
Python-gRPC实践(2)--Protocol Buffer
前言
在上一文Python-gRPC实践(1)–gRPC简介简单的介绍了gRPC采用了HTTP2作为它的传输协议,以及gRPC是如何通过HTTP2传输数据的,而本文则着重介绍gRPC所采用的序列化协议–Protocol Buffer。
1.介绍
1.1.什么是Protocol Buffer
Protobuf(Google Protocol Buffers)是Google开发的跨语言,跨平台,可扩展,用于序列化结构化数据的数据传输协议,目前已经被广泛用于服务端和客户端间的数据传输,要在项目中把gRPC用得好就必须先清晰理解Protocol Buffer的使用以及语法。
NOTE: Protobuf就像Json一样可以独立使用,不局限于
gRPC这个场景之中,我们可以基于Protobuf实现自己的数据序列化/反序列化。
1.2.gRPC为什么要采用Protocol Buffer做序列化协议
gRPC早期只支持Protobuf,最新的版本已经开始支持Json了,但是没有多少人使用。为什么gRPC一开始要选择Protobuf呢,有一个很重要的原因是Protobuf同样也是谷歌自己的产品,这样gRPC在进行功能升级的时候,Protobuf也能及时的迭代, 目前Protobuf的版本已经迭代到第3版,但是大家能接触到的只有第二版和第三版,因为第一版是谷歌之前内部使用的。
不过gRPC采用Protobuf的重要的原因是在常见的场景下,gRPC的效率要比现在大家用到的Json高一些,Protobuf的效率为什么会高呢?天下是没有免费的午餐的,有得既有失,在理解Protobuf之前我们先来看一段Json数据:
1 | |
这段Json数据是一段文本, 这就是Json效率低下的第一个点–编码低效。比如字段status对应的值true在内存中只占用1个字节,但在这个数据中却占用了4个字节, 再比如字段timestamp的值是int类型,int类型在内存中占用的空间并不大,但是在Json数据中却是以字符串呈现会占用更多的空间。
此外我们可以很快的通过这段数据看得出里面有什么内容,这是Json的一个优点,但也带来了另一个缺点–信息冗余。比如字段data的数据是一个数组,但是里面的结构是一致的,这样就会重复多传了n次的字段名。
Protobuf为了解决这些问题,首先引进了一些带有优化的编码方案,解决了编码低效的问题, 比如针对数字引入了VarInts对数字进行编码解码, 这个方案能节省数字的空间占用,同时使用的是位运算来编码解码,效率非常的高,具体可以通过详解varint编码原理进行了解。
而另一方面的改进则是去掉字段名了,改用字段编号代替,传输的时候只传输编号,这样就可以解决了冗余问题,但是这时候需要双方有一个记录编号的翻译本从而可以通过字段编号来得到真实的字段名,就像莫斯电码通信一样,而在Protobuf中proto文件就是这样的一个密码本,它记录了字段和编号的关系以及这个请求是属于哪个调用的接口和服务。
以上文Python-gRPC实践(1)–gRPC简介中的捉包结果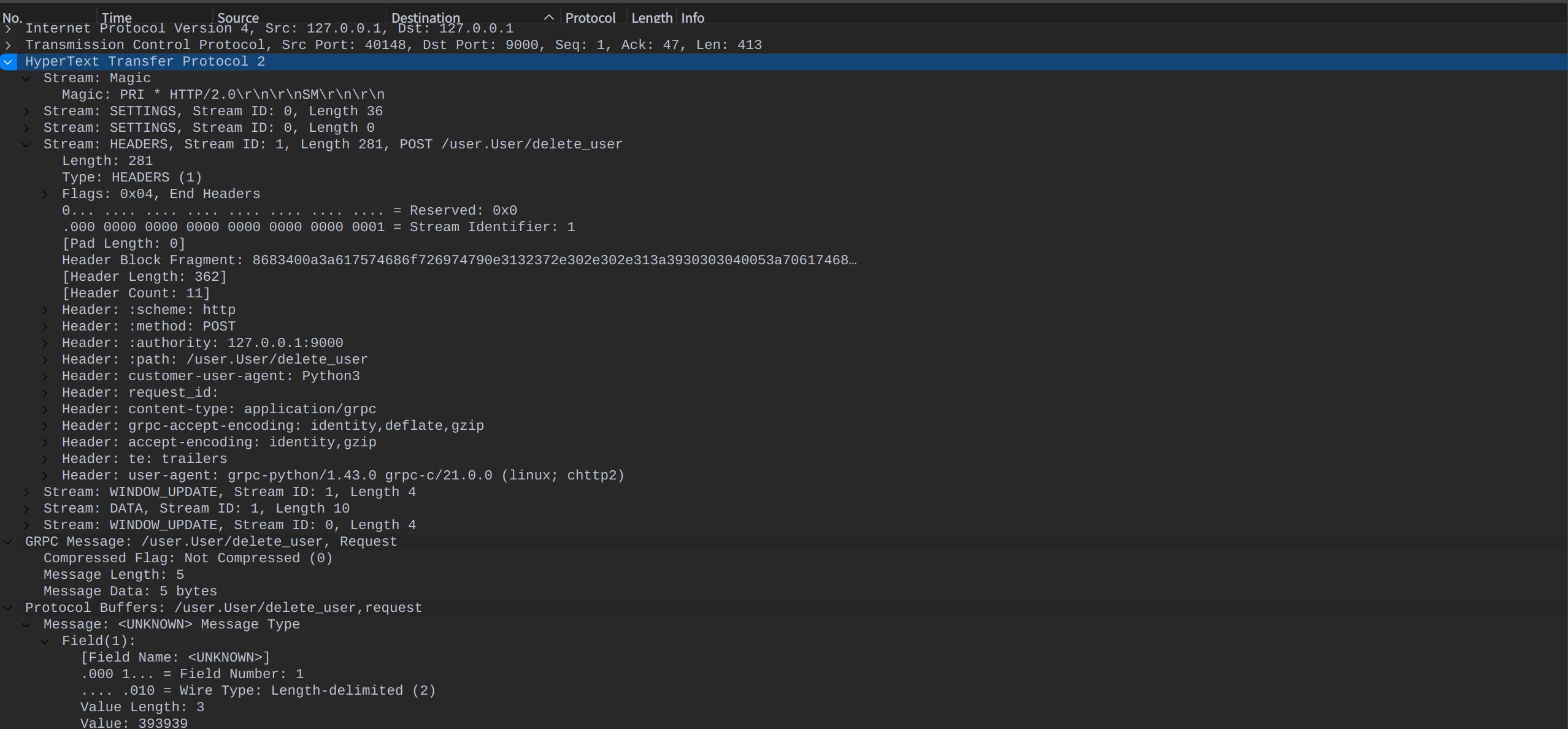 images
images
为例子,图中展示的是与proto文件:
1 | |
有关的请求,请求中表明Field为1,值为999, 接受端收到请求后就会先从proto文件查数据, 通过URL得出这个请求是service为User, rpc为delete_user的请求, 那么请求的message就是DeleteUserRequest,接下来就能知道Field为1实际的字段名是uid。
2.使用Protocol Buffer
Protobuf的编码原理是值得一看的,目前网上资料有很多,这里就先略过直接到如何使用Protobuf(实际上我目前对Protobuf的编码了解的也不是很多- -)。
从上面的示例可以看出gRPC在运行的时候需要proto文件来反查得出真正的字段数据,而gRPC是支持多语言的,那么每个语言的gRPC是如何通过proto文件来查出数据呢。
我们在编写项目时,大多都会通过一份接口代码就来生成对应的OpenAPI文件,然后其它工具如Swagger就能通过读取该文件渲染出一个API文档。而proto文件的作用也跟OpenAPI文件类似,只不过不是代码生成,而是由开发者编写的,然后开发者再通过不同的工具来根据proto文件生成不同语言的代码并放到项目工程中使用,所以要用好gRPC需要先知道如何编写proto文件(通常在使用gRPC时,也是基于Protobuf文件生成对应的调用代码)。
2.1.Protobuf语法
在介绍语法之前,先看看proto文件都内容有什么,首先我们再回头看一看上面说的proto文件:
1 | |
标准的proto文件就像这份示例文件一样可以分为三部分, 第一部分是前三行,这部分是proto文件的声明区,其中第一行标明当前proto文件的语法是proto3(没有特别说明,本文所介绍的语法都是proto3),第二行表示该文件的包名为user,这样会方便别的文件引入这个文件的定义,第三行表示导入empty.proto文件,接下来在这个文件都可以使用empty.proto文件定义的东西。
第二部分是5-8行, 这部分是消息体区, 这里定义了一个名为DeleteUserRequest的消息体,这个消息体中定义了一个名为uid的字段,且它的类型是string,字段排序是1。在实际开发中,大部分的变动都是在这一部分中发生, 且需要关注的点比较多。
第三部分是11-13行,这部分是服务定义区, 这里定义了一个名为User的服务,该服务中有一个名为delete_user的方法,且该方法接受的请求是DeleteUserRequest消息体,响应的是Empty消息体。可以简单的理解为这部分是定义一个类, 同时为每个类定义一些方法,而这些方法只拥有函数签名,没有具体实现。
了解完了Proto文件结构后,可以开始了解Protobuf语法。
2.1.1.字段编号
在编写消息体时, 最重要的一点就是字段编号, 从前面的说明可以看出, Protobuf的序列化是通过字段编号进行翻译的,所以我们要保证字段编号和字段是一一对应的, 一般的情况下我们都要遵循字段编号从1开始逐渐递增, 比如下面这个消息体:
1 | |
它的字段编号都是逐渐递增的,后面在新增字段时也要按照递增的方法指定字段编号,绝不能复用之前曾经存在的字段编号,即使是把某个字段进行重构,比如把上述的消息体进行更改:
1 | |
虽然更改后的消息体里面的age字段被brithday替换了, 但是brithday的字段编号还是递增了1,这样做是可以防止旧版本客户端在没更随服务端变动时造成数据解析异常。
不过使用字段编号递增的方法可以让开发者知道之前的编号用到哪里,但这些都是需要依赖团队的规范去实现才不会出现问题,为此Protobuf提供了reserved字段,供我们来屏蔽一些后续不能再使用的字段编号,使用例子如下:
1 | |
该例子可以避免后续的字段用到了字段编号3, 即使用到了Protobuf编译器也会报错,在源头防止问题的发生。
NOTE
之所以要求字段编号从1开始递增是因为Protobuf从message编码成二进制消息体时,字段编号1-15将会占用1个字节,16-2047将占用两个字节,优先使用1-15的字段编号将会减少数据的传输, 如果在一开始消息体的字段就比较多时, 则需要把常用的字段的字段编号安排在1-15之间。此外,19000到19999是给protocol buffers实现保留的字段标号,定义message时不能使用,如果使用了这些编号,Protobuf编译器将会报错。
2.1.2.如何使用
在Protobuf的消息体中,每个字段的类型都是固定的, 因为传输固定的类型才能减少传输资源的占用,所以我们在定义消息体的字段时,一定要结合业务需求来定义字段的类型, 以下是一个常见的Protobuf基础字段类型与Python类型的对照表:
|Protobuf类型|Python类型|Protobuf类型说明|
|–|–|–|
|double|float||
|float|float||
|int32|int|使用变长编码,该类型不擅长处理负值的数字,需要使用sint32代替|
|int64|int|使用变长编码,该类型不擅长处理负值的数字,需要使用sint64代替|
|unit32|int|使用变长编码|
|unit64|int|使用变长编码|
|snit32|int|擅长处理负值的数字,当该字段可能出现负值数字时,需要把int32改为该类型|
|snit64|int|擅长处理负值的数字,当该字段可能出现负值数字时,需要把int64改为该类型|
|fixed32|int|总是4个字节,如果数值总是比总是比228大的话,这个类型会比uint32高效,它等于int32,uint32,float的并集|
|fixed64|int|总是8个字节,如果数值总是比总是比256大的话,这个类型会比uint64高效,它等于int64,uint64,double的并集|
|bool|bool||
|string|str||
|bytes|bytes|
需要注意的是,我们虽然声明的字段没有标明他的值是多少,但是他们都有默认值:
- 字符串类型:空字符串
- 字节类型:空字节
- 数字类型: 0
- enum: 默认值的第一个元素,且值必须为0
同时,定义的消息体也是Protobuf中的一个类型,这种类型称为Message,它可以嵌套在别的Message中, Protobuf语法如下:
1 | |
它也可以通过import的语法,从a文件引入消息体到b文件,并被b文件使用, 比如在文件夹下project有a文件和b文件, 其中a文件如下:
1 | |
而b文件引用了a文件的消息体,具体代码如下:
1 | |
此外, Protobuf还支持定义其它类型,这些类型具有跟Python等价类型的用法,但是在使用的时候还是有些区别:
Timestamp:
Timestamp是Protobuf中的时间类型,Protobuf使用语法如下:
1 | |
该类型实际上是timestamp的封装,它的默认值是timestamp=0(对应到的日期是1970-01-01),在Python代码中,可以通过语法ToDatetime转为datetime,也可以通过语法FormDatetime把datetime转为Protobuf的Timestamp:
1 | |
Repeated:
Repeated 可以使该字段表重复任意次数,就像Python的Sequence对象,但是实际上可以认为是Python的List对象,Protobuf使用Repeated语法如下:
1 | |
该消息体定义了一个demo_list字段, 该字段是repeated且内部类型是int32,在Python中使用Repeated字段的方法跟使用List方法一样,但是它不是继承于List的,在部分库可能需要转换为List才能使用,比如pymysql。
Map:
虽然我们大多数都是以明确的Key-Value来定义消息体, 但是Protobuf也提供了一个类似于dict的Map,Protobuf使用Map语法如下:
1 | |
该消息体定义了一个demo_map字段, 该字段是map类型且key类型为字符串,value类型为int32,在Python中使用Map的方法跟使用dict方法一样,但是它不是继承于dict的,在部分库可能需要转换为dict才能使用,比如pymysql。
NOTE:
- Map类型的字段不能是Repeated, 因为Repeated是可变的,就像Python中Dict的Key不能是List一样。
- Map的字段是无序的。
- 如果有重复的字段,则使用最后都有一个。
Empty:
Empty是Protobuf中代表空的类型,跟Python中的None一样, 一般不用在消息体中, 而是用来标明某个rpc方法返回了空,Protobuf语法如下:
1 | |
在Python中可以通过from google.protobuf.empty_pb2 import Empty导入Empty对象并使用,不过在Python代码中最好不要把Empty转为Python的None对象, 因为Empty只是用来代表该请求点响应为空。
Enum:
在定义消息类型时, 可能希望其中一个字段只有一个预定义的值,这时就会用到枚举类型,Protobuf使用Enum语法如下:
1 | |
如语法所示, 首先在消息体创建一个名称为Status的枚举类型,然后定义类型为Status的字段status, 值得注意的是枚举定义都需要包含一个常量映射到0并且作为定义的首行,这是因为Protobuf要求定义的枚举值中必须有字段的值为0,当引用到这个类型的字段没有定义默认值时,它的默认值就是枚举类型中值为0的字段。
2.2.Proto文件管理与使用规范
实际使用gRPC来串联服务时,这些服务并不是只用一门编程语言,可能有的服务是用Python写的,有的服务是Java写的,有的服务则是用Go写的。
同时,我们在发布功能时也不是所有服务都需有更新,有的服务只需要用老接口就可以了, 比如一个服务端接口进行了更新, 这个服务端对应了很多个客户端,如果没有规范管理proto文件的话,就可能所有客户端都要进行升级,而不是只升级需要升级的客户端, 所以我们需要根据规范来管理proto文件,减少管理上带来的负担。
2.2.1.方案选择
在一开始的时候,我选用的方案是最简单的文件拷贝,这也是大多数人入门时的使用方法,它使用起来非常简单,但是代码复用率很低,项目多了之后复制文件会成为负担, 有时还需要用diff工具去对比,十分麻烦。
于是,在后续就开始考虑用版本管理工具来进行管理,由于proto文件是项目的子集,在选择方案的时候就会先联想到Git Submodul, 但是这种方案存在回滚故障点风险,同时需要为每个项目各自生产对应的proto,比较麻烦。
最后确定的方案是新建一个git仓库来存放proto文件,并以tag来区分不同的版本。
使用git仓库还有一个优势就可以利用CI/CD来自动根据proto文件生成对应语言的代码以及打包,省去的一些手动的步骤。
2.2.2.使用
首先我们需要创建一个Git仓库,把每个服务端项目的Proto文件移出来独立成一个仓库,接着就根据git flow流程来更新proto文件,不过在更新Proto文件时需要遵循下面几条规范:
- proto文件只增不减
- proto文件的接口只增不减
- proto文件的message字段只增不减
- proto文件中的message字段类型和序号不得修改
这几条规范的共性就是不对源文件进行删除,每次都只做到新增,从而保证即使proto文件发生了更改, 旧的服务在不更新的情况下也还能正常的使用。
更新完后就可以给其它项目使用了, 比如这个库当前的版本为1.0.0,我们根据git flow流程来更新proto文件并生成对应语言的代码或者release包,最后打上了对应的tag标签, 对于Python可以使用该方法来安装或更新依赖:
1 | |
而对于Java这类的则可以使用打包成一个release版本交给maven使用。
3.最后
现在已经初步的了解了gRPC以及Protobuf的使用方法,接下来将通过一个简单的项目来演示如何使用gRPC
- 本文作者:So1n
- 本文链接:http://so1n.me/2022/02/05/Python-gRPC%E5%AE%9E%E8%B7%B5(2)--Protocol%20buffer/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

