
[爬虫-豆瓣读书]
这是一个直接用别人的代码copy后再加上自己的想法来实现的小项目
这是一个直接用别人的代码copy后再加上自己的想法来实现的小项目
爬虫入门项目实战
1.寻找项目
2.修改项目
原来那个太简单了,按照自己这几天学习的内容,打算对其进行修改
修改想法如下:
增加其他信息,如:作者,分类,说明等
总本书从网站直接提取,而不是自己输入
存储数据
想的容易做得难啊,果然没有实操,一些代码总以为这样就能操作,结果一直报错
然后我这份代码爬取量少,并没有设置错误判断等,还有直接修改原代码,我需要什么就写什么,没有考虑全局什么的,所以可能有点冗余
修改后代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67import urllib.request
from bs4 import BeautifulSoup
import time
import csv
num = 0 #用来计数,计算爬取的书一共有多少本
start_time = time.time() #计算爬虫爬取过程时间
#第一页网页网址https://read.douban.com/columns/category/all?sort=hot&start=0
#第二页网页网址https://read.douban.com/columns/category/all?sort=hot&start=10
#第三页网页网址https://read.douban.com/columns/category/all?sort=hot&start=20
#......发现规律了吗
url = 'https://read.douban.com/columns/category/all?sort=hot&start='
#为各个数据创建列表
node_lists = []
authors = []
categorys = []
infos = []
number = []
html = urllib.request.urlopen('https://read.douban.com/columns/category/all?sort=hot&start=0')
bsObj0 = BeautifulSoup(html,'lxml')
cate_name = bsObj0.find("span",{"class":"cate-count"}).get_text()
for i in range(0,int(cate_name),10): #这里的 range(初始,结束,间隔)
#urllib.request库用来向该网服务器发送请求,请求打开该网址链接
html = urllib.request.urlopen('https://read.douban.com/columns/category/all?sort=hot&start=%d' % i)
#BeautifulSoup库解析获得的网页,第二个参数一定记住要写上‘lxml’,记住就行
bsObj = BeautifulSoup(html,'lxml')
print('==============' + '第%d页'%(i/10 + 1) + '==============')
#分析网页发现,每页有10本书,而<h4>标签正好只有10个。
h4_node_list = bsObj.find_all('h4') # 这里返回的是h4标签的list列表
div_authors = bsObj.find_all("div",{"class":"author"})
div_categorys =bsObj.find_all("div",{"class":"category"})
div_infos = bsObj.find_all("div",{"class":"update-info icon-cal"})
#提取要的文本
for div_author in div_authors:
authors.append(div_author.get_text()[2:])
for div_category in div_categorys:
category = div_category.get_text()[2:]
categorys.append(category[:2])
for div_info in div_infos:
infos.append(div_info.get_text())
for h4_node in h4_node_list: #遍历列表
#获取h4标签内的a标签,但这里返回是只含1个元素的list
a_node = h4_node.contents[0]
title = a_node.contents[0] #因为是列表,要list[0],取出来
node_lists.append(title)
#title = '<<' + title + '>>'
print('第%d本书'%(num+1), title)
num = num + 1
number.append(num)
#设置抓数据停顿时间为1秒,防止过于频繁访问该网站,被封
time.sleep(1)
end_time = time.time()
duration_time = end_time - start_time
print('运行时间共:%.2f' % duration_time + '秒')
print('共抓到%d本书名'%num)
print('正在写入csv')
with open('so1n.csv', 'w') as f:
f_csv = csv.writer(f)
f_csv.writerow(('标题', '作者', '分类', '信息'))
for n in number:
f_csv.writerow((node_lists.pop(0),authors.pop(0),categorys.pop(0),infos.pop(0)))3.更改部分说明
提取数据
一开始觉得文中提取的方法挺本的,然后我就想换个法子提取数据,正则不太会用,感觉跟BS4结合需要很多代码(要去恶补正则了),最后发现直接get_text()就好了,而且是列表,直接切片提取, So Easy!
还想着用BS4的各种父代/子代/兄弟标签去提取,发现有点难用,而且不成功。。。索性就改为for了直接获取书的数目
原来哪里写着1650,然后我看了全部书是1979就加了几行代码获取总书数在弄进for循环了,不管套用原来的代码后觉得重复了- -存储数据
这部分就纠结最久的了。。。都怪自己平时只看书和COPY,自己想写个存储数据饶了一堆路
用了最简单的把数据写入列表里面然后用for循环给取出来并一起存入到.csv文件
一开始用了切片提取,结果打开文档后发现存入的数据是这样的 [‘书名’]
然后就想换个法子,
首先想到的是用strip()的方法,结果报错,list不能使用,我平时居然不知道- -惭愧
后来就用了pop() [我居然忘记了-。-]
完美解决,数据入库结果
 enter description here
enter description here enter description here
enter description here
4.简单的数据分析
我现在选择的是BDP这个网站
还有百度的echarts、tableau(这两个还没用过)
BDP有新手上手教程可以观看一下
- 首先在左上角的工作表中上传自己刚保存的数据,我这个表是选择逗号分割
- 然后点击左上角的仪表盘创建一下自己的仪表盘并把自己上传的工作表打开
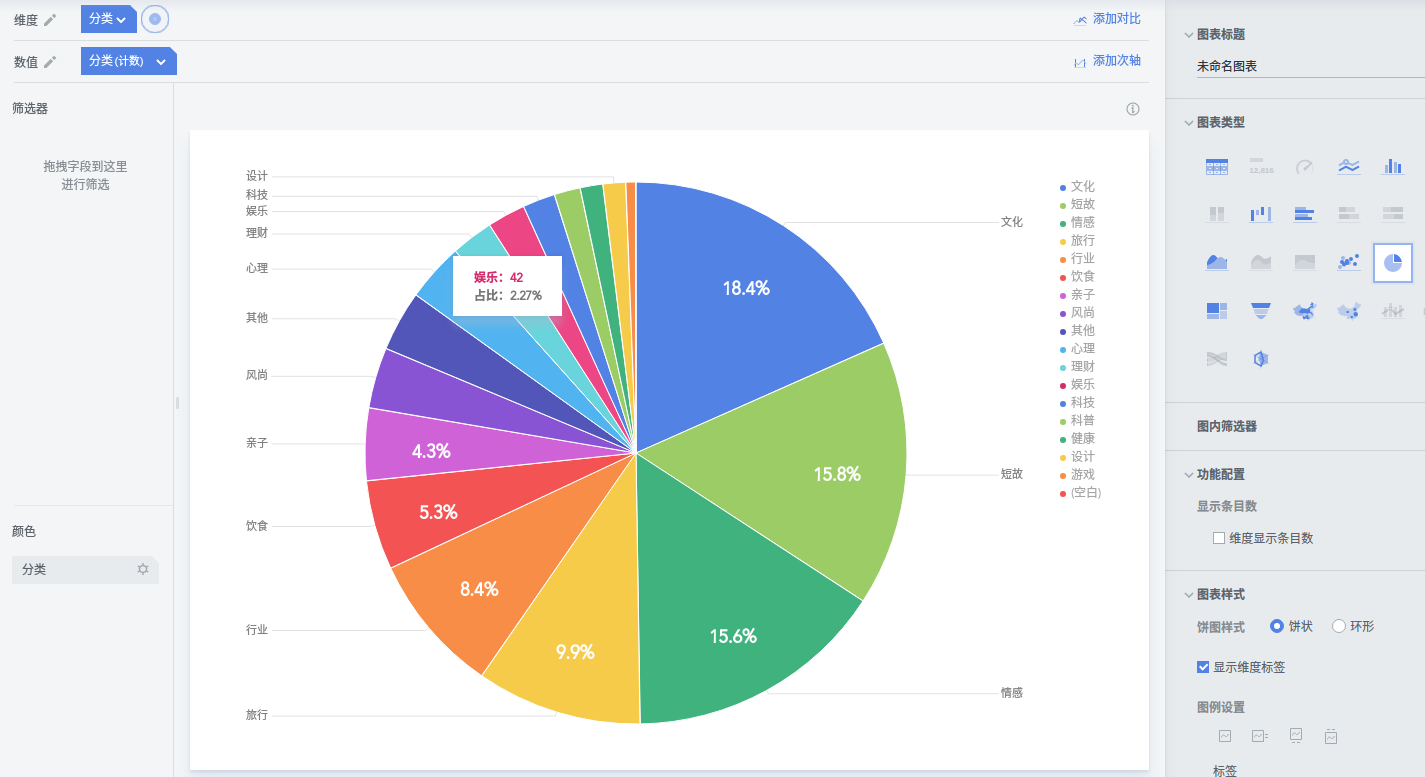
- 进入后维度选择分类,数值也选择分类,再选圆饼就可以看出如下数值
 enter description here
enter description here - 可以看出依次是文化、短故、情感占据1、 2、 3名,而且占了总量的一半
- 本文作者:So1n
- 本文链接:http://so1n.me/2017/07/25/3_spider_by_douban_resd/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

