简单的爬一下微博以及发微博
微博爬虫-发布微博以及获取微博资料 1.发布微博 首先要解决登录问题(为了减少限制我们使用移动版本登录),这里我采用cookie来登录enter description here enter description here enter description here https://m.weibo.cn/api/statuses/update enter description here
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import reimport requests'User-Agent' : 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Mobile Safari/537.36' }"Cookie" : "你的cookie" }'https://m.weibo.cn/compose' r'st:(.+)' 0 ].replace("'" ,'' ).replace(',' ,'' ).replace(' ' ,'' )'https://m.weibo.cn/api/statuses/update' 'st' :st,'content' :'测试Python发微博!' ,
在这里我用正则找出来,不过加了‘’就找不到了,所以只能粗略找出来再把不要的替换掉,接着就可以传入postdata进行发微博了enter description here
2.爬取评论 其实这个是我爬取一半遇到个坑,然后百度后找到的教程- -。。。这里
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 from lxml import htmlimport requestsimport jsonimport reclass CrawlWeibo :def getWeibo (self,id ,page ):'https://m.weibo.cn/api/container/getIndex?type=uid&value=' +id +'&containerid=107603' +id +'&page=' +str (page)'cards' ]return list_cardsdef getComments (self,id ,page ):'https://m.weibo.cn/api/comments/show?id=' +id +'&page=' +str (page)'hot_data' ]return list_commentsdef printAllTopic (self,page ):'1713926427' ,page)for card in list_cards:if card['card_type' ]==9 :id =card['mblog' ]['id' ]'mblog' ]['text' ]if re.search('___' , text)!=None :print (u"### 话题: " +text+'\n' )id , 1 )1 for comment in list_comments:'created_at' ]'like_counts' ]'text' ]'string(.)' )'user' ]['screen_name' ]'source' ]if source=='' :u'未知' '' if 'pic' in comment:'pic' ]['url' ]print (str (count_hotcomments),': **' ,name_user,'**' ,u' **发表于:**' +created_at,u' **点赞:**' +str (like_counts)+u' **来自:**' +source)print (text+'\n' )1 print ('***' )1 )
其实就是不断的解析JSON来获取自己想要的enter description here json.cn 查看enter description here enter description here enter description here
1 2 3 4 5 6 7 8 def getComments (self,id ,page ):'https://m.weibo.cn/single/rcList?format=cards&id=' +id +'&type=comment&hot=1&page=' +str (page)'card_group' ]return list_comments
3.爬取微博内容 原来我写的有点乱,不好的代码还是扔在电脑里面好了。现在爬取微博内容直接对以上获取到的list_cards解析就行了,不过图片有3种形式,分别是缩略图,压缩图,原图
1 2 3 "thumbnail_pic ":"http ://wx1 .sinaimg .cn /thumbnail /6628711bgy1fca7isjl7nj215o15o167 .jpg ",bmiddle_pic ":"http ://wx1 .sinaimg .cn /bmiddle /6628711bgy1fca7isjl7nj215o15o167 .jpg ",original_pic ":"http ://wx1 .sinaimg .cn /large /6628711bgy1fca7isjl7nj215o15o167 .jpg ",
4.爬取用户信息 这个栗子同样也是使用移动版微博来获取资料(我这里是从我关注列表里面获取的)enter description here https://m.weibo.cn/api/container/getSecond?containerid=1005051896662273_-_FOLLOWERS&page=2 这个containerid这个不知道是什么,之前也没看过。所以重新跑回主页查看enter description here
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 "card_type" :10 ,"user" :{"id" :5909185172 ,"screen_name" :"拜托啦学妹" ,"profile_image_url" :"https://tva1.sinaimg.cn/crop.0.0.976.976.180/006rUl0gjw8f4uuscl9p5j30r40r410i.jpg" ,"profile_url" :"https://m.weibo.cn/u/5909185172?uid=5909185172&luicode=10000012&lfid=1005051896662273_-_FOLLOWERS&featurecode=20000320" ,"statuses_count" :390 ,"verified" :true , 有没有认证"verified_type" :0 , -1 为没认证。0 为个人认证,其余为企业认证"verified_type_ext" :1 , _ext 为1 时(橙色V), _ext 为0 (黄色v)_ext "verified_reason" :"微博知名搞笑视频博主 教育视频自媒体 微博签约自媒体" , 认证说明"description" :"一个只属于大学生的街访" , 简介"gender" :"f" , 性别:f为女m为男"mbtype" :12 , 12 都是个人账户,0 也是。2 有个人账户也有企业账户,11 也是企业账户"urank" :27 , 等级"mbrank" :5 , 会员等级"follow_me" :false , 是否关注我"following" :true , 我是否关注他"followers_count" :5445128 , 粉丝数量"follow_count" :69 , 关注量"cover_image_phone" :"https://tva1.sinaimg.cn/crop.0.0.640.640.640/549d0121tw1egm1kjly3jj20hs0hsq4f.jpg" ,"desc1" :null, "desc2" :null
然后就可以获取了,结果如下:
1 2 3 4 5 6 7 8 9 10 id: 5364707424 姓名: Just春苑 简介: 🐮 等级: 9 性别: m 是否关注我: True id: 5406572240 姓名: 魅蓝手机 简介: 等级: 17 性别: m 是否关注我: False id: 3230122083 姓名: Flyme 简介: Flyme是魅族基于Android内核为旗下智能手机量身打造的操作系统,旨在为用户提供优秀的交互体验和贴心的在线服务。源自内心的设计,做最本质的思考,Flyme定会让你刮目相看! 等级: 35 性别: m 是否关注我: False id: 5608433557 姓名: 微博雷达 简介: 等级: 5 性别: f 是否关注我: False id: 1861358972 姓名: 气势如虹Leslie 简介: 去认识更广阔的世界 等级: 16 性别: m 是否关注我: True id: 1992613670 姓名: 凤凰新闻客户端 简介: 等级: 37 性别: m 是否关注我: False id: 2629306884 姓名: CSDN产品客服 简介: 还在为你的下载积分太少发愁吗?快来参加CSDN做任务,拿积分活动~~攒下载积分啦~~http://task.csdn.net/rule.aspx 等级: 21 性别: f 是否关注我: False id: 2251036402 姓名: Colombo丶Fd 简介: 等级: 14 性别: m 是否关注我: True id: 1720064601 姓名: RNF_牧牧子 简介: |后院43024|轮协3.0|脱了一半的伪宅|世上稀有的腐男|绝对领域万岁|我终于过了CCIE|全(部)球(类)通 等级: 31 性别: m 是否关注我: True id: 2472362284 姓名: RNF_某清 简介: 微不足道。 等级: 22 性别: m 是否关注我: True
这部分内容的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import reimport requestsimport jsonfrom lxml import etree"Cookie" : "你的cookie" }'https://m.weibo.cn/api/container/getSecond?containerid=1005051896662273_-_FOLLOWERS&page=7' 'cards' ]for card in list_cards:if card['card_type' ] == 10 :id = card['user' ]['id' ]'user' ]['screen_name' ]'user' ]['description' ]'user' ]['urank' ]'user' ]['gender' ]'user' ]['follow_me' ]if gender == 'm' :'男' if gender == 'f' :'女' else :'其他' if follow_me:'是' else :'否' 'id:' , id , '姓名:' , name ,'简介:' , description ,'等级:' , urank, '性别:' , gender ,'是否关注我:' , follow_me)

 enter description here
enter description here enter description here
enter description here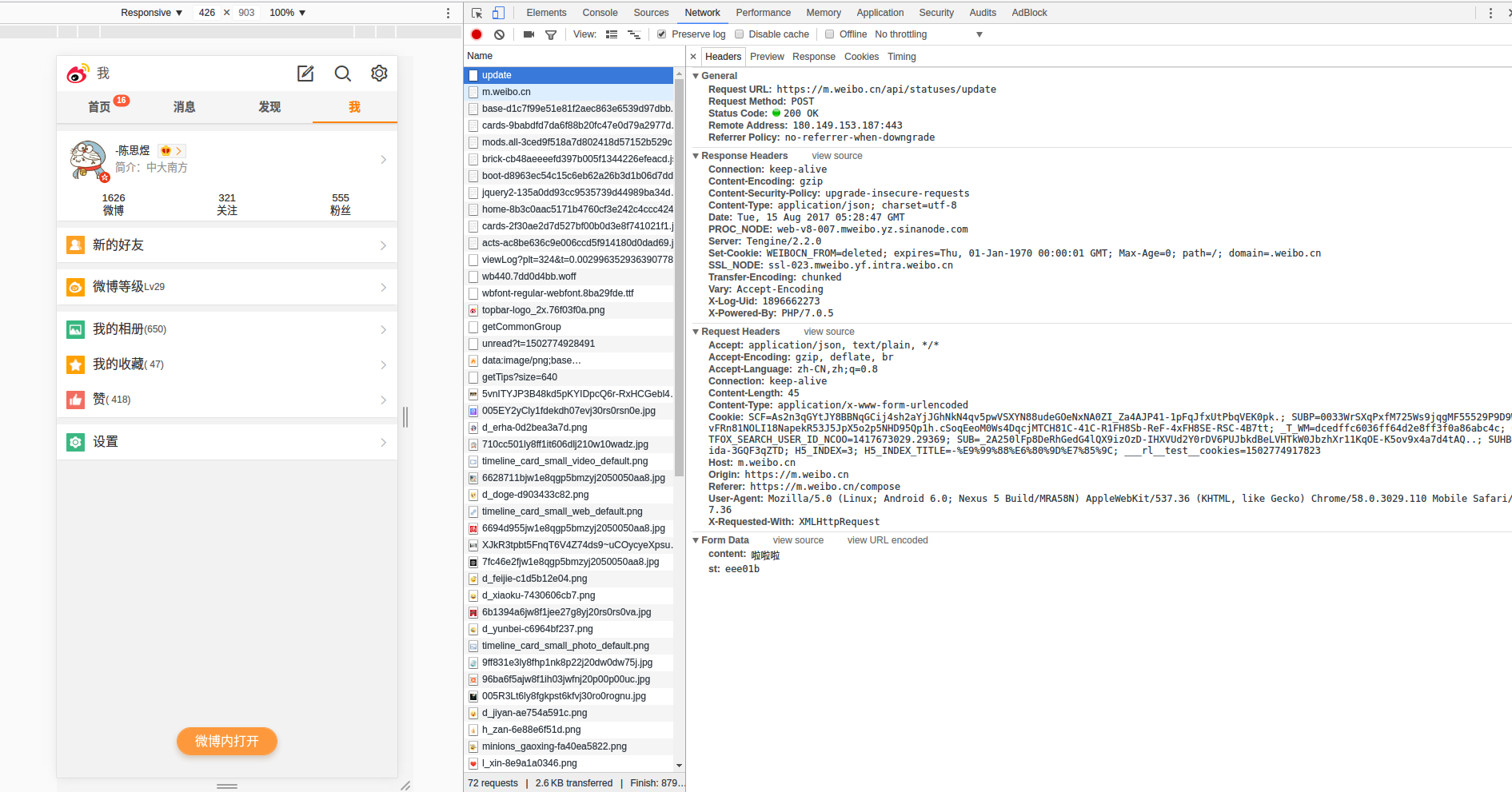 enter description here
enter description here enter description here
enter description here enter description here
enter description here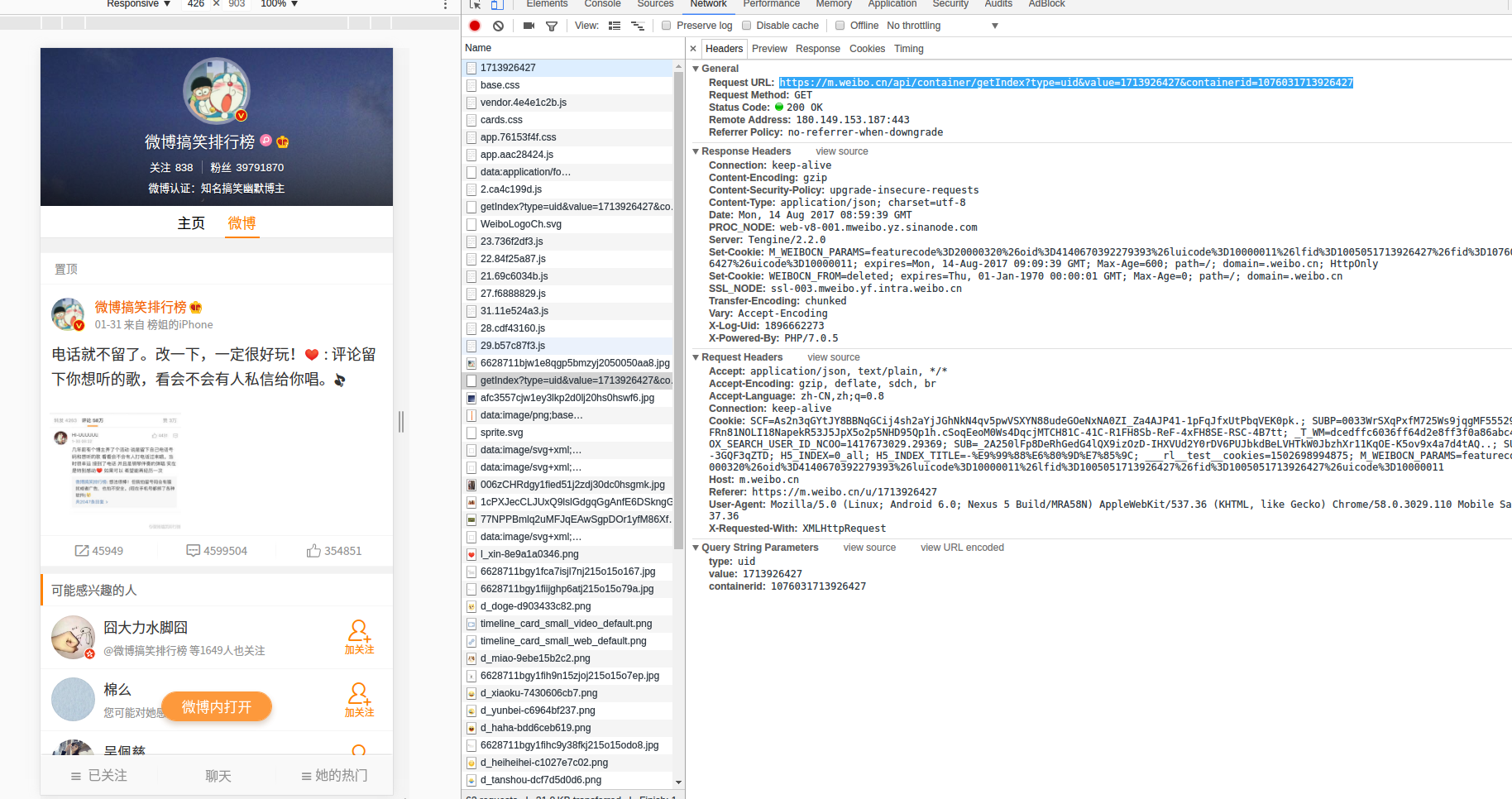 enter description here
enter description here enter description here
enter description here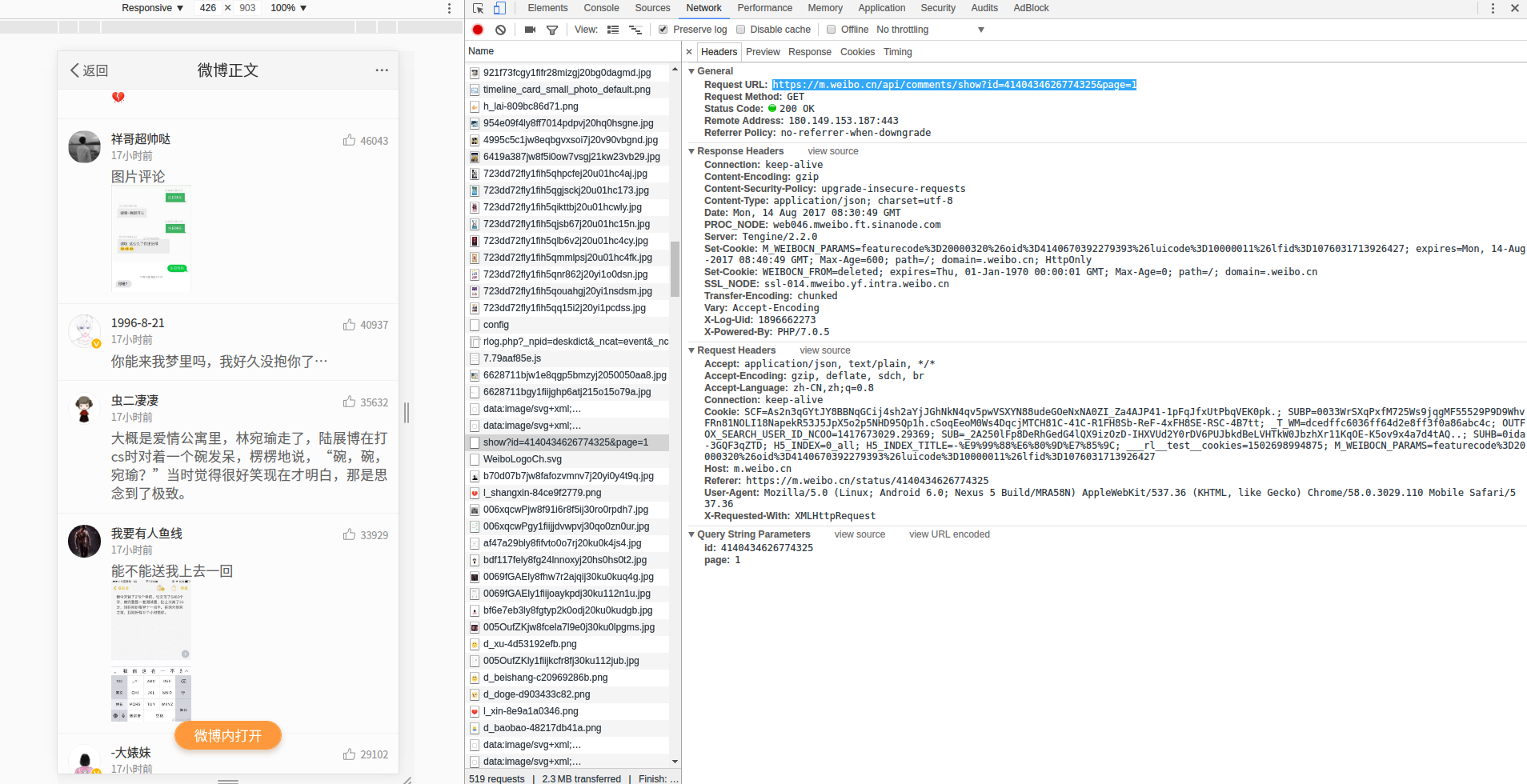 enter description here
enter description here enter description here
enter description here enter description here
enter description here enter description here
enter description here
