
Scrapy爬虫(1)-爬取知乎用户信息
阅读scrapy后做了一个简单的scrapy爬虫
Scrapy爬虫(1)-知乎
第一次用Scrap创建的爬虫,详细记录下
完整代码请访问这里,不过代码可能有所不同
-1.前记
本来是昨天弄好代码,今天写文章的。然后今天早上在逛台风吧看台风天鸽状况,天鸽近岸爆发加上机构被妮妲狼来了戏耍后都保持谨慎态度,珠海到早上上班时间后才挂红色预警,澳门则到了快登录才挂10号风球,珠三角没有做好防范,还有近岸爆发和赶上天文大潮导致受灾加重,希望那里灾情不重。付上两张图,一张是澳门海水倒灌一张是天鸽高层图,很像鸽子头 enter description here
enter description here enter description here
enter description here
0.思路验证
在创建这个工程前,我先用段代码来检验基本功能可否运行
知乎可以不用登录获取用户信息,对我来说,方便太多了,而且知乎的查看关注页面那里同时显示有个人用户信息所以直接访问:https://www.zhihu.com/people/(token)/following
就可以找到我要的信息了(虽然关注列表只有20个,不过无所谓)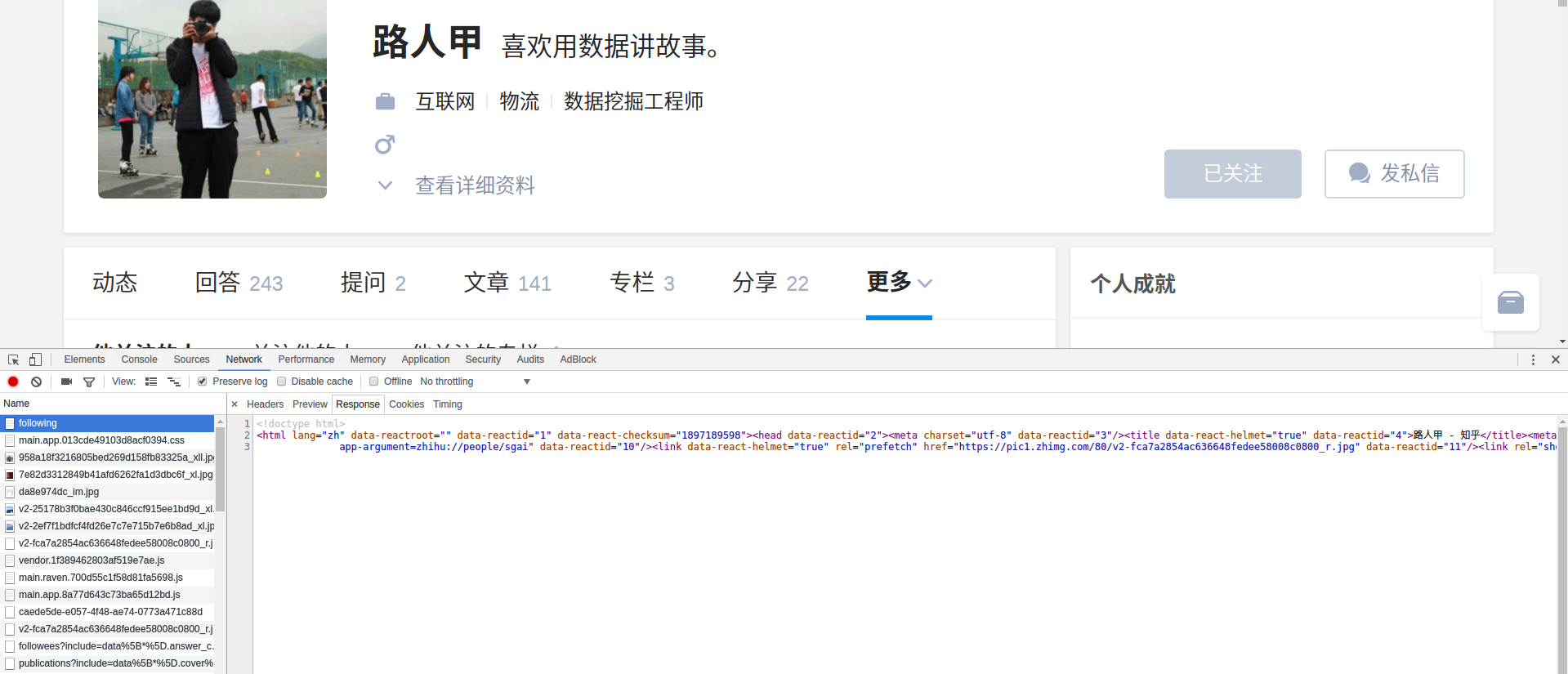 enter description here
enter description here
提取信息如图,直接copy这段数据去相应网站分析后,可以得出我要的数据在两个部分,
一个是在[‘people’][‘followingByUser’][urltoken][‘ids’]
另一个是在[‘entities’][‘users’][urltoken]
找到后就可以写代码开始爬下来了。
不过知乎的json会有空,比如这个用户没有学校的值时,json就没有相应的节点,如果直接爬就会报错,然后我也没有找到比较简便的处理方法,就写了try…except(如果用了对象,一个方法来复用,最后代码量也差不多,我就放弃了)
代码如下:
1 | |
呈现的结果部分如下:
1 | |
由此知道我的想法可以运行起来,所以开始创建工程
1.创建工程
整个流程:从起始url中解析出用户信息,然后进入关注者界面和被关注者界面,提取关系用户ID和新的用户链接,将用户信息和关系用户ID存储到MongoDB中,将新的用户链接交给用户信息解析模块,依次类推。完成循环抓取任务
在终端输入
1 | |
之后会在当前目录生成以下结构
1 | |
2.创建爬虫模块
在终端输入
1 | |
这里是用scpry的bench的genspider
语法是scrapy genspider[-t template] <name> <domain>
可以用模板来创建spider
之后spider文件夹下面会多出一个zhihu_com.py的文件,里面有段代码为:
1 | |
其中
name是定义spider名字的字符串,它是必须且唯一的
allowed_domains是可选的,它包含了spider允许爬取的域名列表。当OffsiteMiddleware组件启用是,域名不在列表中的url不会被跟进
start_urls为url列表,当没有使用start_requests()方法配置Requests时,Spider将从该列表中开始进行爬取
重新回到开头看到
1
class ZhihuComSpider(CrawlSpider):
Spider有3大类,最基本的是Spieder,他的属性有name, allowed_domains, start_urls,custom_settings,crawler,start_requests().除了Spieder外还有CrawlSpider和XMLFeedSpider。
CraelCpider除了从Spider继承过来的属性外,还提供了一个新的属性rules,rules是一个包含一个或多个Rule对象的集合,每个Rule对爬取网站的动作定义了特定的规则。如果多个Rule匹配了相同的链接,则根据它们在rules属性中被定义的顺序,第一个会被使用。
Rule类的原型为:
1
scrapy.contrib,spiders.Rule(link_extractor,callback=None,cb_kwargs=None,follow=None,process_links=None, process_request=None)
参数说明
link_extractor 是一个LinkExtractor对象,定义了如何从爬取到的页面提取链接。
callback回调函数接受一个response作为一个参数,应避免使用parse作为回调函数
cb_kwargs包含传递给回调函数的参数的字典
follow是一个布尔值,指定了根据规则从respose提取的链接是否需要跟进
然而,知乎跳转到关注人的链接不是完整的,而是类似/perople/xxx/following的,crawlSpider没办法识别,所以不能使用rules(或者是我食用crawlSpider方法不对?我都弄了半天了)
了解了这样多,结果我就直接套上去,不使用rules,因为我的链接不是从网页里面提取的,要自己创造的
直接把url注释掉,因为CrawlSpider属于Spider类,所以调用parse解析就好了
1
2
3
4
5
6
7
8
9
10
11
12class ZhihuComSpider(CrawlSpider):
name = 'zhihu.com'
allowed_domains = ['zhihu.com']
start_urls = ['https://www.zhihu.com/people/sgai/following']
#rules = (
# Rule(LinkExtractor(allow=r'/people/(\w+)/following$', process_value='my_process_value', unique=True, deny_domains=deny), callback='parse_item', follow=True),
#)
def parse(self, response):
然后到setting.py下面更改3个数值
1
2
3
4
5
6 请求头
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
关闭robot
ROBOTSTXT_OBEY = False
关闭cookies追踪
COOKIES_ENABLED = False
3.解析网页
解析网页直接照搬我之前测试是否可以运行的代码,并进行了相对应的修改
- 建立一个url存放列表,进行url去重
- 从网页捕获用户urltoken
- tempset部分用户存在没有none存在的情况,捕获错误并pass
- description部分存在有些用户含有html代码,但是我不知道怎么去除只获取中文。。。。
- 把获取的数据封装到item里面
- 判断捉取的用户列表有没有存在False(用户关注数量低于20个就会出现,由于直接返回False,所以直接用if判断)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73def parse(self, response):
deny = []
html = response.text
soup = BeautifulSoup(html, 'html.parser')
token = soup.find("a",{"class":"Tabs-link"})
pattern = r'e/(.+)/ac'
urltoken = re.findall(pattern, str(token))[0]
json_text = soup.body.contents[1].attrs['data-state']
ob_json = json.loads(json_text)
followinglist = ob_json['people']['followingByUser'][urltoken]['ids']
tempset = set(followinglist)
try:
tempset.remove(None)
except:
pass
followinglist = list(tempset)
user_json = ob_json['entities']['users'][urltoken]
user_info = user_json['headline']
try:
school = user_json['educations'][0]['school']['name']
except:
school = '该用户尚未填写'
try:
major = user_json['educations'][0]['major']['name']
except:
major = '该用户尚未填写'
try:
job = user_json['employments'][0]['job']['name']
except:
job = '该用户尚未填写'
try:
company = user_json['employments'][0]['company']['name']
except:
company = '该用户尚未填写'
try:
description = user_json['description']
except:
description = '该用户尚未填写'
try:
business = user_json['business']['name']
except:
business = '该用户尚未填写'
try:
zhihu_name = user_json['name']
except:
zhihu_name = '该用户尚未填写'
try:
location = user_json['locations'][0]['name']
except:
location = '该用户尚未填写'
gender = user_json['gender']
if gender == 1:
gender = '男'
elif gender == 0:
gender = '女'
else:
gender = '未知'
item =UserInfoItem(urltoken=urltoken,user_info=user_info, job=job, company=company, description=description, business=business, zhihu_name=zhihu_name, location=location, gender=gender, school=school, major=major)
yield item
#print(followinglist)
for following in followinglist:
if following:
url = 'https://www.zhihu.com/people/'+following+'/following'
#else:
#url = 'https://www.zhihu.com/people/'+urltoken+'/following'
if url in deny:
pass
else:
deny.append(url)
yield scrapy.Request(url=url,callback=self.parse)
4.定义item
定义两个item
1 | |
5.Pipeline
定义一个Pipeline,让scrapy把数据从item存入到mongodb数据库里面,配套设置在settings.py里面
1 | |
6.其他补充
6.1.利用middlewares.py实现ip代理
配到设置在settings.py里面
1 | |
6.2setting设置
请求头添加
1 | |
激活item和中间件
1 | |
激活随机爬取时间
1 | |
MONGODB配置
1 | |
ip代理列表
这个ip我是从免费代理IP拿的,测试一下ip代理是否可行,我的ip代理池捉不到什么有效 ip了- -。。。
1 | |
7.结果
用几个数据测试一下是否有保存,要爬取全部的话还要等重新换个ip代理池 enter description here
enter description here
7.优化与补充
- Scrapy 自定义settings–简化编写爬虫操作–加快爬虫速度
- v2ex讨论《scrapy 抓取速度问题》
还有scrapyd部署和scrapyd-client部署见上一篇文章
- 本文作者:So1n
- 本文链接:http://so1n.me/2017/08/23/13-scrapy-zhihu-easy/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

