RPC框架编写实践--服务治理的基石
前记
由于服务的调用是通过网络间来调用了, 服务并不在同一个进程内, 程序可能崩溃、节点可能宕机、网络可能中断,这些意外情况其实全部都在意料之中, 微服务的一个思想就是, 所有假设会出错的东西一定会出现, 而且没办法完全避免, 只能通过一些功能去增加容错性, 稳定性和可用性, 这类功能被统称为服务治理, 大部分功能都会利用过去一段时间产生的数据来决策接下来的请求该怎么做, 而这些数据就是服务治理的基石。
1.指标数据
在服务治理中的一些常见功能如限流、 负载均衡、 熔断器、监控统计等等都需要一些指标数据(Metric), 有了这些数据, 大部分的服务治理功能才得以实践。
指标数据在服务治理中的位置非常重要, 它是过去一段时间内收集再统计的数据, 不是实时数据。 不直接使用实时数据是有原因的, 比如每秒QPS之类统计好的数据, 如果每次使用时都统计一次, 不仅麻烦, 还浪费性能, 而且每秒QPS的关键点是每秒, 意味它的间隔要精确到秒, 实时数据的话间隔不可控的可能大于或者小于秒; 再比如监控的数据, 它是一个单位时间内的数据汇总,而不是实时数据, 因为实时的数据会带来较大的计算开销。 对于一个监控系统来说, 实时地收集数据会让机器的CPU没有停歇的时间, 同时硬盘会被写满大量的数据, 但是有很多数据都是没用到的, 所以最好的方法就是每隔一段时间写入该时间区间内的汇总数据, 而间隔时间的大小则取决于监控的精度和计算性能之间做取舍。
由指标数据的变化可以看出这些数据会经历汇聚, 固定两个阶段, 汇聚阶段只能写入/更新数据, 不可读, 固定数据只可读不可写入, 同时机器一切的资源都是有限的, 我们不会无限的存储汇总数据, 所以指标数据还会有销毁阶段, 这三个阶段每个阶段都有自己的特点:
- 汇聚阶段(可写): 当前的数据不可用, 会随着时间发生变化, 比如被重新设定一个新值, 或者被累加累减等
- 固定阶段(可读): 当前的数据仅可读而不可写入。
- 销毁阶段(不可写不可读): 当前的数据不可读不可写, 只能等待被清理。
此外指标数据的状态是不可逆的, 而且会跟随着触发条件而发送变动, 当条件触发时, 固定阶段的状态会变为销毁阶段, 汇聚阶段的状态会变为固定阶段, 然后重新诞生一个新的汇聚阶段来收集数据。
2.通过滑动窗口实现一段时间内的数据收集统计
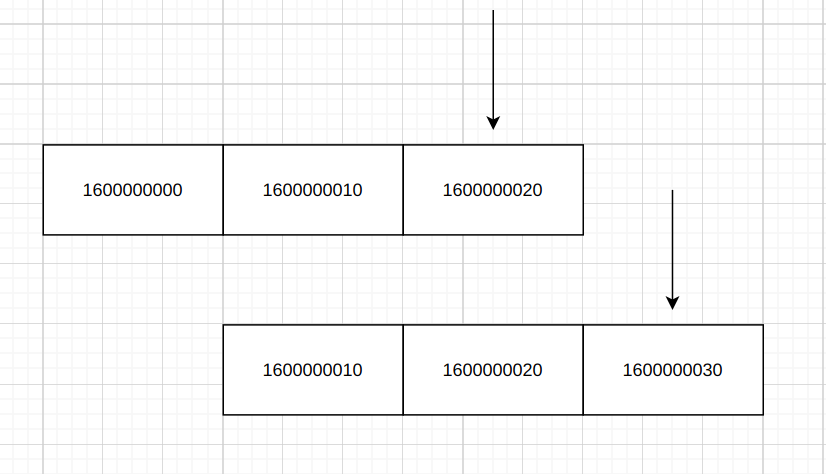
假设把每个指标数据的状态当成一个槽, 这个槽可以存很多Metric, 而且会随着固定的时间定向变动, 那么这时它的原理就会跟滑动窗口一模一样, 如下图, 指针指到的槽为汇聚阶段, 指针-1的槽为固定阶段, 指针-2的槽为销毁阶段:image.png
从图中可以看到, 一开始指针指向的是1600000020这个窗口, 当下一个窗口时间时, 指针指向1600000030, 而1600000000的窗口已经消失了。
同时从图中可以发现, 这个时间窗口只有3个, 而最后一个是待回收的, 没有别的操作, 对于带有GC的语言来说, 直接移除该对象的引用后就会被GC统一回收, 十分方便, 我们在实现的时候可以把固定阶段切换为销毁阶段的方法变为指定该槽的指针被移除, 随后槽就会被GC移除, 这时候需要操作的就只剩两个槽了, 而两个槽的实现就非常简单, 直接把指针进行替换即可, 以下是一个简单的实现:
1 | |
里面有三个方法, set负责把数据存入到汇聚桶中, get负责从固定桶获取数据, 两个方法调用的是不同的桶, 而replace_dict的方法就是负责替换桶。 那么, 该怎么确保每个窗口时间到的时候进行切换呢, 由于我的RPC框架是基于Asyncio的, 所以会考虑用到Asyncio来进行调度,在Asyncio中有个loop.call_at的方法, 用于指定几时执行这个函数, 假设间隔时间为10秒, 可以把方法改为:
1 | |
之后只要事件循环一直在运行, replace_dict从第一次被调用后就会被一直运行, 而且是通过事件循环运行的, 还不会出现最大递归的问题。
但是这里会暴露出两个问题, 一个是当窗口时间非常小时, 比如1秒, 这时候事件循环调度的误差会被扩大, 因为调度是非常复杂的, 它只能尽量的确定在那个时间点附近能调用到, 误差有多少会由很多的复杂因素共同决定的(对于线程调度等也是一样的原理);另一个问题是当这个窗口时间被限定为1秒时, 如果要统计2秒的数据, 只能另开一个时间窗口为2秒的统计, 如果要统计3秒的数据, 就只能再开一个时间窗口为3的统计…以此类推, 会非常麻烦, 需要一种好的统一的方法来处理。
启用一个线程在后台循环, 每隔n秒自动切换这个方案看似没问题, 但是线程也是由调用器来调度的, 当时间窗口再小一些时,也会暴露一些问题。同时我会在切换数据那里会调用一些钩子函数, 所以也会增加间隔的误差, 该方案不可采纳。
3.通过时间轮实现一段时间内的数据收集统计
上面说到, 滑动窗口的方案会暴露出两个问题,导致使用体验上没那么好, 需要解决掉。
首先是第一个问题: 交由调度在自动切换时会存在一些调用误差。 这个问题的核心是, 数据跟时间是强相关的, 所以一定会依赖于时间, 数据的读写必须要跟时间相关, 而上面时间窗口的方案使用的是被动切换的, 他会降低时间的准确性, 那被动方案不行就可以反过来, 使用主动切换。
主动切换的逻辑是根据操作时的时间来判断要操作哪个槽, 再读取数据或者写入数据(性能会稍微降低), 这个方案需要把读写的逻辑改一下:
- 1.首先存储的数组要把销毁阶段的槽复原,不然在极端的情况下写入和读取的下标可能会一致的, 这时候这个数组的长度为3, 然后记录一个开始时间。
- 2.假设间隔为1秒, 每次读写数据时, 就会根据当前时间与起始时间的差除以1再与数组长度求出余数, 余数的范围在0, 1, 2之中,而这个0, 1, 2刚好是存数据的数组的下标范围, 随着时间的推移, 得到的下标会一直以0, 1, 2, 0, 1, 2一直循环变化着。
- 3.基本逻辑都搞定了, 但是每次读取数据的时间是不固定的, 比如第一次写入数据时, 刚好命中下标0, 第二次写入数据时, 刚好命中下标2,如果刚好遇到读数据1, 这时候要识别这里1的数据并不是有效的, 同时0, 1, 2这样一直循环着, 1可能已经走到第二轮了, 2还是第一轮的数据, 所以这时候就需要有个变量来标记轮数, 而轮数也很简单, 就是当前时间与起始时间相差再于时间间隔取商。
大概逻辑了解完了, 可以把上面的代码进行改写, 改写完代码如下:
1 | |
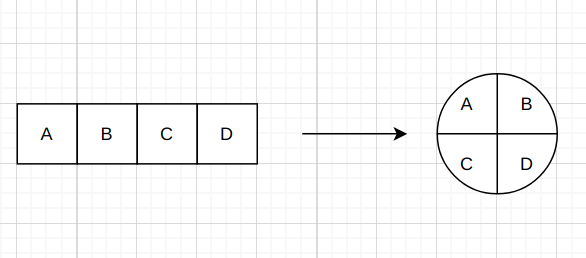
代码非常简单, 移除了replace_dict这个被动切换的逻辑, 改为每次set和get来计算应该落到哪个区间。 这样第一个问题就解决了, 可以来考虑第二个问题, 从问题一中的代码可以发现里面的bucket_list虽然是一个数组, 但通过时间和数组长度算出的商来获得下标会一直以0, 1, 2, 0, 1,2循环, 所以实际运行起来就像一个时间轮一直转着,新的轮次的数据会覆盖旧的轮次, 而这个时间轮的槽总量不变的, 如下图(draw.io画出来的有点点丑):
 uTools_1629791108206.png
uTools_1629791108206.png
而时间轮也是刚好可以解决问题二的一个方案, 首先假设我们的时间间隔为60秒, 如果要兼容1秒, 2秒,3秒,4秒,5秒等多种的时间间隔统计, 那么就可以取他们的最小公因数1作为一个子间隔, 它需要60个槽位, 我们可以把时间轮当成一个整体, 然后把这个时间轮切为60个等份的槽, 再通过时间来算出指针要指向哪个槽位(指针会跟着操作时间与时间轮总槽数取的余数来变化), 写数据时会写入指针指定的槽位, 这个槽位也就是汇聚数据槽, 而指针逆时针方向后面的槽位根据是否有数据来区分固定槽和空槽(初始化时, 所有槽位都是空槽, 第一次写了数据后就只能成为固定槽或者汇聚槽), 取数据只能取当前指针后面的, 且是本轮的数据且不为空槽的数据 。
然后1秒间隔的统计只取指针后面一格的槽数据, 2秒间隔的统计只取指针后面两格的槽数据求和, 3秒间隔的统计只取指针间隔后面三格的槽数据求和, 以次类推, 这样就能以一个类来兼容多种时间间隔的统计了。不过这个方案有个缺点, 就是上述的时间轮有60个槽位, 一个槽被定义会数据汇聚槽, 那剩下的最多只有59个固定槽可以获取数据, 还缺少一个槽位, 这时候就需要进行补槽处理, 比如60个槽就可以拓展为65个槽, 然后限制只能获取最近的60个槽即可, 剩下的5个槽可以用来当做缓冲位, 重新更改后的代码如下:
这个方案是兼容小范围的数据, 使用1分钟的时间间隔来兼容秒级的时钟间隔, 如果要兼容大范围的时间间隔, 比如5分钟, 10分钟,15分钟等等, 则可以采用指针式时钟一样的方案。 如果你了解
Kafka的时间轮设计, 就可以知道Kafka有多层时间轮, 小层转动一层, 大层就转动一格(就像秒指针跑完一圈, 分指针就动一格一样), 等到大层的数据的到期时间范围小于等于小层时, 数据就会流向小层。不过服务治理的数据还是需要尽量的有效, 所以它的时间跨度一般不会超过一分钟。
1 | |
上面的代码是一个简单的实现, 为了做到可用, 还需要增加一些逻辑, 以及优化读写的一些性能, 同时还可以根据自己的需求增加一些功能, 比如我在实现时就增加了一些功能:
- 在指标数据中, 会区分
Gauge和Count两种, 一种是稳定实时变化的, 对应的只获取最新的固定数据槽的数据即可, 一种是累加的, 要把这段时间的所有槽位数据都累加起来, 为了能做到区分, 需要为每种数据都加上类型标识。 get的方式比较繁琐, 如果能缓存起来会好一些, 减少读取时的性能损耗。或者有些数据需要被动的等待推送, 这时候还是可以调用上面的callback模式, 比如每5秒调用一次, 虽然5秒执行一次数据, 但是由于时间轮的存在, 这时候还是可以获取最近一轮的数据的。
最后实现起来的代码会比较长, 可以访问我在rap框架中实现的代码collect_statistics.py
- 本文作者:So1n
- 本文链接:http://so1n.me/2021/08/24/RPC%E6%A1%86%E6%9E%B6%E7%BC%96%E5%86%99%E5%AE%9E%E8%B7%B5--%E6%9C%8D%E5%8A%A1%E6%B2%BB%E7%90%86%E7%9A%84%E5%9F%BA%E7%9F%B3/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

