前记 Gunicorn是一个基于Python实现的动态Web服务器,它通过Pre-Worker模型来实现并发,本身带有多种工作模式,基本上可以与所有基于Python的Web框架集成,并为他们带来一个多功能又稳定的服务器托管核心。
从学习Python Web的第一天就开始接触了Gunicorn,那时候还不知道他具体的作用是什么, 只知道在项目中使用他运行之后可以变得十分的稳定,高性能,从未研究它是如何实现的。随着使用时间的增长,越来越想知道它的运行原理是什么,特别是它性能为何会高,跟类Unix有什么特殊结合,Pre-Worker模型是如何通信的,如何设计一个比较好的Pre-Worker模型服务器?
1.简单了解 通过Gunicorn代码仓库 把代码拉到本地,使用Tree命令可以简单的看到Gunicorn的代码结构,可以看出文件数量并不是很多,以下是Gunicorn的代码结构以及他们每个文件夹或者每个文件的说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ├── app
2.开始入手 了解完代码结构后接着从官方文档的示例开始入手:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ pip install gunicorn"Hello, World!\n" "200 OK" , ["Content-Type" , "text/plain" ),"Content-Length" , str(len(data)))return iter([data])
这个示例演示了如何通过命令行来使Gunicorn来运行一个最小的WSGIWeb应用,如果熟悉Python的打包规则的话,可以知道这个命令中的gunicorn实际上是在setup.py文件中定义好的, 重新打开仓库,找到setup.py:
1 2 3 4 5 6 7 8 9 from setuptools import setup, find_packages""" [console_scripts] gunicorn=gunicorn.app.wsgiapp:run """ ,
这里移除了其它部分的代码,只保留了相关的代码,在这段代码中,指定了gunicorn的命令是命令gunicorn.app.wsgiapp:run的别名,所以这段代码实际上执行了gunicorn.app.wsgiapp文件中的run函数:
1 2 3 def run ():from gunicorn.app.wsgiapp import WSGIApplication"%(prog)s [OPTIONS] [APP_MODULE]" ).run()
而run函数的运行逻辑也是很简单, 它是直接实例化一个承于gunicorn.app.base文件的BaseApplication的WSGIApplication类, 这个类在实例化时会执行它的do_load_config方法,也就是在这时候会初始化实例的cfg变量,并调用cfg.parse,其中这个实例是config.Config的实例化,而parse方法是用来解析用户传入的参数并供后续的Arbiter以及Worker使用。
3.加载配置 一般项目中的加载配置是没有什么可以说的, 但是Gunicorn比较特殊, 在config文件中除了Config这个类和一些校验方法外,还存在大量类似于:
1 2 3 4 5 6 7 8 9 10 11 12 13 class WorkerConnections (Setting ):"worker_connections" "Worker Processes" "--worker-connections" ]"INT" type = int 1000 """\ The maximum number of simultaneous clients. This setting only affects the Eventlet and Gevent worker types. """
的类, 这些类就是Gunicorn支持的参数或配置值以及它对应的类型,校验规则,默认值和帮助文档等,这些类都按照一定的规范进行编写,同时又继承于Setting这个类,而Setting这个类又继承了SettingMeta,而SettingMeta的作用就是在程序运行的时候,把所有继承于Setting的类加入到config文件的local变量中,供Gunicorn来使用。
Gunicorn在启动时通过config模块把用户传入的命令进行初始化, 再通过环境变量来初始化配置,此时的配置会覆盖掉用户传入命令初始化时的配置,接着在判断用户是否有指定配置文件,如果有就加载配置文件的配置,再覆盖已经存在的配置。
4.Gunicorn的核心–Arbiter.run Application实例化完成后,会调用BaseApplication.run方法, 该方法如下:
1 2 3 4 5 6 7 def run (self ):try :except RuntimeError as e:"\nError: %s\n" % e, file=sys.stderr)1 )
该方法会执行gunicorn.arbiter文件的Arbiter类,这个类是gunicorn的核心类,负责启动和管理所有运行的worker,而Arbiter的run方法则是核心中的核心,负责着整个服务的运行管理,同时又跟Arbiter的其它方法有交互,所以可以通过分析run方法进行分析,进而纵观整个Arbiter类, run的方法如下(具体说明见注释,其它具体分析见小章节):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 def run (self ):"Main master loop." "master [%s]" % self.proc_name)try :while True :0 ) if self.SIG_QUEUE else None if sig is None :continue if sig not in self.SIG_NAMES:"Ignoring unknown signal: %s" , sig)continue getattr (self, "handle_%s" % signame, None )if not handler:"Unhandled signal: %s" , signame)continue "Handling signal: %s" , signame)except (StopIteration, KeyboardInterrupt):except HaltServer as inst:except SystemExit:raise except Exception:"Unhandled exception in main loop" ,True )False )if self.pidfile is not None :1 )
4.1初始化–Arbiter.start Arbiter.start方法的第一步是进行初始化,首先是判断该进程是否是另一个进程启动的,这里是Gunicorn的Upgrading to a new binary on the fly 功能,将在后面统一说明,然后他通过init_signals方法初始化信号的回调, init_signals的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def init_signals (self ):"""\ Initialize master signal handling. Most of the signals are queued. Child signals only wake up the master. """ for p in self.PIPE:for p in pair:for s in self.SIGNALS:def signal (self, sig, frame ):if len (self.SIG_QUEUE) < 5 :
这个方法做了两件事:
1.首先是初始化PIPE, Gunicorn的Master是一个一直在循环的单进程,每次循环会sleep一秒防止空转,通过PIPE可以使Master进程从sleep阶段提前唤醒。PIPE在初始化时会先通过util.set_non_blocking方法来设置不阻塞来防止PIPE收到信号时,阻塞到Master进程的主流程。
然后通过util.close_on_exec来关闭子进程无用的描述符,之所以要这样处理是因为Gunicorn采用了Pre-Worker的模型,在运行的时候Master进程会通过fork的方法来创建worker进程,fork出来的子进程是通过写时复制来获得父进程的数据的,当子进程在exec阶段时就会创建一份新的资源引用,此时保存原来文件描述符的变量当然也不存在了,也就无法关闭无用的文件描述符了, 这意味着对于某个文件描述符多了一个引用,而Linux的文件描述符是等到都没有引用的时候才会删掉, 所以我们在使用的时候都会期望在fork阶段后,exec阶段之前直接关掉无用的物件描述符,这时候就可以用到Linux的close-on-exec功能。
在初始化文件描述符后, 通过直接对文件描述符设置FD_CLOEXEC标记, 这样在fork阶段后exec阶段前,Linux会自动关掉无用的文件描述符, 在Gunicorn中,会对所有文件描述符都调用util.close_on_exec。
2.初始化真正的信号监听, 注册了Gunicortn所有会用到的信号回调,该回调会把信息注册到一个名为SIG_QUEUE的队列中,同时会执行wakeup来唤醒worker的循环(将在run中的sleep介绍这个机制是怎么实现的)
在完成了信号监听的注册后, 会开始创建sock,Gunicorn为各种类型的sock做了统一的封装, 它会判断用户配置要监听的IP端口来挑选一个合适的sock,然后进行初始化,其中最重要的初始化方法就是BaseCocket的set_options方法, 它的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class BaseSocket (object def __init__ (self, address, conf, log, fd=None ):def set_options (self, sock, bound=False ):1 )if (self.conf.reuse_portand hasattr (socket, 'SO_REUSEPORT' )): try :1 )except socket.error as err:if err.errno not in (errno.ENOPROTOOPT, errno.EINVAL):raise if not bound:0 )if hasattr (sock, "set_inheritable" ):True )return sockdef bind (self, sock ):
在Gunicorn中,它创建的所有Scoket都是继承于gunicorn.sock.BaseSocket,所以Gunicorn在创建scoket后会调用set_options方法,这个方法默认会设置SO_REUSEADDR标记,然后再依赖配置设置SO_REUSEPORT标记, 设置SO_REUSEPORT标记可以解决部分惊群问题,同时也能解决不同进程收到请求的负载均衡问题,但是会带来响应请求的延迟,所以Gunicorn将这个配置设置为可选项(关于这几个参数以及惊群问题会另开文章说明)。 接着Gunicorn会调用sock.bind且设置scoket是不阻塞的,再进行监听,并返回给Master。
Gunicorn之所以这样做是因为Gunicorn是Pre-Worker模型的,在这个模型中, 所有的scoket都是由Master进程创建并监听,然后在通过fork子进程的时候把scoket传递给子进程,然后子进程可以通过该scoket可以进行accept获取到对应的请求。
4.2.管理woeker数量–manage_workers 在Gunicorn的Arbiter中,通过manage_workers方法对Worker进行管理, 当前运行的Worker数量不满足与用户指定的数量时,会通过spawn_workers来调用spawn_worker创建Worker,spawn_workers是批量创建一批Worker,而spawn_worker是每次调用创建一个Worker,他们的代码十分简单, 具体说明见注释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 def spawn_worker (self ):1 2.0 ,if pid != 0 :return pidfor sibling in self.WORKERS.values():try :"worker [%s]" % self.proc_name)"Booting worker with pid: %s" , worker.pid)0 )except SystemExit:raise except AppImportError as e:"Exception while loading the application" ,True )"%s" % e, file=sys.stderr)except Exception:"Exception in worker process" )if not worker.booted:1 )finally :"Worker exiting (pid: %s)" , worker.pid)try :except Exception:"Exception during worker exit:\n%s" ,def spawn_workers (self ):for _ in range (self.num_workers - len (self.WORKERS)):0.1 * random.random())
在这里面中有两个注意点,第一个点是在spawn_worker中,会先初始化worker,接着在fork出子进程运行代码部分会先执行worker.init_process最后调用sys.exit(0)退出,所以我们最好不要在worker.__init__里面初始化数据,因为这部分是在Master进程中执行的。我们应该在worker.init_process中执行初始化,并在初始化代码执行后调用super().init_process(),如下:
1 2 3 def init_process (self ):super ().init_process()
这样做是因为BaseWorker会在自己的init_process方法中执行一些通用的初始化功能,然后再调用BaseWorker.run来运行Worker。
4.3.核心循环与信号处理 在经过manage_workers后,Worker都已经以子进程的形式在运行了,但是Master进程还需要处理一些家务事,比如管理Worker进程是否存活以及用户在运行时指派给Master的一些工作等,而这些将通过信号来进行交互。
这个阶段的Master以一个循环不断的跑着, 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 while True :0 ) if self.SIG_QUEUE else None if sig is None :continue if sig not in self.SIG_NAMES:"Ignoring unknown signal: %s" , sig)continue getattr (self, "handle_%s" % signame, None )if not handler:"Unhandled signal: %s" , signame)continue "Handling signal: %s" , signame)
它的运行逻辑很简单,首先是判断当前进程是不是真的主进程,如果是将晋升为主进程,然后就是获取信号,如果当前信号队列有信号存在就取最前的一个并执行对应的信号对用以及调用wakeup方法,防止下次循环还在睡眠;如果获取不到信号,就先休眠1秒,然后清除超时的Worker最后执行manage_worker并进入下个循环。
在Gunicorn中,它确保每个循环只执行一次操作,确保该循环要不就执行信号回调,要不就执行Worker管理,同时它还确保执行信号回调的优先级是最高的,但是Gunicorn对传入的信号的数量也有限制,通过4.1.初始化--Arbiter.start的源码:
1 2 3 4 def signal (self, sig, frame ):if len (self.SIG_QUEUE) < 5 :
中可以知道,Gunicorn只允许最多有5个信号在队列中,防止同一时刻执行太多了信号处理,同时可以看到在正常接收信号后会执行wakeup函数:
1 2 3 4 5 6 def wakeup (self ):try :1 ], b'.' )except IOError as e:if e.errno not in [errno.EAGAIN, errno.EINTR]:raise
这个函数十分简单,就是往管道PIPE写入了一个字节,这样就能快速唤醒Gunicorn继续运行循环,不会停留在sleep阶段。wakeup函数是无法理解它为啥能唤醒Gunicorn的主循环的, 需要结合Arbiter.sleep源码来了解Gunicorn为何这样设计。
通常情况下,我们都会使用Python的标准函数time.sleep来实现进程睡眠,但是该函数是阻塞的,意味着该函数运行期间是没办法通过其它方法来进行打断,所以Gunicorn采用了事件循环的思路实现Arbiter.sleep,该通过使用select.select来读取PIPE,同时设置超时为1秒,sleep源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def sleep (self ):try :0 ]], [], [], 1.0 )if not ready[0 ]:return while os.read(self.PIPE[0 ], 1 ):pass except (select.error, OSError) as e:getattr (e, 'errno' , e.args[0 ])if error_number not in [errno.EAGAIN, errno.EINTR]:raise except KeyboardInterrupt:
在这段逻辑中,会把PIPE的读文件描述符传给select.select中,这样select.select会等待PIPE的事件再返回,同时它的最大等待时间为1秒,之后这段运行逻辑会停留在这里,但并不会阻塞当前进程,如果这时候进程有收到信号,进程还是可以正常接收信号, 并通过wakeup函数往PIPE写入一个字节,接着select.select就能通过PIPE捕获到事件并返回,这时候上面停留的代码逻辑就会继续执行,等于sleep函数可以提前结束等待,Gunicorn的主循环能继续转了。
这一段主要是依赖于事件循环相关来防止主进程被阻塞,可以通过搜索事件循环,epoll来了解更多相关的。初识Python协程的实现 了解
5.无感切换实例 在分析Arbiter,有几处都是先忽略跳过不分析,这部分的功能我把他称为无感切换新实例,这里的无感是指与Gunicorn绑定的scoket交互的应用程序,如Nginx或者客户端等。Gunicorn的实例在运行的时候,重新开一个新的Gunicorn实例来运行我们指定的代码,这时候读取的代码和配置都是最新的,与我们当前正在运行的旧实例不一样,但是他们都能针对同一批socket处理请求(可用于滚动发布以及灰度发布)。
为了方便阐述,我把一个Master进程与它fork出来的Worker进程统称为一个实例。
实际上官方把这个功能称为:Upgrading to a new binary on the fly ,这个功能是大多数Pre-Worker模型的服务器都会支持的,不过这个功能需要多块不同生命周期的代码来结合才可以完成,所以单独拎出来分析。
根据文档:
First, replace the old binary with a new one, then send a USR2 signal to the current master process. It executes a new binary whose PID file is postfixed with .2 (e.g. /var/run/gunicorn.pid.2), which in turn starts a new master process and new worker processes
可以知道,Master进程在收到USR2的信号后,会创建一个新的实例,这部分的源代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 def handle_usr2 (self ):def reexec (self ):if self.reexec_pid != 0 :"USR2 signal ignored. Child exists." )return if self.master_pid != 0 :"USR2 signal ignored. Parent exists." )return if self.reexec_pid != 0 :return 'GUNICORN_PID' ] = str (master_pid)if self.systemd:'LISTEN_PID' ] = str (os.getpid())'LISTEN_FDS' ] = str (len (self.LISTENERS))else :'GUNICORN_FD' ] = ',' .join(str (l.fileno()) for l in self.LISTENERS)'cwd' ])0 ], self.START_CTX['args' ], environ)
按官方文档的示例,当Gunicorn执行完这段逻辑后,就有一个新的Gunicorn实例开始运行了,由于这个实例的环境变量中存在一个GUNICORN_PID的变量, 所以在运行时会有一些不一样, 比如在Arbiter.start进行初始化时会设置不一样的属性:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def start (self ):if 'GUNICORN_PID' in os.environ:int (os.environ.get('GUNICORN_PID' ))".2" "Master.2" if self.cfg.pidfile is not None :if self.master_pid != 0 :".2"
同时,在初始化scoket时,还会沿用环境变量中名为GUNICORN_FD的值,这个值是创建这个实例的Master进程用到的文件描述符,新创建的实例通过复用相同的文件描述符,使其它也能读取到相同端口的网络请求数据:
1 2 3 4 5 6 7 8 9 10 def start (self ):elif self.master_pid:for fd in os.environ.pop('GUNICORN_FD' ).split(',' ):int (fd))
在新创建的实例运行后, 机器上的Gunicorn进程列表将变为这样子:
1 2 3 4 5 6 7 8 9 10 20844 benoitc 20 0 54808 11m 3352 S 0.0 0.1 0 :00.36 gunicorn: master [test:app]20849 benoitc 20 0 54808 9.9 m 1500 S 0.0 0.1 0 :00.02 gunicorn: worker [test:app]20850 benoitc 20 0 54808 9.9 m 1500 S 0.0 0.1 0 :00.01 gunicorn: worker [test:app]20851 benoitc 20 0 54808 9.9 m 1500 S 0.0 0.1 0 :00.01 gunicorn: worker [test:app]20854 benoitc 20 0 55748 12m 3348 S 0.0 0.2 0 :00.35 gunicorn: master [test:app]20859 benoitc 20 0 55748 11m 1500 S 0.0 0.1 0 :00.01 gunicorn: worker [test:app]20860 benoitc 20 0 55748 11m 1500 S 0.0 0.1 0 :00.00 gunicorn: worker [test:app]20861 benoitc 20 0 55748 11m 1500 S 0.0 0.1 0 :00.01 gunicorn: worker [test:app]
从这个进程列表可以发现目前有两个Master进程,他们分别有3个Worker子进程,这时候两个实例是一起运行的,如果指定的代码文件没有进行修改,指定的配置也没变,那么这两个实例的逻辑可以认为是等效的。
当用户判断新的实例能正常处理请求后, 可以发送信号TERM给旧实例的Master,让它开始优雅的关闭Worker并退出,然后新创建的实例的Master进程会在核心循环中发现创建自己的父进程已经退出了, 就让自己晋升为真正名义上的Master进程,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def maybe_promote_master (self ):if self.master_pid == 0 :return if self.master_pid != os.getppid():"Master has been promoted." )"Master" 0 del os.environ['GUNICORN_PID' ]if self.pidfile is not None :"master [%s]" % self.proc_name)
通过源码可以发现,无论新实例有没有通过may_be_promote_master晋升为名义上的Master进程, 总体上的逻辑跟原先的Master进程是一样的,只不过是没办法通过接受USR2信号来创建新的实例。
通过这种方式可以无感的升级应用代码,结合其它的信号,在升级失败时也能关闭新创建的实例,切回到旧实例,具体可以通过Upgrading to a new binary on the fly 了解。
6.Worker与Master的交互 分析完了Arbiter后,整个Gunicorn的核心还剩下Worker尚未分析,Gunicorn中带了多种Worker,比如用在gevent场景的Worker.ggevent.GeventWorker,用在Tornado的Worker.gtornado.TornadoWorker。这些Worker除了一些与Arbiter交互的方法外, 还有一些方法用来通过读取scoket的数据并转化为WSGI协议发给挂在后面的WSGI应用,这意味着Gunicorn不仅用于WSGI场景,还可以通过自己编写Worker来对接其它的场景,比如Uvicorn.Worker就是对接ASGI应用等。
由于我在分析Gunicorn时,我是抱着使用Gunicorn来托管我的TCP服务的,所以我是着重了解Worker与Arbiter的交互,对于自带的其它Worker,则不多做说明(通过了解WSGI协议也能了解它们的执行逻辑)。
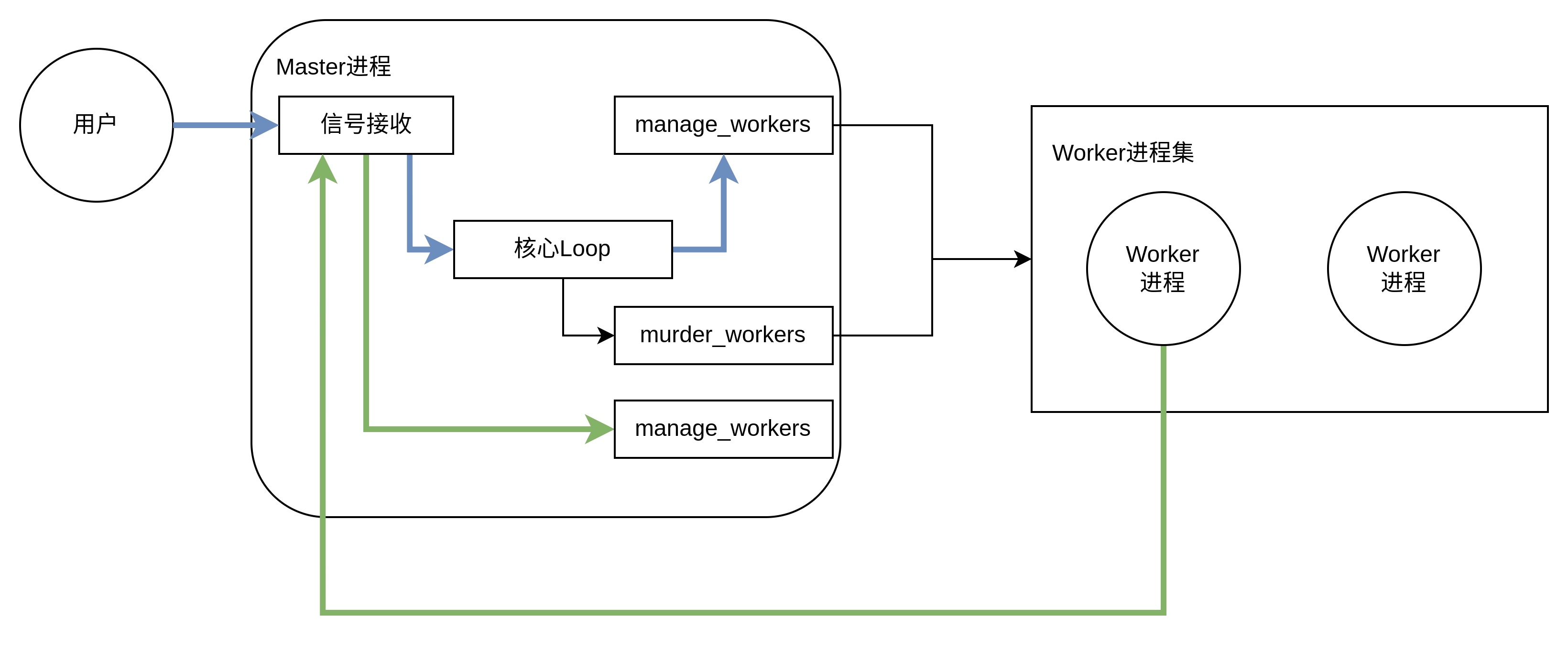
Worker与Arbiter的交互可以简化为如下图:
Gunicorn源码分析-Worker与Arbiter交互
图中蓝色和绿色线条代表两种类型的信号交互,黑色代表其它的Master进程与Worker进程的交互。
6.1.基于信号的交互 在图中见到了已经在4.2.管理worker数量--manager-workers说过的manage_workers,它除了在Arbiter中会调用manage_workers进行Worker初始化,之后会在接收到用户发起信号的时候调用manage_worker来进行增减。这类型信号更改Worker数量有两种, 一种是修改配置的Worker数量, 然后通过信号HUP重载配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def handle_hup (self ):"Hang up: %s" , self.master_name)def reload (self ):for _ in range (self.cfg.workers):
另外一种就是通过信号TTIN和TTOU来更改数量的加减:
1 2 3 4 5 6 7 8 9 def handle_ttin (self ):1 def handle_ttou (self ):if self.num_workers <= 1 :return 1
此外,Master除了接收用户的信号外,还接收自己创建的Worker进程的信号,当Worker进程退出时,会发送信号CHLD给Master进程,Master进程会调用reap_worker来回收对应Worker的进程资源, reap_worker源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def reap_workers (self ):try :while True :1 , os.WNOHANG)if not wpid:break if self.reexec_pid == wpid:0 else :8 if exitcode == self.WORKER_BOOT_ERROR:"Worker failed to boot." raise HaltServer(reason, self.WORKER_BOOT_ERROR)if exitcode == self.APP_LOAD_ERROR:"App failed to load." raise HaltServer(reason, self.APP_LOAD_ERROR)if os.WIFSIGNALED(status):"Worker with pid %s was terminated due to signal %s" ,None )if not worker:continue except OSError as e:if e.errno != errno.ECHILD:raise
这段代码实际上是为了解决一个类Unix系统等待终止子进程的问题, 该问题是如果子进程在终止过程中,子进程完全消失了,就没有给父进程留下任何可以来了解子进程的东西,父进程没办法清理与子进程相关的数据,所以类Unix系统有这样一个设计:如果子进程在父进程之前结束会先发送信号给父进程,然后内核会把子进程设置为一个特殊的状态,处于这个状态的进程叫做僵尸进程,这类进程只保留最小的概要信息并等待分进程来查询自己的信息,只要父进程获取了子进程的信息后,子进程就会消失,否则会一直保持僵死状态(zombie)。其中父进程获取子进程的信息有多种方式,在Gunicorn是采用waitpid来获取子进程的信息,而reap_workers的主要责任就是通过waitpid获取子进程信息并做出响应。
在Gunicorn中,采用waitpid来获取僵死进程的状态和信息,但是直接使用waitpid会暂时停止目前进程的执行,直到有信号来到或者有子进程结束,所以使用了WHOHANG标记,该标记表示如果没有任何已经结束的子进程也马上返回结果,不等待。Gunicorn通过使用该标记以及循环的方式来解决可能同时出现多个进程变为僵死状态的问题。
此外Gunicorn在waitpid中传了一个参数值-1,这个参数的名为pid,输入不同的值有不同的意义:
pid>0时,只等待进程ID等于pid的子进程,不管其它已经有多少子进程运行结束退出了,只要指定的子进程还没有结束,waitpid就会一直等下去。
pid=-1时,等待任何一个子进程退出,没有任何限制,此时waitpid和wait的作用一模一样。
pid=0时,等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid不会处理它。
pid<-1时,等待一个指定进程组中的任何子进程,这个进程组的ID等于pid的绝对值。
Gunicorn在通过waitpid获取到的返回信息中第一个pid代表退出进程的pid, 如果为空就代表没有子进程退出,应该直接退出逻辑返回到循环中,第二个status它包含了一些子进程的附加信息,该参数的高8位记录进程调用exit退出的状态,低8位记录进程接收到的信号,如果是正常退出,高8位数为退出状态,低8位数为0,如果是非正常退出,高8位数为0,低8位数为信号id,所以Gunicorn会通过status >> 8来获取低8位的数据,且当它不为0时就判断是否是自己定义的特殊信号,如果是则按照信号进行抛异常。
6.2.Master进程主动检测 上面说到Master进程虽然可以收到子进程退出时发出的CHLD信号,但是并不是所有子进程退出时都能发出CHLD信号,所以Master进程还需要做到主动检测,Gunicorn在主动检查中用到了一个比较奇特的方法–临时文件的最后修改时间,该方法是通过Worker进程每隔一段时间更新临时文件的最后修改时间,Master进程每隔一段时间就去检测最后修改时间是否在一段范围内, 如果不合法就剔除这个Worker进程。
这种方式挺让人困惑的,同时容易引起性能问题,具体见How do I avoid Gunicorn excessively blocking in os.fchmod? ,目前官方表示可能会进行改进, 见Gunicorn中的一条issue
这个检测是思路通过WorkerTmp类来实现,它的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class WorkerTmp (object def __init__ (self, cfg ):0 def notify (self ):1 ) % 2 def last_update (self ):return os.fstat(self._tmp.fileno()).st_ctime
它会在Worker初始化时实例化为Worker.tmp属性,对于Worker进程,必须在self.timeout / 2的时间间隔调用tmp.notify来更新修改文件的更新时间;对于Master则通过tmp.last_update来获取临时文件的最后修改时间,以此判断Worker是否还存活,这部分就是示例图中的murder_workers,它的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def murder_workers (self ):if not self.timeout:return list (self.WORKERS.items())for (pid, worker) in workers:try :if time.time() - worker.tmp.last_update() <= self.timeout:continue except (OSError, ValueError):continue if not worker.aborted:"WORKER TIMEOUT (pid:%s)" , pid)True else :
7.总结 至此,Gunicorn的主核心逻辑源码分析已经分析完毕了,可以发现Gunicorn就是一个大管家,会把获取网络请求的功能下放给下面工作的Worker,自己只负责一些Worker的管理等功能。 同时可以发现Gunicorn并不只是WSGI服务,通过自定义Worker,它也可以挂载TCP之类的应用。

 Gunicorn源码分析-Worker与Arbiter交互
Gunicorn源码分析-Worker与Arbiter交互
