RPC框架编写实践-RPC常见限流方法的实现
前记
在微服务中, 虽然服务间的调用都是可信的, 但是服务端也需要堤防一些流量, 防止被意外的流量击垮, 而通过限流可以防止问题的发生。此外, 使用不同的限流规则还能根据系统间不同服务的请求进行限制, 解决某个函数被频繁调用而拖垮整个系统的问题。
NOTE: 虽然本文是在编写RPC框架有感而发, 但是也适用于常见的Web服务等有流量进出的场景。
1 限流的简介
1.1 限流的作用和场景
对于后端服务来说, 他们提供的服务都有一个极限的QPS(除代码逻辑外,也跟机器配置有关), 当服务端的压力超过这个极限值的时候, 服务端的响应性能就会快速的下降, 然后无法提供服务, 所以服务端需要一个类似于可以限制请求数的功能, 使服务端能牺牲掉部分请求, 保证还能处理一定量的请求, 防止服务端出现压力瓶颈,无法处理所有请求。
不过这个功能还需要尽量的智能, 在设计时可以根据流量场景不同来做有差别的限制, 使其在不影响其它请求的情况下, 实现部分请求的网络流量整形, 达到减少系统资源消耗的效果, 常见的几种需要做差别限制的场景如下:
| 场景 | 可能造成的影响 | 限流的作用 |
|---|---|---|
| 总体的API有大量的并发调用, 导致系统QPS超过设计值 | 机器可能会扛不住, 造成系统崩溃 | 减少进入业务的流量, 保证QPS被限制在某个合理值, 其它请求会被丢弃 |
| 某个API耗时比较长, 其它API的QPS位于合理范围内 | 由于API耗时较长, 该API的调用次数变多的情况下, 会明显消耗系统资源, 同时也可能造成数据竞争的情况 | 针对性的限制耗时API, 防止该API引起系统崩溃 |
| 总体API的QPS位于合理范围内, 但是有部分参数会引起较大的系统资源消耗 | 比如某个筛选参数造成查全表的情况, 此时可能造成数据库处理能力下降,进而造成后端服务无响应 | 针对性的根据耗时API的参数进行限制限制, 防止该API引起系统崩溃 |
| 总体API的QPS位于合理范围内, 但某个API的某个参数被大多数人调用, 导致整个API无法提供服务, 比如微博的话题功能, 如果有个爆炸性话题, 这个话题就会成为热点参数 | 造成整个API无法使用, 严重时会造成整个服务不可用 | 通过对热点参数的限制, 保证其它功能能正常使用 |
1.2 限流的组件
通过上述场景可以看到, 在这些场景中限流的作用是差不多的, 一般只涉及到两个维度:
- 时间: 对某个时间窗口进行限流
- 资源: 针对某个API或者某个API的参数进行限流,达到保护后方对应的资源。
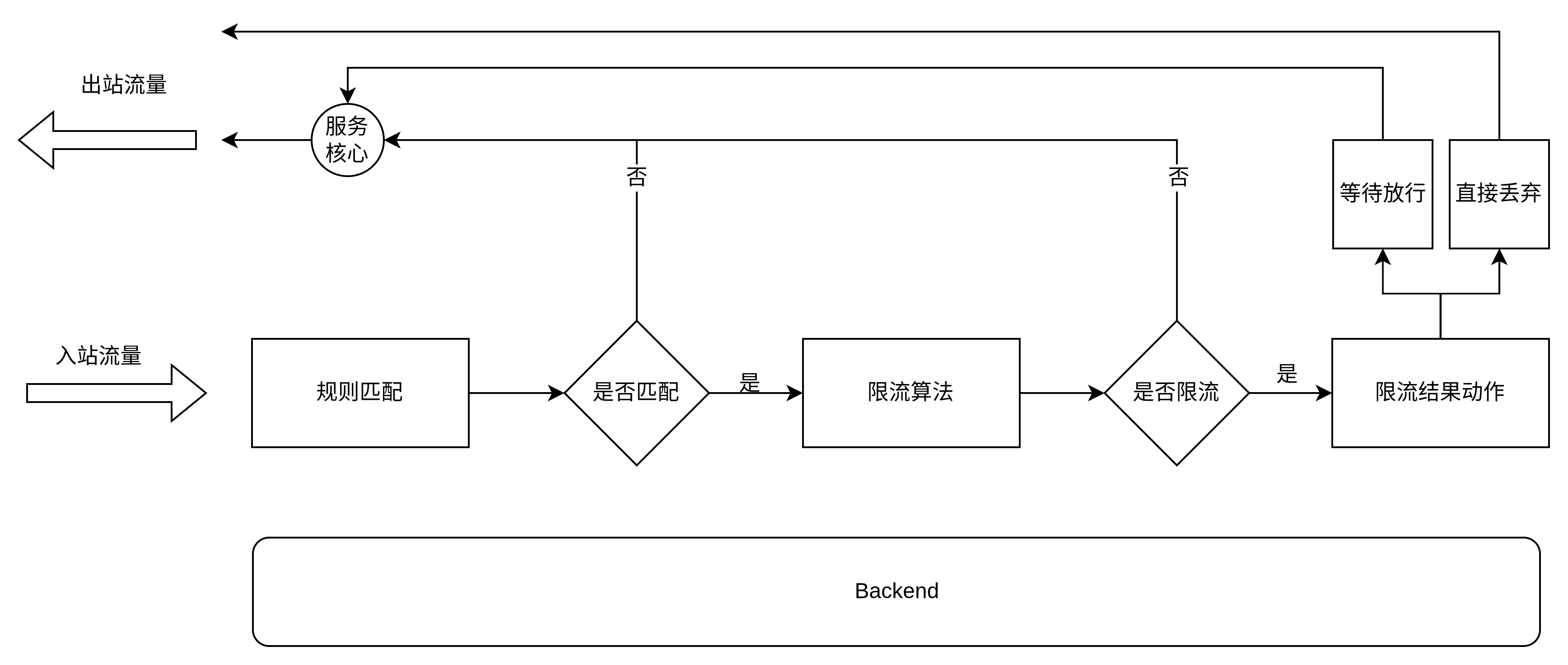
限流可以保证在某段时间内的某个资源的请求数量不会超过设计值, 达到保护系统的作用, 不过不同场景主要差别是限制的资源维度不一样, 资源维度的变化从总体服务到某个API到某个API的某个参数, 资源维度越来越细, 而这个资源维度区分也就是我们要实现限流的第一步–流量匹配, 只要流量匹配了, 限流系统就可以开始工作了, 一般的限流系统流程图如下(其中他服务核心代表微服务核心):
限流
流程图中第一步是规则匹配, 它会通过一个函数把流量提取出来, 当做Key, 这个Key等于某个资源, 然后判断这个Key是否匹配到规则, 如果命中规则就开始执行规则并结合这段规则和限流算法来判断该流量是否限流, 如果限流就丢弃或者等待, 如果没被限流, 就直接放行。
此外, 流程图的最下层有一个很大的Backend, 它可以用来存储规则以及存储一些限流相关的计算变量。
其中,限流相关的计算变量都是跟时间相关的, 且每次都要进行读写, 最好的情况是放在内存之中,不过它不能跟请求绑定在一起, 因为跟当前请求的生命周期不一样, 不能在发送请求结束后就把变量回收了, 这些变量也需要有个容器可以存储, 供不同的请求读写, 但是在一个集群服务中, 每个机器都只存储自己的计算变量则会导致多台机器没办法共享数据而造成限流失败。
比如针对某个用户可以调用某个API的规则是一秒内可以请求十次, 目前有十台机器, 他们不会互相共享自己的限流计算变量, 那么在最坏的情况下, 用户可以在1秒内访问100次请求而不被限流, 这样是达不了限流的效果的, 所以限流必定是一个中心化的应用。
目前两个比较主流的限流方案分别是网关限流和中间件限流, 网关限流场景下所有入站流量都会经过网关这个单体, 然后由网关决定是否放行;而中间件限流则是把计算变量都存在某个中间件存储中, 然后每个服务的限流组件都可以从中间件实时写入和读取数据, 其中最常用的中间件是Redis, 因为Redis的速度快, 能让限流组件很快的判断是否需要限流, 对机器的性能开销占比也不是很多, 同时Redis支持的数据结构和功能非常的多, 我们可以很容易的基于它来实现不同的限流算法。
至于限流的规则, 由于它只要写入一次, 后面都是以读为主, 所以在网关场景下都存在于内存之中, 但在中间件场景下规则都是存在一个集中式存储中, 如Etcd, 然后每个服务会同步集中式存储的规则, 并写入到自己的内存中。
在实际的落地要选择网关限流还是中间件限流主要还是取决于是服务的应用场景, 比如接口外层都有加一层网关, 那采用网关限流即可, 如果是内部服务或者该服务的通信协议是自定义的, 则采用中间件方式, 有比较强的自定义性。
在使用
Redis下的某些情况下(取决于搭建方式), 有可能造成数据不准的情况, 但是限流的频率是允许有些许误差的, 比如限流的规则是1秒可以访问100次, 但在某些时候只实现了1秒访问110次也是没太大关系的。
1.3 限流算法
上面所说的都是一些简单的概念, 而限流的核心是在于限流算法的实现, 常见的限流算法有以下几种(由于大多数都限流backend默认是Redis, 所以以可以在Redis运行的lua代码示例):
1.3.1 固定窗口
固定窗口的原理比较简单,就是将时间切分成若干个时间片,每个时间片内固定处理若干个请求。比如限流规则是10秒内最多处理5个请求, 那么就会有一个容器来统计这10秒内的请求数, 如果容器的统计数量大于5, 那么后续的请求都会被拒绝, 然后每隔10秒重置这个容器的统计。
这种实现非常简单, 但不是非常严谨, 假如限制规则是1秒限制100个, 但在最坏的情况下, 在第一个窗口的0.5秒后到第二个窗口的0.5秒前的这个时间点共计会放行200个请求, 所以固定窗口只适用于一些要求不严格的场景, 通过下图的左图可以看到限流的流程, 通过下图的右图可以看到整个限流曲线不平滑。
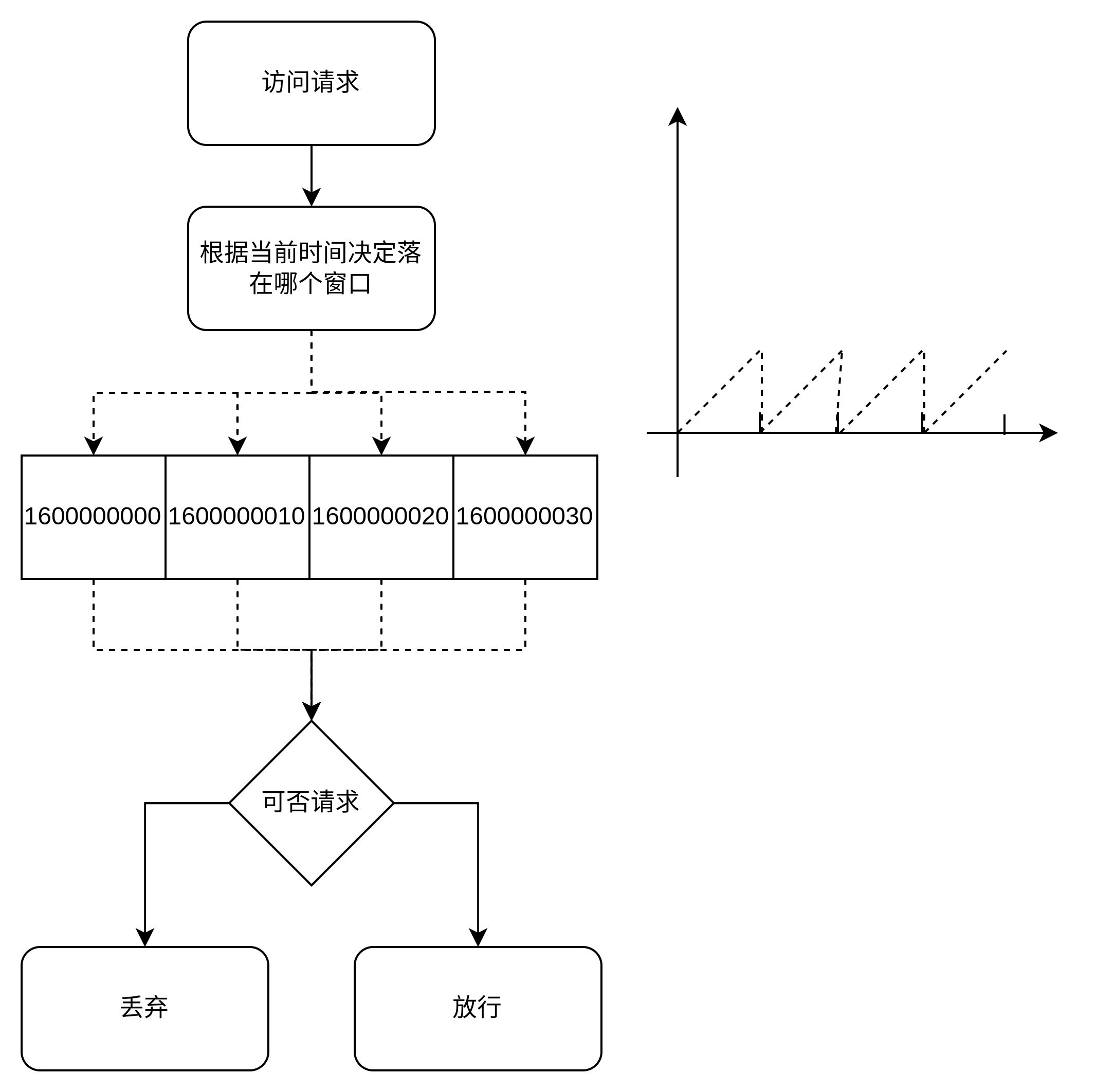 固定窗口
固定窗口
固定窗口的实现很简单, 在Redis中的lua代码如下:
1 | |
1.3.2 滑动窗口
滑动窗口是固定窗口的改进方法, 他是通过增加窗口数量使限流算法更顺滑, 本身从一个窗口变为一个先进先出的队列, 队列的内容是更加精细的窗口,比如原来是10秒一个窗口, 现在会改为1秒一个窗口, 然后每隔一秒钟滑动一个窗口。 只写入最新的窗口而读取判断时都是取最近10个窗口, 这样就可以通过减小粒度来让限流算法更加精细, 可以看到波动幅度会变小(取决于精细程度):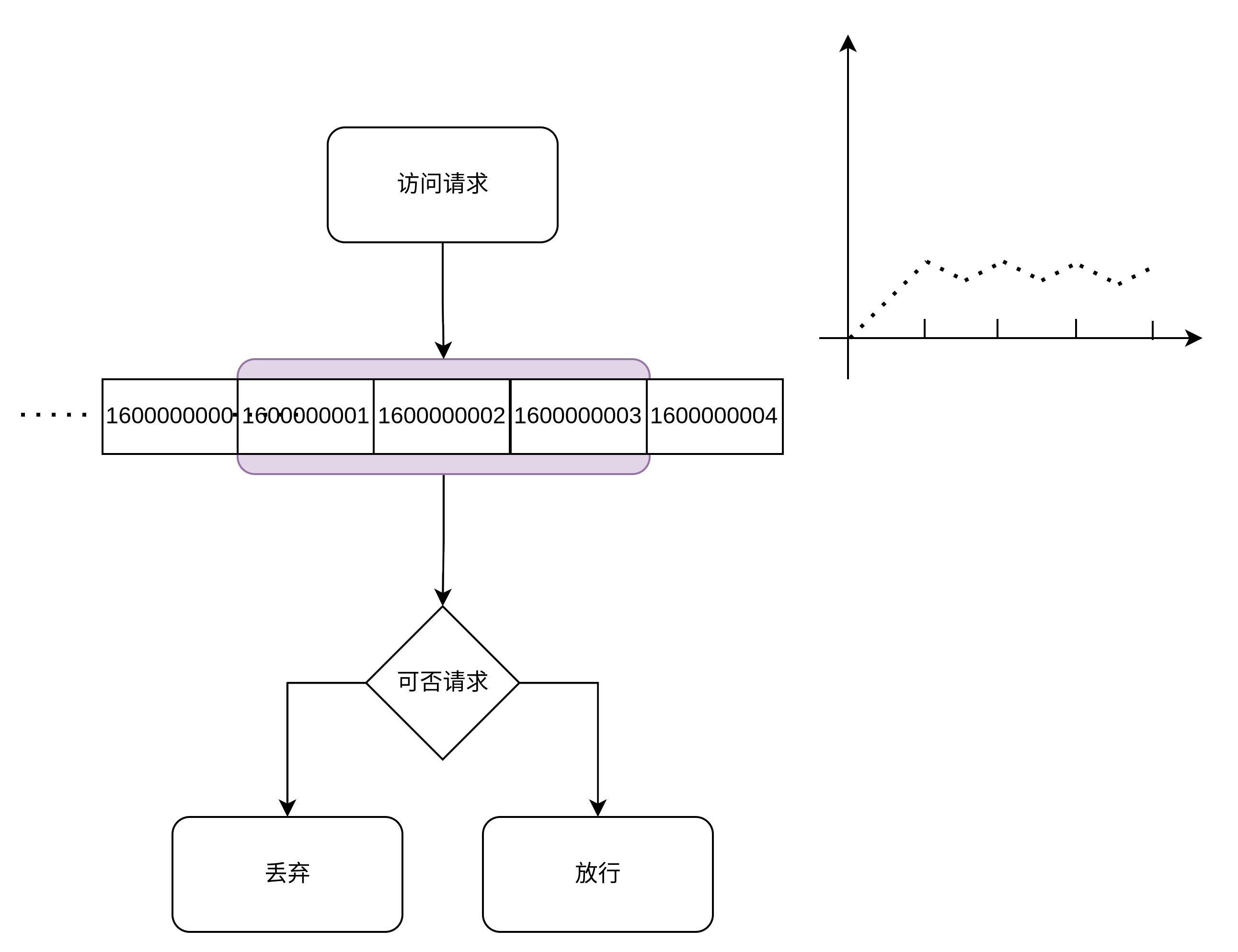 滑动窗口
滑动窗口
滑动窗口的实现也是很简单的, 具体见:RPC框架编写实践–服务治理的基石, 在Redis可以采用Zset数据结构进行实现, 这里就不做代码示例了。 滑动窗口是牺牲一定的内存来让限流变得平滑,窗口数量越多, 限流速率越精细, 占用的内存就越大, 同时获取数据时都是获取一批窗口的数据, 相比于固定窗口来说,它的时间复杂度也会跟着变多(O(k))。
1.3.3 漏桶
漏桶的出现可以完美的解决参差不齐的速率限制问题, 漏桶算法的核心原理是进入漏桶的请求量不限制, 但能漏出去的速率请求是恒定的, 这样就能完美的控制请求的速率, 如果桶满了, 在漏桶里的请求就会溢出去, 达到丢弃请求的目的, 如下图, 整个请求的速率都是很平滑的, 没有多少毛尖: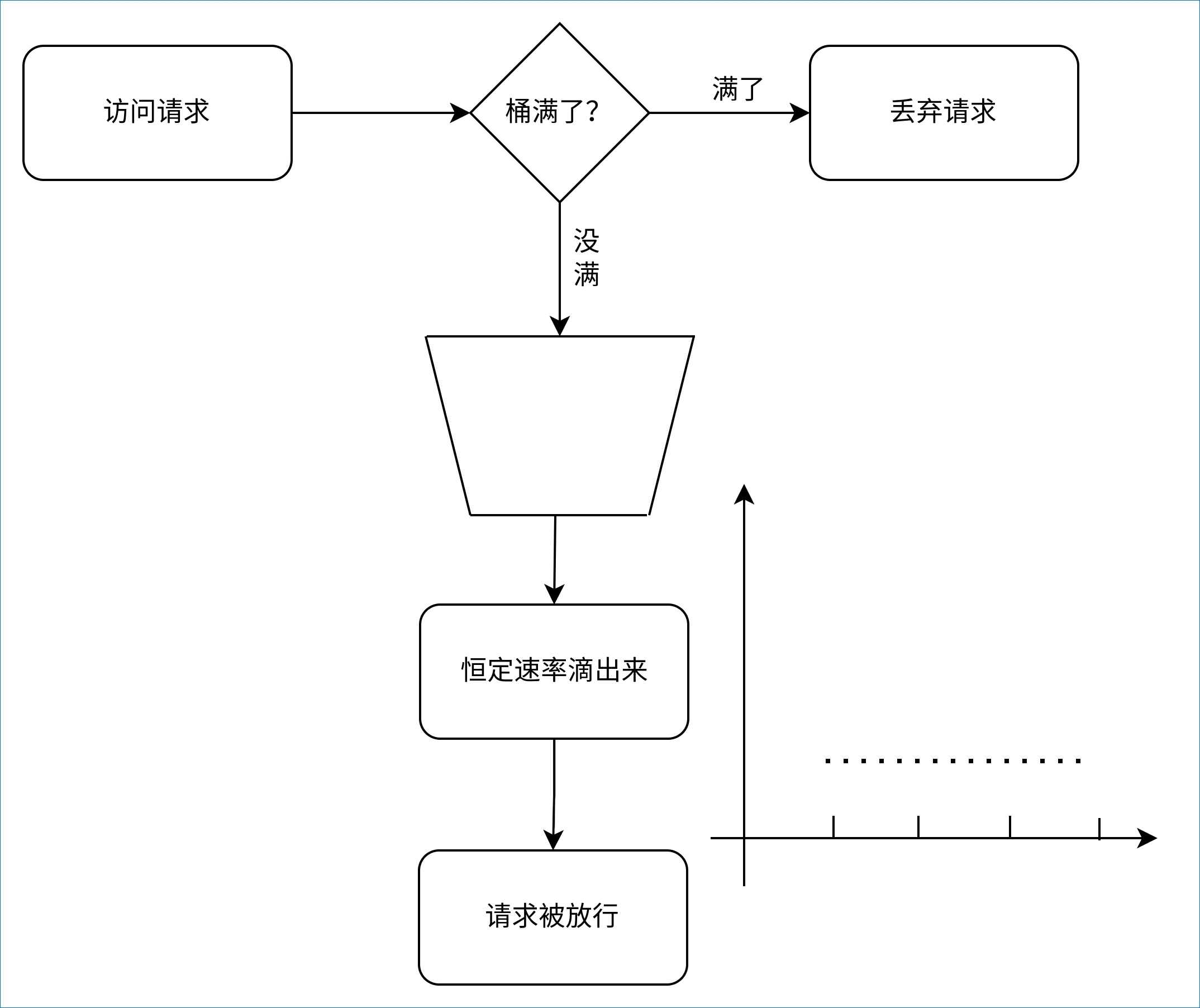 漏桶
漏桶
从图中可以看到, 漏桶的原理很像一个FIFO队列, 然后有个定时器会以恒定的速率把请求取出来, 使用Python代码实现如下:
1 | |
但是, 这样实现的漏桶算法依然需要占用一些空间用来存储等待放行的请求, 直到放行才被释放。 为了解决空间占用的问题, 可以采用GCRA算法, 它从另外一个角度看起来跟漏桶算法很像(GRRA应该被认为是计量器实现的漏桶版本, 而不是上面所说的队列形漏桶), 但很省空间占用, 因为无论漏桶多大, 它的空间占用都是恒定的, 只需要存漏水速率(可以认为是该时间段可以放行的请求量)以及桶目前的容量即可。
使用GCRA算法之所以能这样省空间, 主要还是它是基于虚拟调度实现的, 它只需要存一个漏水速率,然后每次有请求进来时判断现在可否可以漏水, 如果可以就放行, 如果不可以则判断桶是否满, 满则抛弃请求, 没满则让请求等待, 直到可以放行为止。
常见的GCRA限流实现一般都考虑使用redis-cell, 它的使用方法如下:
1 | |
从命令可以看出, 即使漏斗中还有数据没漏出去, 返回值得第一个也还是0, 表示放行, 这样并不是一个完善的GCRA。 为了实现一个完备的GCRA, 我们需要额外的在代码判断漏桶是否全空, 如果放行且桶不是全空, 则需要在代码判断多久后才能会为空, 这个时间也就是请求的等待放行时间, 在等待这段时间后才能放行请求, 如果不是放行, 则直接丢弃请求即可。
不过, 如果不做任何判断, 直接使用返回值的第一个值来判断是否放行请求, 那这个实现就很像下面所说的令牌桶的实现。
1.3.4 令牌桶
漏桶能很好的控制速率, 使其变得平滑, 但是它没办法应对突发流量, 比如我们把规则定义为10秒内可以请求10次, 对于漏桶来说, 它会控制为1秒放行一个请求, 如果同时收到10个请求时它则会分开10秒放行每个请求。 然而10秒内可以请求10次的含义是10秒内总共可以请求10次, 也就是允许在这10秒内的某个瞬间同时放行10个请求, 对于这个问题可以使用令牌桶来解决, 令牌桶和漏桶很像, 只是漏桶控制的是请求, 令牌桶控制的是令牌发放速度。
令牌桶算法规定每个请求需要从桶里拿到并消耗一个令牌才可以放行, 拿不到则会被抛弃, 同时令牌桶本身会以恒定的速率产生令牌, 直到桶满为止, 这样就可以保证限流的平缓, 同时又能应对突发请求, 令牌桶的原理图和限流曲线图如下, 其中限流曲线图表示初始时桶里面放满了令牌, 所以放行的请求很多, 随着令牌被逐渐消耗并消耗光了, 限流的曲率会稳定在一条线上, 也就是令牌的生产速率: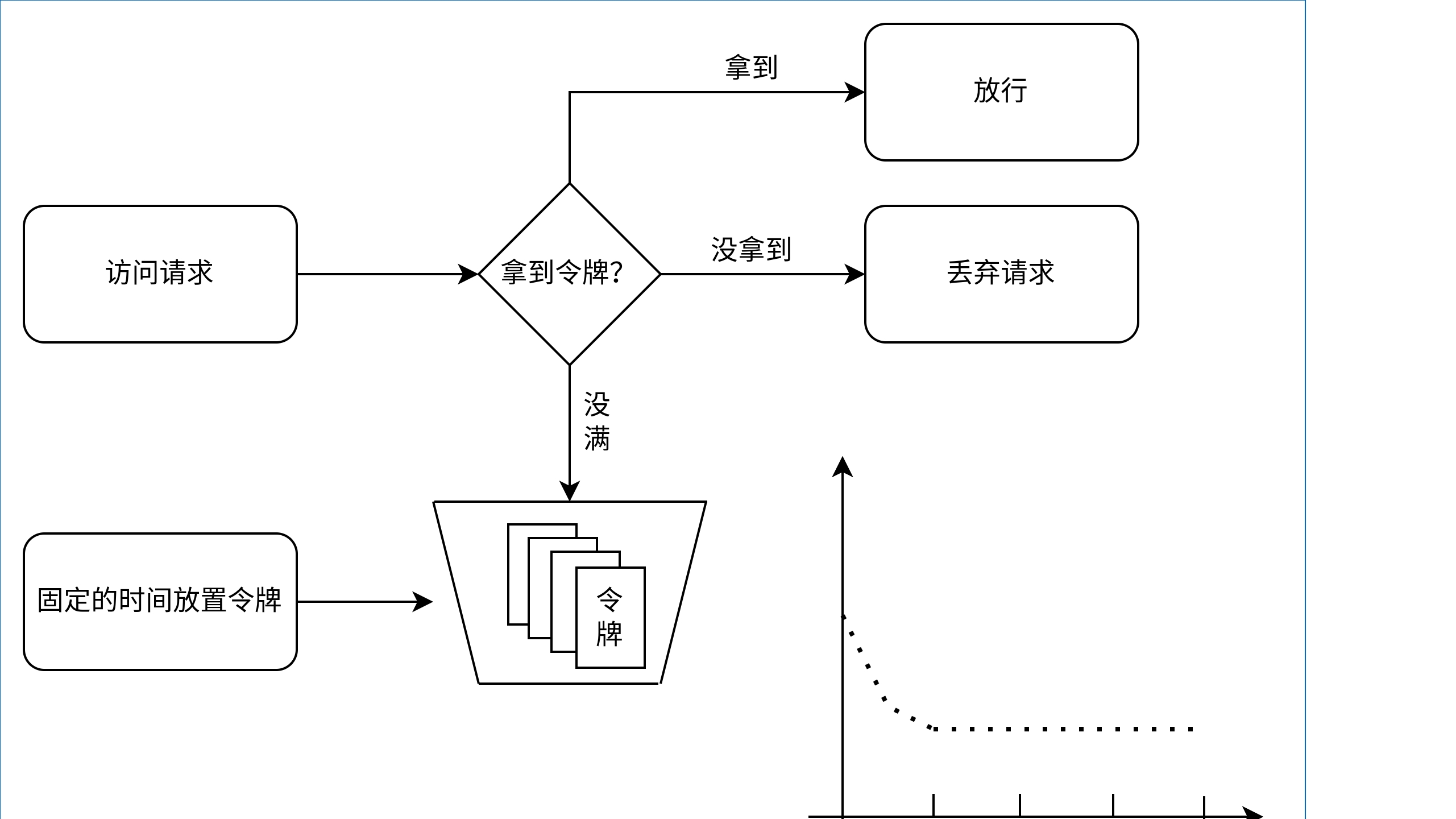 令牌桶
令牌桶
同样的, 在实现令牌桶时为了减少空间的占用, 也会使用虚拟调度方法, 只存一个时间和容量到内存中, 每次收到请求时都会根据请求的时间和在内存中的时间差值再乘以速率计算这段时间应该产生的令牌数量并存到内存中, 然后再判断是否有足够的令牌来判断是否放行请求, 具体的Redis lua代码实现如下:
1 | |
2.具体实现
上面说完了算法实现后, 接下来来看看该如何结合算法进行实现, 由于代码会随时更新,具体源码更新见: https://github.com/so1n/rap/tree/master/rap/server/plugin/processor/limit
项目的代码结构如下, 在常见的后端服务中需要占用空间少, 然后速度尽量快点限流组件, 所以一般只用漏桶或者令牌桶且基于Redis的实现, 这里就不会去实现窗口相关的限流了:
1 | |
首先是rule.py里的规则类, 它主要是声明了限流速率, 初始化token数量, 最多的tokens数量以及停用时间, 其中停用时间是用来防止恶意用户频繁刷新, 它的逻辑是当漏桶已经满了或者令牌桶没有令牌的时候, 限流组件会在停用时间内不再提供服务。
然后就是backend.base.py, 它是一个限流算法的统一封装, 代码如下:
1 | |
这个类它声明了两个方法, 一个是can_request, 它会根据算法来判断是否放行, 如果需要等待, 则会在这个方法里进行等待, 直到到时间后才返回放行标记, 其中can_request还内嵌了一个block_time的逻辑; 另外一个是expected_time, 用来获取下次可用的时间, 具体的实现以RedisCellBackend为例子, 它是一个子类。
它的最上层实现是BaseLimitBackend, 然后就是继承于BaseLimitBackend的BaseRedisBackend, 这个组件Redis限流算法的基础实现, 主要是实现了一个停用时间的逻辑, 当发现不放行请求的时候, 会启用停用逻辑, 以停用后续相同key的请求:
1 | |
接着就是继承于BaseRedisBackend的BaseRedisCellBackend, 它主要是提供一个命令调用的封装以及获取还有多久后才能请求的封装:
1 | |
最后就是真正的对外使用的限流组件实现, 这个实现是基于漏桶算法的, 它继承于BaseRedisCellBackend(另外一个继承于BaseRedisCellBackend的实现是基于令牌桶算法的, 可以通过源码了解), 可以看到非常的简单, 本质上是基于redis-cell的返回判断是否放行。
1 | |
了解完算法的实现后, 接下来就是核心的判断逻辑, 具体见注释:
1 | |
至此, 整个限流逻辑实现完毕, 本章内容完。
3.其它碎碎念
3.1.热点参数实现
由于大部分的限流实现的backend都只要依赖于Redis, 所以代码仓里面只有Redis一种类型的backend,但是有一些限流实现需要依赖于一些特殊的backend,比如热点参数限流, 还有蜜罐之类的场景。
以热点参数限流场景为例子, 热点参数是一个写大于读的应用场景, 而且跟时间强相关, 所以选用时序数据库做backend,之前选用过Graphite当做backend, 具体实现如图后端服务会把每次请求参数都记录到时序数据库中, 并使用一个定时脚本每隔一段时间把最近的热点参数数据拉取到缓存中, 供后端服务的限流组件判断是否该放行。 其中, 这个间隔一般控制在1秒左右, 所以这是一个近实时的实现, 具体的实现图如下: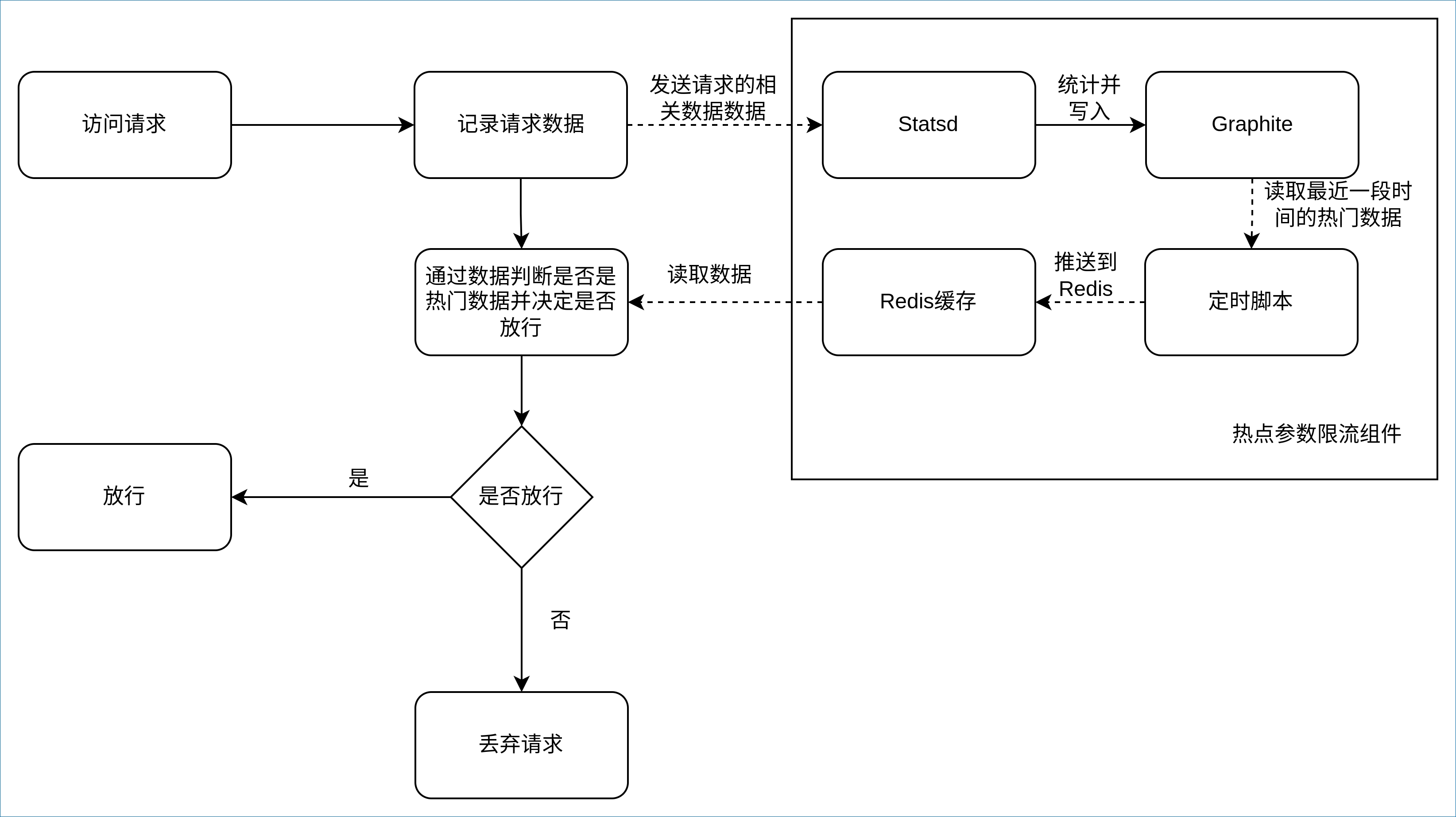
当请求进来的时候, 限流中间件会通过异步的方法把数据记录到时序数据库中, 比如一个请求为http://127.0.0.1:80?q=1&b=2,中间件就会发送一个以{prefix}.hot_param.b=2&b=2为key, value为1的标准Statsd的count类型数据到Statsd组件中。
这个Key采用标准的
Statsd命令, 以.分割有三个值, 第一个是前缀它与业务相关, 如业务名, 函数名,namespace等等; 第二个是代表是热点参数的业务; 第三个是参数Key, 这里以&为分割号, 然后按Key顺序排序,重新拼接为一个字符串, 这样即使请求时顺序不一致也能识别到时同种请求。
Statsd组件收到了数据后会自行进行统计, 统计一个时间区间都数据并写入到Graphite中, 然后通过定时脚本使用Graphite API拉取统计次数大于条件的数据写入到Redis缓存中, 其中Statsd组件的时间区间和定时脚本的定时时间都会控制在一秒左右, 所以这是一个近实时的实现, 在计算性能消耗和实现效果直接做取舍。
数据写入到Redis后, 这个写入数据和统计的异步流程就结束了, 中间件在记录数据后, 会通过Redis判断是否是热点参数, 并根据规则判断是否放行, 到了这里就跟上面的限流流程差不多了。
3.2.限流算法拓展
限流算法不止是用于算法, 也可以用于别的地方,比如有一些游戏活动,体力值满时为5, 然后玩家每次出发活动会减少1个体力值, 然后可以使用限流算法每隔一个固定时间则增加一个体力值等等。 在遇到业务需求有跟时间相关且像上述所说的体力值会恢复的情况时, 可以往限流算法思考。
- 本文作者:So1n
- 本文链接:http://so1n.me/2021/11/15/RPC%E6%A1%86%E6%9E%B6%E7%BC%96%E5%86%99%E5%AE%9E%E8%B7%B5--%E5%B8%B8%E8%A7%81%E9%99%90%E6%B5%81%E6%96%B9%E6%B3%95%E7%9A%84%E5%AE%9E%E7%8E%B0/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

