑定到同一个端口的socket数量发生变化时,hash就会有变动,这个时候如果有个请求处于三次握手期间,那么它将会被丢弃,这种情况下客户端会重置请求,但服务端仍然会留下一个孤独的请求结构。
The SO_REUSEPORT socket option:
The other noteworthy point is that there is a defect in the current implementation of TCP SO_REUSEPORT. If the number of listening sockets bound to a port changes because new servers are started or existing servers terminate, it is possible that incoming connections can be dropped during the three-way handshake. The problem is that connection requests are tied to a specific listening socket when the initial SYN packet is received during the handshake. If the number of servers bound to the port changes, then the SO_REUSEPORT logic might not route the final ACK of the handshake to the correct listening socket. In this case, the client connection will be reset, and the server is left with an orphaned request structure. A solution to the problem is still being worked on, and may consist of implementing a connection request table that can be shared among multiple listening sockets.
第二个问题则是请求延迟,在第二种工作模式下,所有请求都会进到同一个Accept队列,等待工作进程来从队列拉取数据,这种情况下所有请求都是先到先被处理;而在第三种工作模式下,请求会被hash到不同进程的Accept队列,等待被持有该队列的进程拉取数据,如果这时候有个进程发生了阻塞情况,那么该进程上的Accept队列的所有请求都会一直等待,直到进程阻塞结束,这种情况下该队列的请求可能比别的队列的请求先到,但是却比别的队列的请求晚处理, 这就是请求延迟到现象。
5.总结
目前对于Pre-Worker问题都有了解决方案, 但是这些方案并不一定是完美的,他们可能存在着一些问题等待被解决,而我们可以根据自己的使用情况来选择不同的工作模型,在性能允许范围下规避一些已知的问题。
- 本文作者:So1n
- 本文链接:http://so1n.me/2022/03/07/Pre-Worker%E6%9C%8D%E5%8A%A1%E6%A8%A1%E5%9E%8B%E9%97%AE%E9%A2%98%E7%9A%84%E6%80%9D%E8%80%83/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

