Web框架的快速路由实现
前记
多功能的路由匹配是PythonWeb框架的一个特色,从Django,Flask框架开始,他们的路由匹配功能就非常丰富,它们基本上都允许Host匹配,重定向匹配以及其他正则匹配等使得用户可以添加他们大部分想要的路由规则,但也增加了路由匹配模块的复杂性和增加了路由匹配的时间消耗。
1.Web框架高性能的秘密
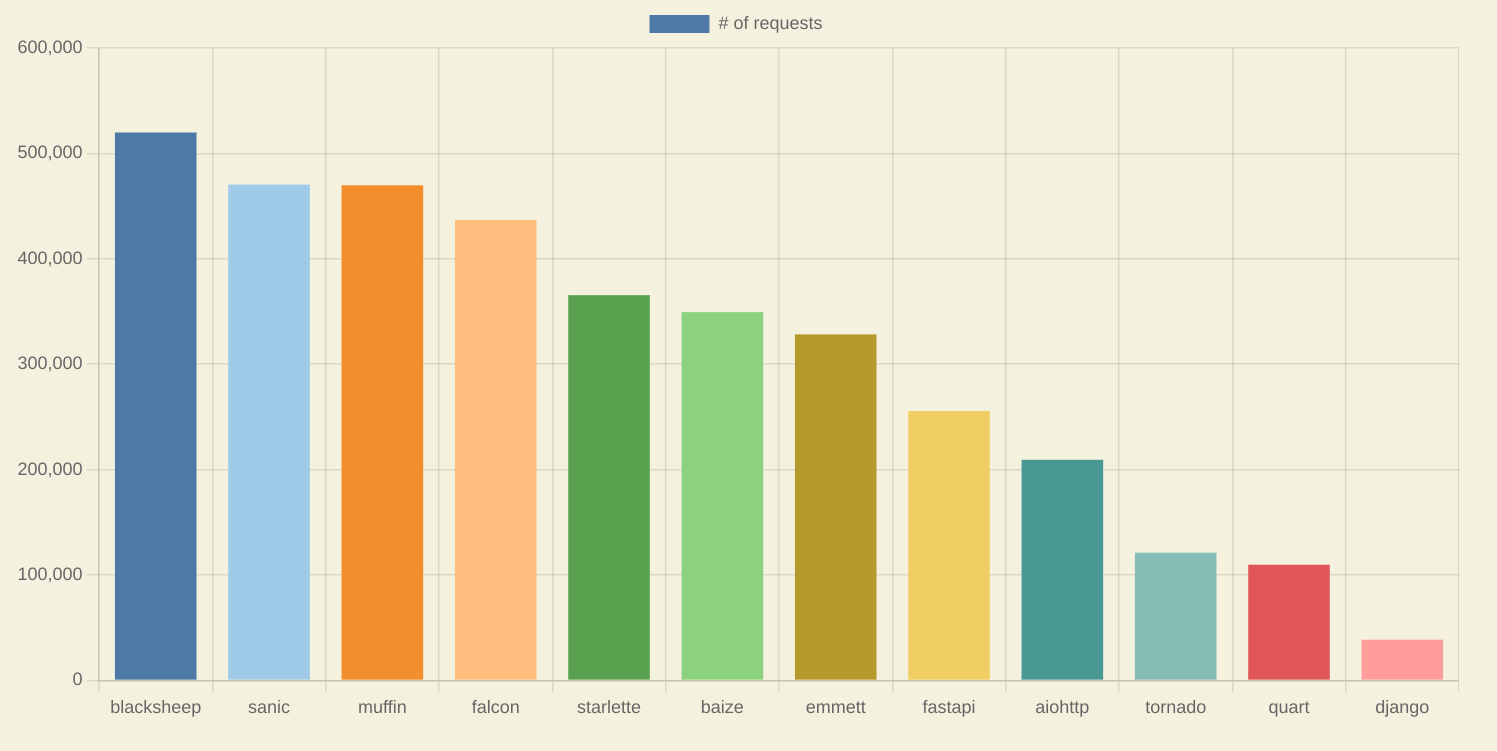
目前Python Asyncio的Web框架百花齐放,每个框架都有自己的特色,但是它们的基础功能基本上都是相同的,但是由于它们在部分功能模块的实现有些不同,导致他们的性能表现各不相同,下图是py-frameworks-bench提供的压测结果:
 16879623297911687962328974.png
16879623297911687962328974.png
通过压测结果可以把框架分类成三部分,第一部分是Django, Quart, tornado, Aiohttp这类比较老的框架,它们的压测结果都比较差,第二部分是Starlette和Emmett,它们的压测结果处于中等水平,而Blacsheep,Sanic这类框架的压测结果都是很高的。
在粗略的查看了他们的源码和设计说明后可以总结出他们性能差异的原因:
- 1.对于老式框架
tornado,aiohttp,他们并不支持ASGI,导致无法使用uvicorn等ASGI服务器,从而要自己去实现HTTP协议解析,而他们的HTTP协议解析是纯Python实现的,解析性能不如C实现的HTTP解析器强。 - 2.对于新式框架,他们的部分组件使用了
Cython去编写,从而使这些组件获得了C一样的性能。 - 3.新式框架不再使用传统的路由匹配,而是改用路由树或者通过AST路由。
如果再把上面的描述进一步提炼,就可以发现,目前的Web框架性能差异主要是在协议解析,路由匹配两个大模块上,其中协议解析是与使用的协议绑定的,所以针对HTTP的WEB框架再怎么改动都很难有提升,而路由匹配关心的是如何根据一个URL找到对应的路由,可定制性大。
2.复杂的路由匹配
一般来说只要创建一个字典,然后把Url和路由绑定就可以完成一个速度极快又非常简单的路由匹配功能了,如下:
1 | |
这种方式实现的路由匹配速度是非常快的(算法复杂度O(1)),但是在遇到不同的用户通过/api/user/123和/api/user/345等多个Url需要匹配同一个路由时,这个设计就有问题了,毕竟一个系统的用户数会很多,把它们对应的URL装进字典里并不是一件很实际的事,所以就需要通过另一种方案来实现路由匹配,如下:
1 | |
这种方案是把路由表从哈希字典改成一个数组,同时URL不再被规定为字符串,它也可以是正则表达式,然后在进行路由匹配时,就会遍历每个定义URL,如果发现访问的URL与定义的URL相等或者符合定义的URL正则表达式,那么就意味着匹配成功,这样一来只需要在路由表编写/api/user/<user_id>的映射关系就可以满足/api/user/123,/api/user/345等URL,路由表映射编写的便利性提升到了质的飞跃。
除了包含正则表达式的URL外,还有一些比较特殊的匹配需求,如域名匹配,简单的域名匹配路由表如下:
1 | |
在这种方案的路由表多了一个元素–域名,通过增加域名这个元素使其在路由匹配时会先检验当前的域名是否匹配,如果域名匹配成功了才会再去匹配第二项的路由URL,当域名和URL都完全匹配时才会去访问对应的路由。
比如http://example.com/api/manager会匹配到manager_route_1路由,而http://www.example.com/api/manager会匹配到manager_route_2路由。
这里只做简单演示,实际上在使用时不会通过添加多一个元素来满足多一种条件的方式,具体可以通过
werkzeug的routing源码了解。
到现在位置,可以发现循环遍历匹配路由的实现非常简单,同时拓展起来也非常方便,这也就是Django,Flask,Starlette等流行的框架会采用遍历的方法来实现路由匹配的原因,但是随着而来的是路由匹配的算法复杂度从O(1)变为O(n),这也意味着后面添加的路由被匹配的效率是很低的。
为了解决路由数组循环匹配的性能以及哈希匹配的拓展性都比较差的情况,很多人都在研究其他的路由匹配方法,比较出名的有路由前缀树和AST路由两种方案,在Falcon Routing Surver中就测出了几种不同路由实现的性能,如下(其中省去几行不是关键的输出):
1 | |
通过输出结果可以发现AST路由的速度是最快的,是路由数组的8倍,而路由前缀树方案的速度是路由数组的4倍。
不过,在AST路由和路由前缀树方案都带来了性能的提升同时,它们支持的路由匹配功能却少了一些。
3.路由前缀树
在制订URL的时候往往都是以/来划分层级的,比如下面的URL:
1 | |
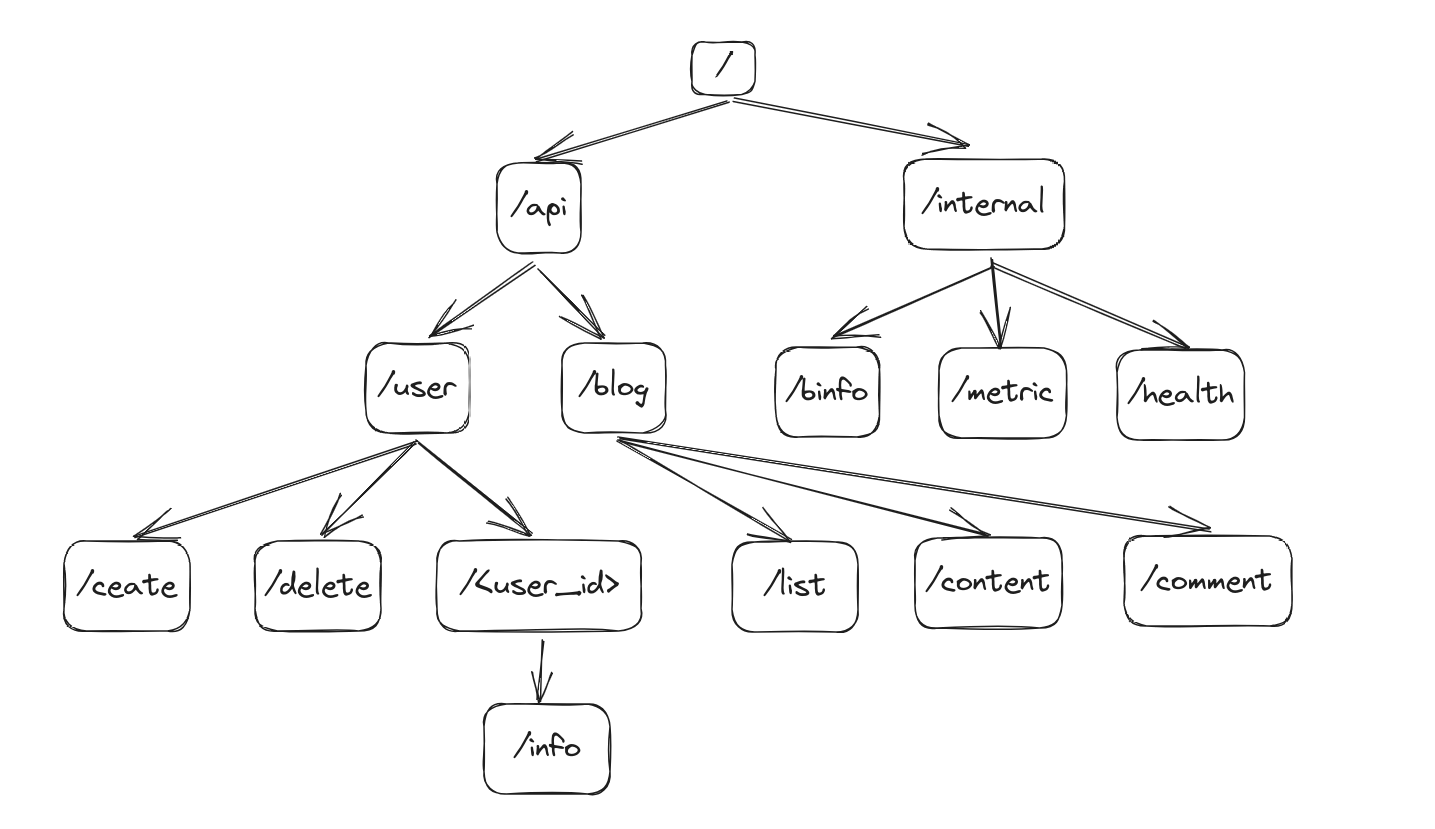
通过观察可以发现他们拥有共同的前缀,按照前缀的不同可以分为业务组–/api/xxx和内部接口组–/internal/xxx,而业务组可以细分用户组–xxx/user/xxx,博客组–xxx/blog/xxx。
现在就换个角度观察它们,先按/把URL切分成多个字符串,如/api/user/create可以被切分为api,user,create三个字符串,然后把他们按顺序排列并去掉重复的前缀,结果如下:
1 | |
然后再根据这个结果创建路由树,首先是创建/节点,然后按顺序把他们与上层节点连上,这样就形成一颗路由树了,如图:16880456728751688045672080.png
通过图可以发现路由树的构造与经典的数据结构前缀树类似,只不过前缀树是以每个字母为节点,而路由树是以/为根节点,并通过/切分URL形成多个子path,这些子path都为子节点。
了解前缀树的话会知道前缀树的一个优点是内存占用和查找性能都介于数组和哈希字典的中间,也就是不浪费空间占用,查找的复杂度也不是O(n),比如在查找/api/user/create时,会先命中/api节点,然后再命中/user节点,最后再命中create节点,这个过程虽然会进行三次哈希查找,但是他的时间复杂度只能算是O(k) (k为树的层级),远优于遍历队列查找的O(n)。
3.1.路由前缀树的实现
了解了路由前缀树的原理后就可以着手实现路由前缀树了,路由前缀树的实现有很多种,这里演示的路由前缀树实现了最简单的路由匹配功能,同时它还支持与拥有正则的URL(只支持一个变量)绑定。
路由前缀树整个实现有三部分,首先是定义一个模拟路由,通过拓展它可以挂载路由函数,但这里这是一个简单的实现,所以只需要传入一个属性–url,代码如下:
1 | |
然后在构造路由前缀树之前,需要构造路由前缀树的节点,该节点会以字典来存储子节点与自己的关系,同时为了支持类似/api/user/<user_id>/info带有正则的URL,节点需要存储对应的路由列表,同时存储当前正则表达式的变量名,代码如下:
1 | |
接着就可以实现路由前缀树了,一个简单的路由前缀树会有一个根节点,然后还拥有构造路由前缀树和通过路由前缀树查询的功能,如下:
1 | |
这样一来,简单的路由前缀树就实现完成了,运行如下代码验证路由树是否正常实现,通过输出后可以发现路由前缀树能够正常的匹配到路由,同时也支持带有正则URL的变量生成:
1 | |
路由树的查找速度会比路由数组的快,但是在实现支持包含正则的URL功能时,会发现路由–Route,路由树节点–RouteNode,路由树–RouteTrie这三点都需要进行改造,导致路由前缀树的开发成本比路由数组高。
如果对路由树有兴趣,可以参考一些比较好的实现:
4.AST路由
AST路由是一种粗暴的解决方案,它在添加路由的时候也是构造一颗路由树,并在构造完路由树后遍历路由树并通过Python的动态能力有规则的生成含有大量IF语句的路由匹配代码,虽然生成的路由匹配代码比较丑,但是由于只含有IF逻辑,AST路由的匹配性能出奇的高。
性能高的原因主要有两点:
- 1.由于有规则的生成匹配逻辑,CPU在遇到IF时进行分支预测的准确性会大大提高,匹配的速度也得到提高,详见当 CPU 遇上 if 语句
- 2.
Python的For语句性能比较差(相对于其他语言),而AST路由是唯一没有For语句的路由匹配方案。
AST路由的实现比较复杂,所以直接采用falcon-routing-survey的实现,如果有兴趣可以直接查看它的源码。
falcon-routing-survey封装的AST路由–CompiledTreeRoute的使用很简单,如下:
1 | |
代码中通过add_route向路由树绑定了URL和路由,然后使用find_responder通过URL寻找路由,可以看到它除了支持普通URL的路由匹配外,也支持含有正则的URL路由匹配,而负责路由匹配的逻辑代码则是在第一次调用find_responder时生成的,这次运行时生成的代码如下:
1 | |
可以看到生成的代码虽然很长,但逻辑也很简单,都是匹配path的长度以及path的某一项的值等于什么,
同时通过生成代码的缩进可以发现,代码中的IF逻辑可以分为几部分,每部分恰好与按照URL区分的组类似,比如api和internal都是处于第一层,而user,blog处于api的下一层。
虽然AST路由的性能很快,但是每次新增功能也需要大量的改动,同时他是通过各种逻辑判断后才生成的代码,所以代码的易读性并不会很好,在改动逻辑前可能需要把生成的代码打印出来才能理顺,不过路由匹配本来就是一个稳定的功能,对于追求极致性能的框架都会采用AST路由来提升自己的性能,比如Sanic和Falcon,如果对AST路由感兴趣,可以通过如下URL:
- https://github.com/sanic-org/sanic-routing/blob/main/sanic_routing/tree.py
- https://github.com/falconry/falcon/blob/master/falcon/routing/compiled.py
分别访问Sanic和Falcon的路由源码查看他们的实现。
5.总结
路由组匹配,路由前缀树,AST路由它们三者的性能与简单性成反比,
在查阅资料后发现采纳不同的路由匹配方式与Web框架诞生的时代有一定的相关性。
目前采用路由组匹配的Web框架都是在Web1.0时代诞生的,而且都在路由组匹配上实现了很多小众的功能;
采用路由前缀树的Web框架则大部分都是近10年内诞生的Web框架,他们的作者根据URL的特性实现了路由前缀树来提升路由匹配的功能,同时由于路由前缀树在各大语言的Web框架都有实现,大家互相借鉴推动了路由前缀树的功能迭代(如很多框架在使用路由前缀树时会新增路由组功能),这使路由前缀树成为了路由匹配中的六边形战士。
而采用AST路由的都是在Python等动态语言中,诞生的比较晚且勇于尝试新事物和追求高性能的框架。
附录
其他参考链接
Sanic从路由组匹配改为AST路由的讨论 https://community.sanicframework.org/t/a-fast-new-router/649/10Quart作者关于Werkzeug重新实现的路由描述 https://pgjones.dev/blog/faster-routing-2022/
- 本文作者:So1n
- 本文链接:http://so1n.me/2023/06/27/web_framwork-fast_route/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!

